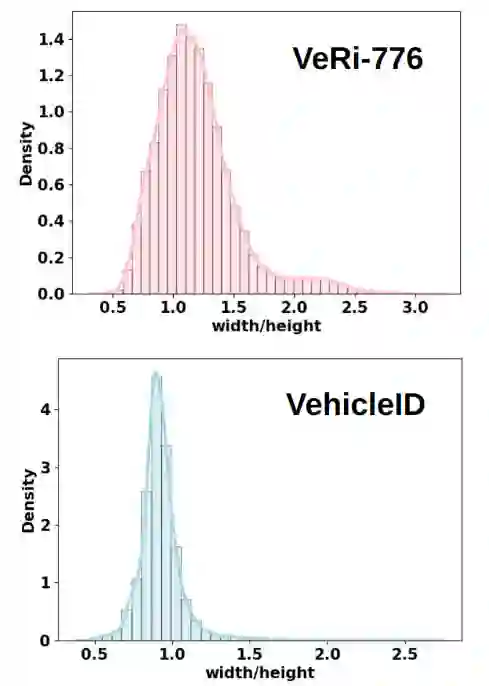
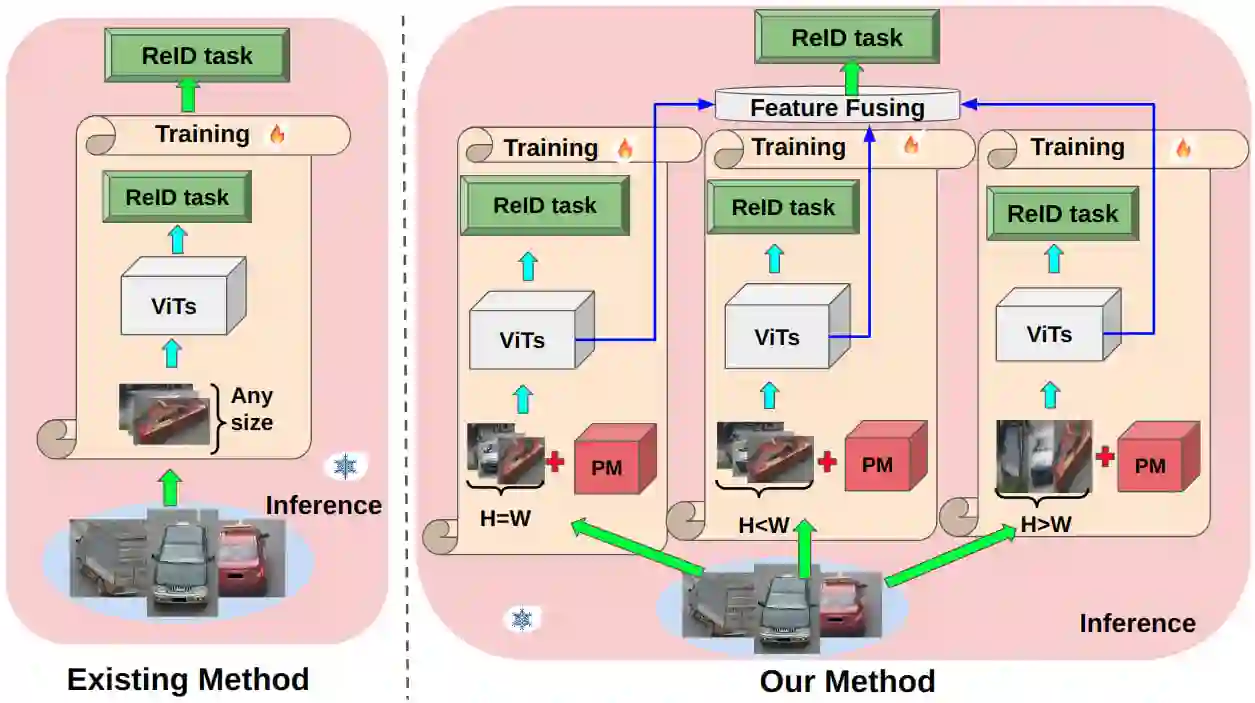
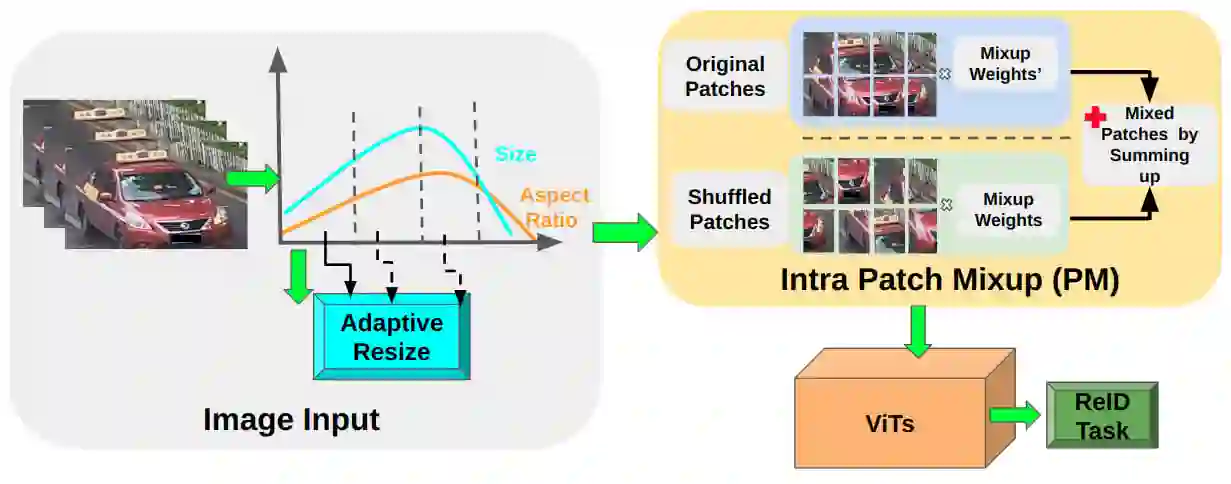
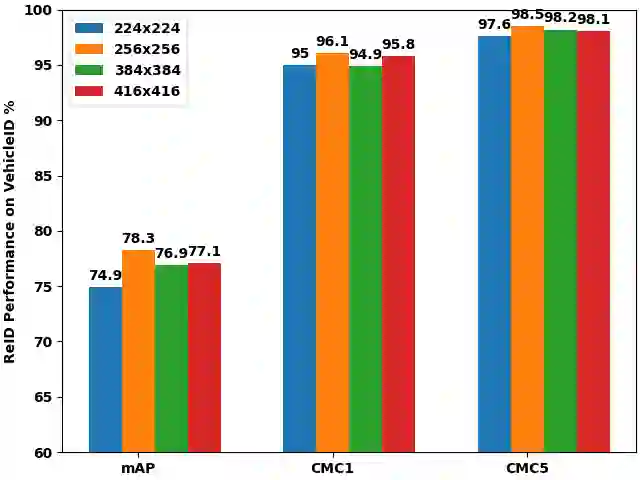
Vision Transformers (ViTs) have excelled in vehicle re-identification (ReID) tasks. However, non-square aspect ratios of image or video input might significantly affect the re-identification performance. To address this issue, we propose a novel ViT-based ReID framework in this paper, which fuses models trained on a variety of aspect ratios. Our main contributions are threefold: (i) We analyze aspect ratio performance on VeRi-776 and VehicleID datasets, guiding input settings based on aspect ratios of original images. (ii) We introduce patch-wise mixup intra-image during ViT patchification (guided by spatial attention scores) and implement uneven stride for better object aspect ratio matching. (iii) We propose a dynamic feature fusing ReID network, enhancing model robustness. Our ReID method achieves a significantly improved mean Average Precision (mAP) of 91.0\% compared to the the closest state-of-the-art (CAL) result of 80.9\% on VehicleID dataset.
翻译:视觉Transformer(ViT)在车辆重识别任务中表现出色。然而,图像或视频输入的非正方形长宽比可能显著影响重识别性能。为解决该问题,本文提出一种新颖的基于ViT的重识别框架,该框架融合了在不同长宽比数据上训练的模型。我们的主要贡献包括三方面:(i)在VeRi-776和VehicleID数据集上分析长宽比对性能的影响,基于原始图像长宽比指导输入设置;(ii)在ViT分块处理过程中引入基于空间注意力得分的块级图像内混合策略,并采用非均匀步长以实现更好的目标长宽比匹配;(iii)提出动态特征融合的重识别网络,增强模型鲁棒性。在VehicleID数据集上,我们的重识别方法实现了91.0%的平均精度均值(mAP),较当前最先进方法(CAL)的80.9%有显著提升。