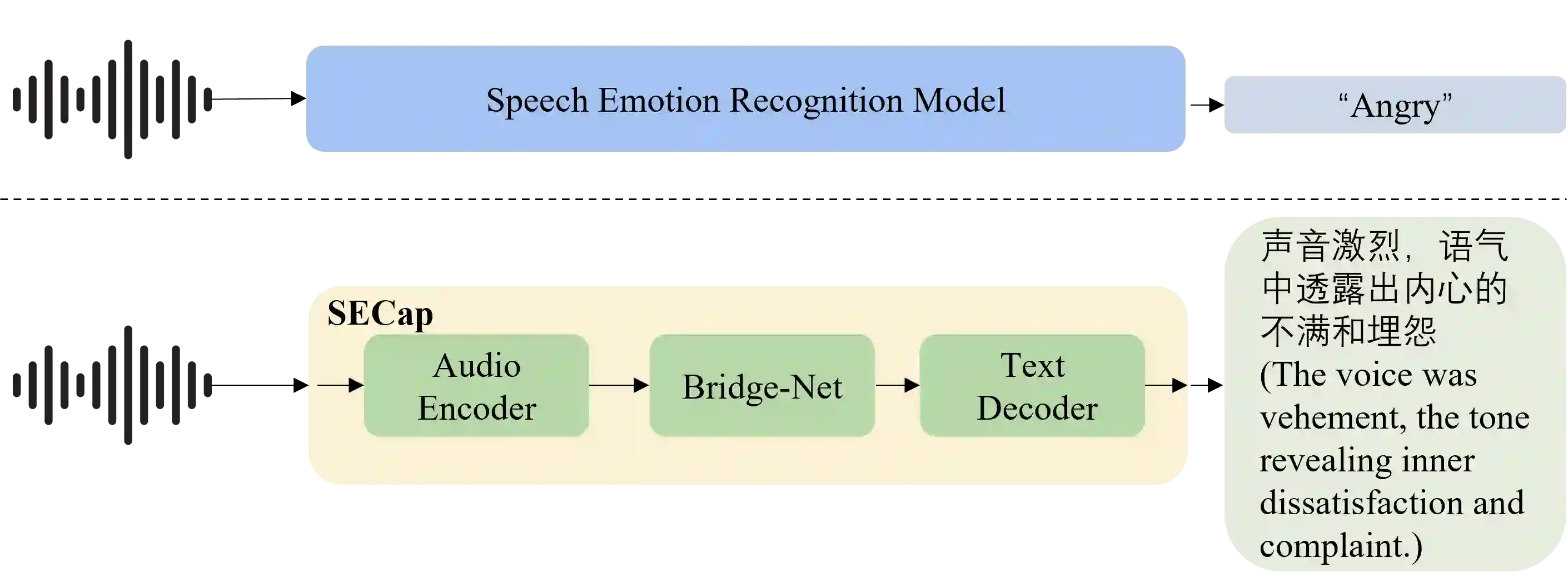
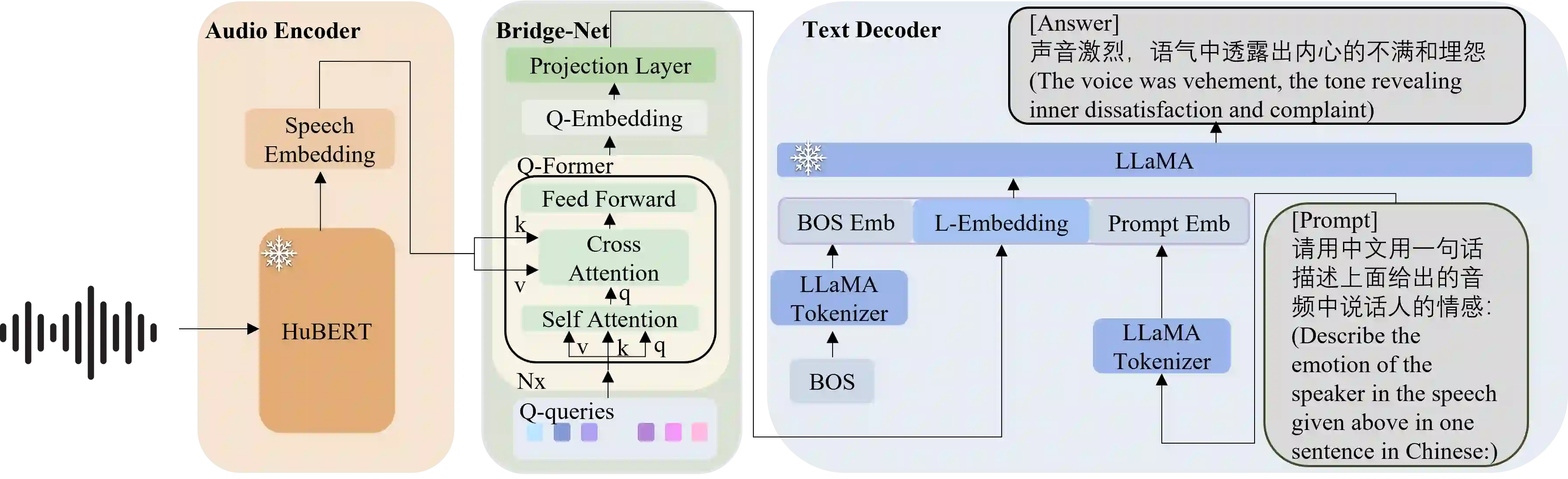
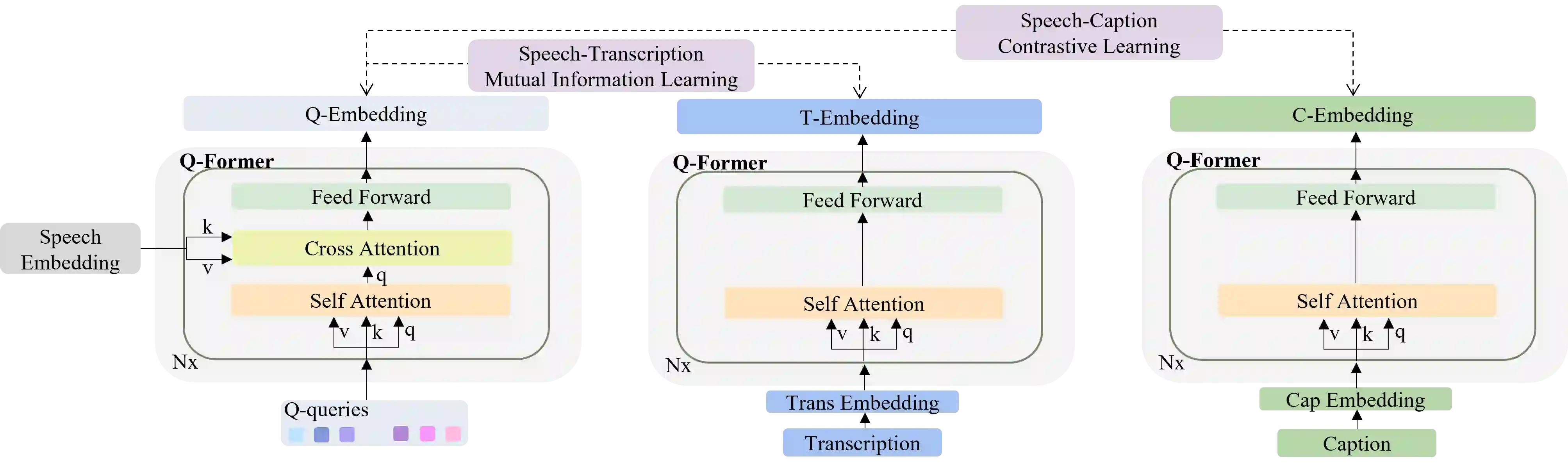
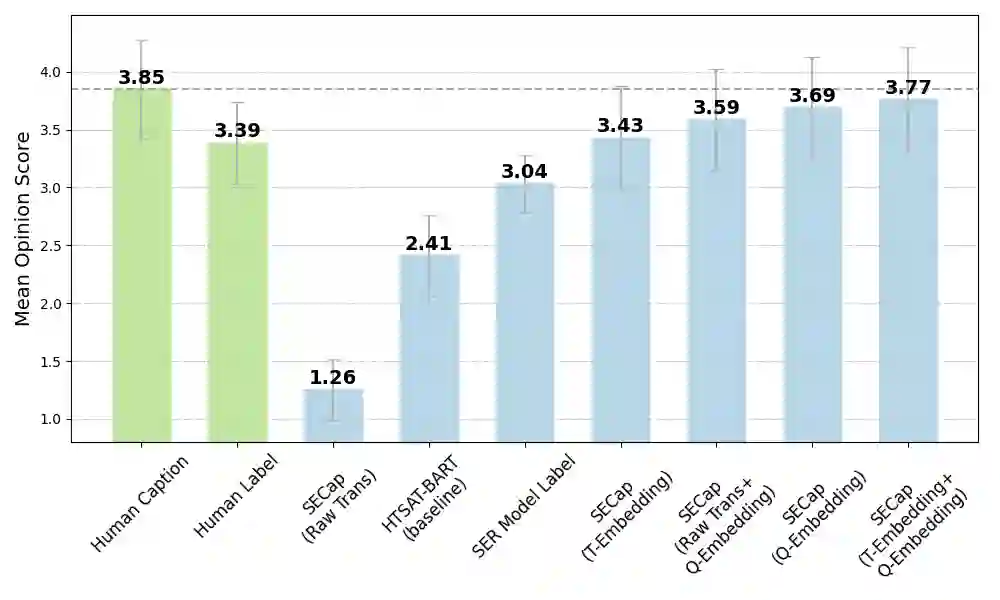
Speech emotions are crucial in human communication and are extensively used in fields like speech synthesis and natural language understanding. Most prior studies, such as speech emotion recognition, have categorized speech emotions into a fixed set of classes. Yet, emotions expressed in human speech are often complex, and categorizing them into predefined groups can be insufficient to adequately represent speech emotions. On the contrary, describing speech emotions directly by means of natural language may be a more effective approach. Regrettably, there are not many studies available that have focused on this direction. Therefore, this paper proposes a speech emotion captioning framework named SECap, aiming at effectively describing speech emotions using natural language. Owing to the impressive capabilities of large language models in language comprehension and text generation, SECap employs LLaMA as the text decoder to allow the production of coherent speech emotion captions. In addition, SECap leverages HuBERT as the audio encoder to extract general speech features and Q-Former as the Bridge-Net to provide LLaMA with emotion-related speech features. To accomplish this, Q-Former utilizes mutual information learning to disentangle emotion-related speech features and speech contents, while implementing contrastive learning to extract more emotion-related speech features. The results of objective and subjective evaluations demonstrate that: 1) the SECap framework outperforms the HTSAT-BART baseline in all objective evaluations; 2) SECap can generate high-quality speech emotion captions that attain performance on par with human annotators in subjective mean opinion score tests.
翻译:语音情感在人类交流中至关重要,并广泛用于语音合成和自然语言理解等领域。以往大多数研究(如语音情感识别)将语音情感归为固定类别。然而,人类语音中表达的情感往往复杂多样,将其划分为预定义类别可能不足以充分代表语音情感。相反,通过自然语言直接描述语音情感或许是更有效的方法。遗憾的是,目前专注于该方向的研究尚不充分。为此,本文提出名为SECap的语音情感描述框架,旨在利用自然语言有效描述语音情感。鉴于大语言模型在语言理解和文本生成方面的卓越能力,SECap采用LLaMA作为文本解码器以生成连贯的语音情感描述。此外,SECap利用HuBERT作为音频编码器提取通用语音特征,并采用Q-Former作为桥接网络向LLaMA提供情感相关语音特征。为实现这一目标,Q-Former通过互信息学习分离情感相关语音特征与语音内容,同时采用对比学习提取更多情感相关语音特征。客观与主观评估结果表明:(1)SECap框架在所有客观评估指标上均优于HTSAT-BART基线;(2)SECap能生成高质量语音情感描述,在主观平均意见分测试中达到与人工标注者相当的性能。