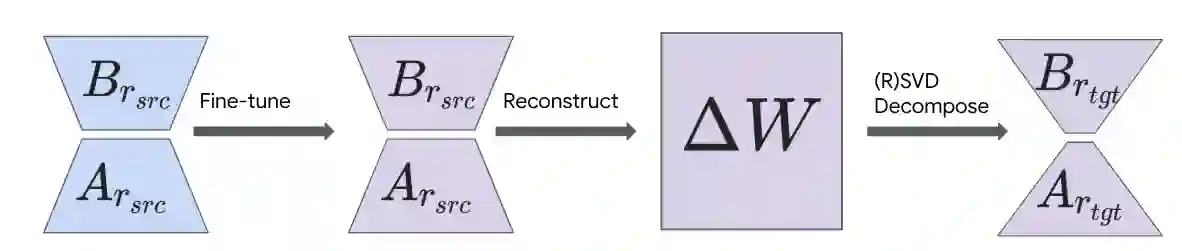
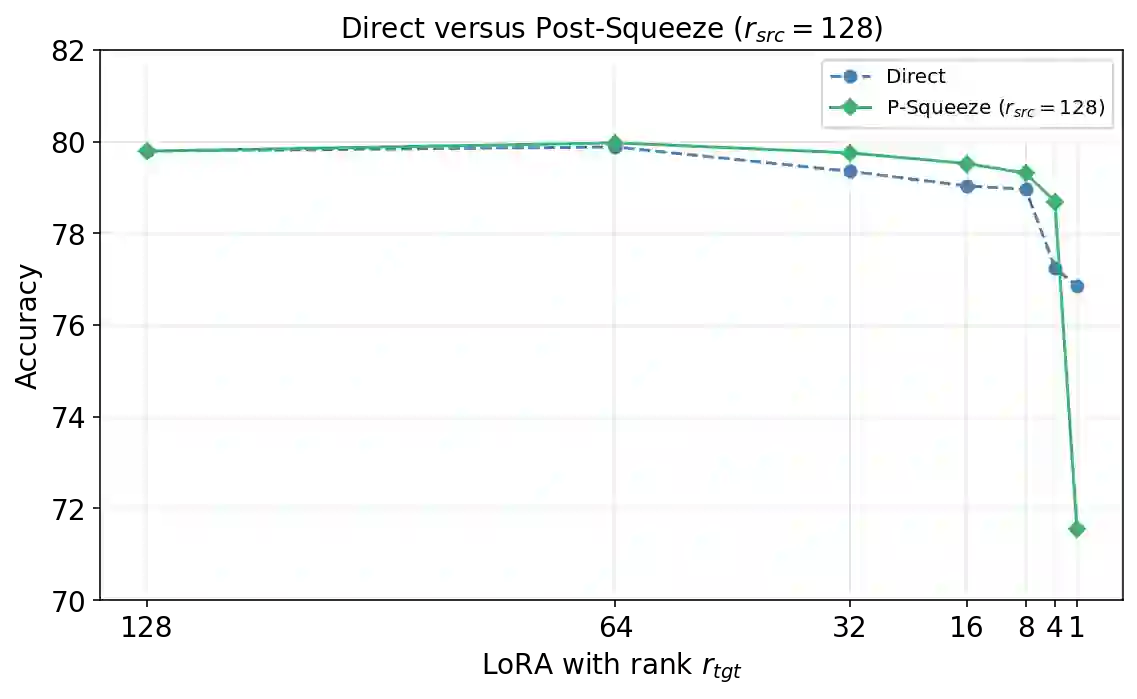
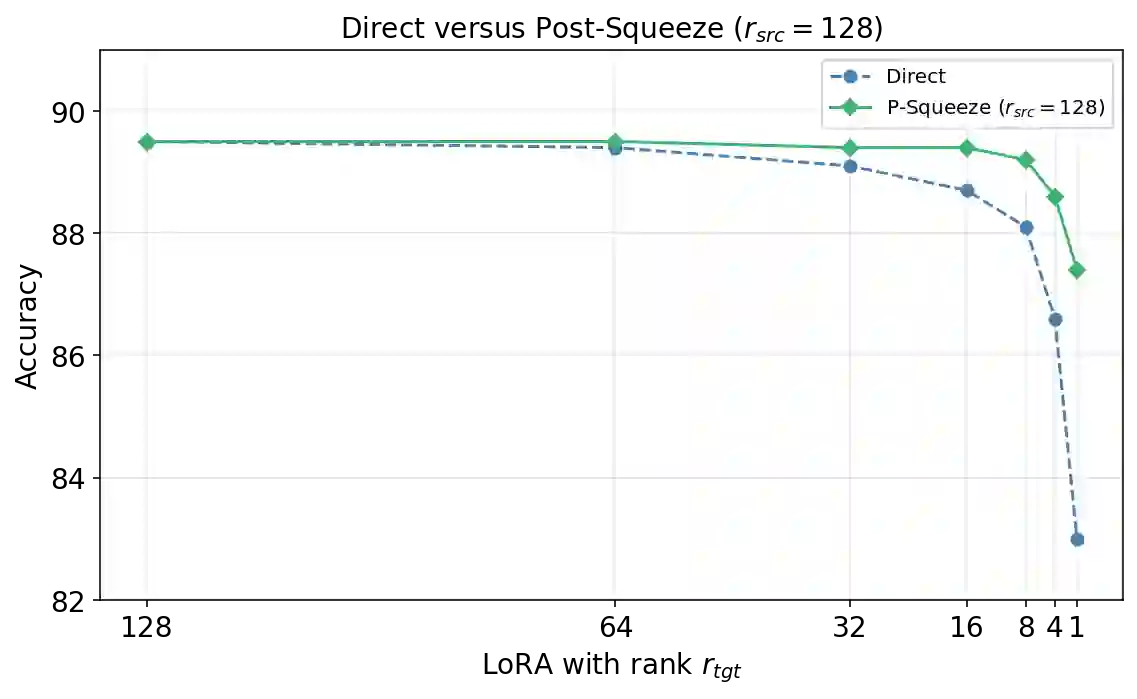
Despite its huge number of variants, standard Low-Rank Adaptation (LoRA) is still a dominant technique for parameter-efficient fine-tuning (PEFT). Nonetheless, it faces persistent challenges, including the pre-selection of an optimal rank and rank-specific hyper-parameters, as well as the deployment complexity of heterogeneous-rank modules and more sophisticated LoRA derivatives. In this work, we introduce LoRA-Squeeze, a simple and efficient methodology that aims to improve standard LoRA learning by changing LoRA module ranks either post-hoc or dynamically during training}. Our approach posits that it is better to first learn an expressive, higher-rank solution and then compress it, rather than learning a constrained, low-rank solution directly. The method involves fine-tuning with a deliberately high(er) source rank, reconstructing or efficiently approximating the reconstruction of the full weight update matrix, and then using Randomized Singular Value Decomposition (RSVD) to create a new, compressed LoRA module at a lower target rank. Extensive experiments across 13 text and 10 vision-language tasks show that post-hoc compression often produces lower-rank adapters that outperform those trained directly at the target rank, especially if a small number of fine-tuning steps at the target rank is allowed. Moreover, a gradual, in-tuning rank annealing variant of LoRA-Squeeze consistently achieves the best LoRA size-performance trade-off.
翻译:尽管存在大量变体,标准的低秩适应(LoRA)仍然是参数高效微调(PEFT)的主导技术。然而,它仍面临持续存在的挑战,包括最优秩和秩特定超参数的事前选择,以及异构秩模块和更复杂LoRA衍生模型的部署复杂性。本文提出LoRA-Squeeze,这是一种简单高效的方法论,旨在通过后验或在训练期间动态调整LoRA模块的秩来改进标准LoRA学习。我们的方法主张:首先学习一个表达能力更强的高秩解,然后对其进行压缩,优于直接学习受约束的低秩解。该方法包括使用刻意设定的高(较高)源秩进行微调,重构或高效近似重构完整的权重更新矩阵,然后利用随机奇异值分解(RSVD)创建一个新的、压缩至更低目标秩的LoRA模块。在13项文本任务和10项视觉语言任务上的大量实验表明,后验压缩通常能产生比直接在目标秩上训练效果更优的低秩适配器,特别是在允许进行少量目标秩微调步骤的情况下。此外,LoRA-Squeeze的渐进式动态秩退火变体始终能实现最佳的LoRA规模-性能权衡。