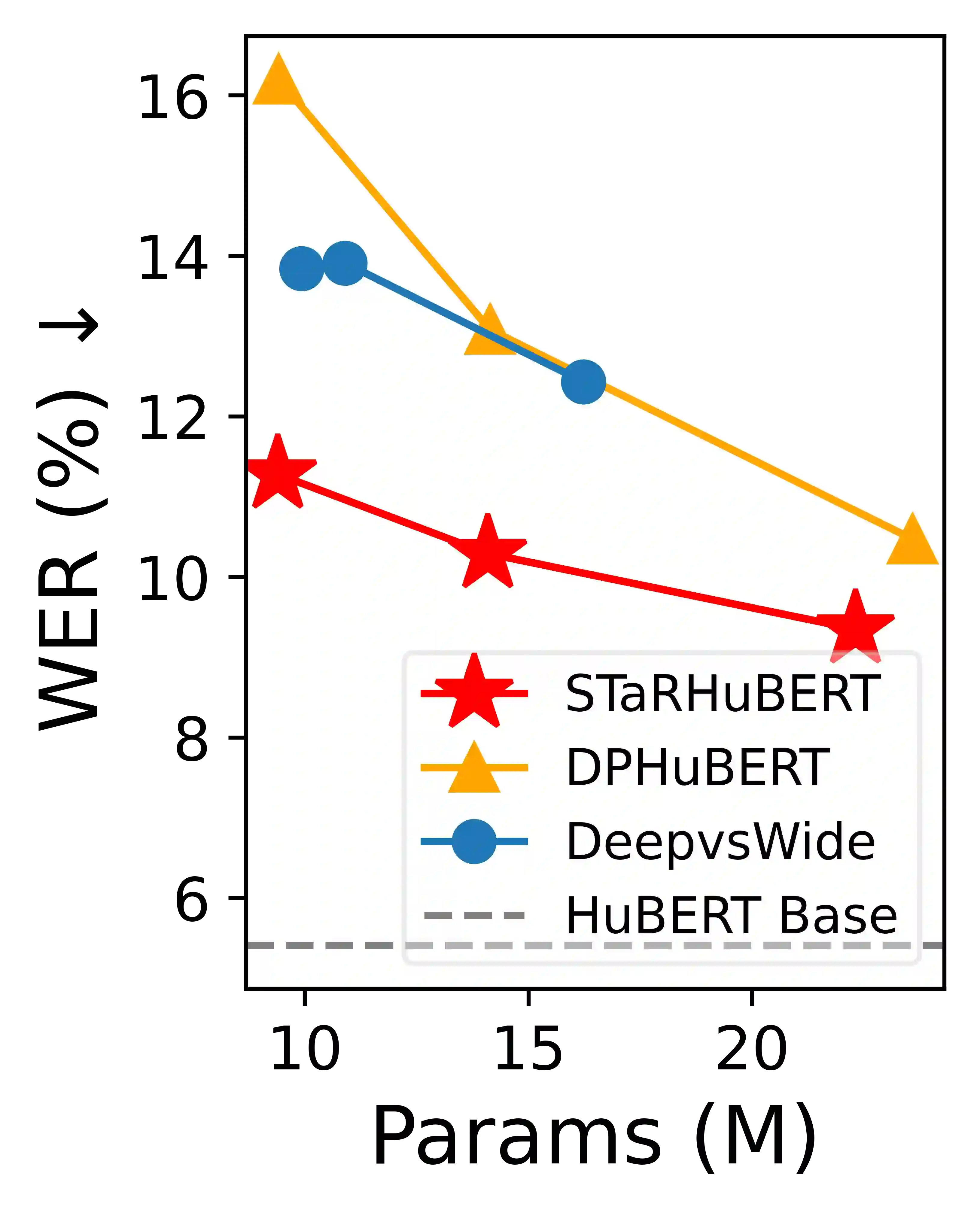
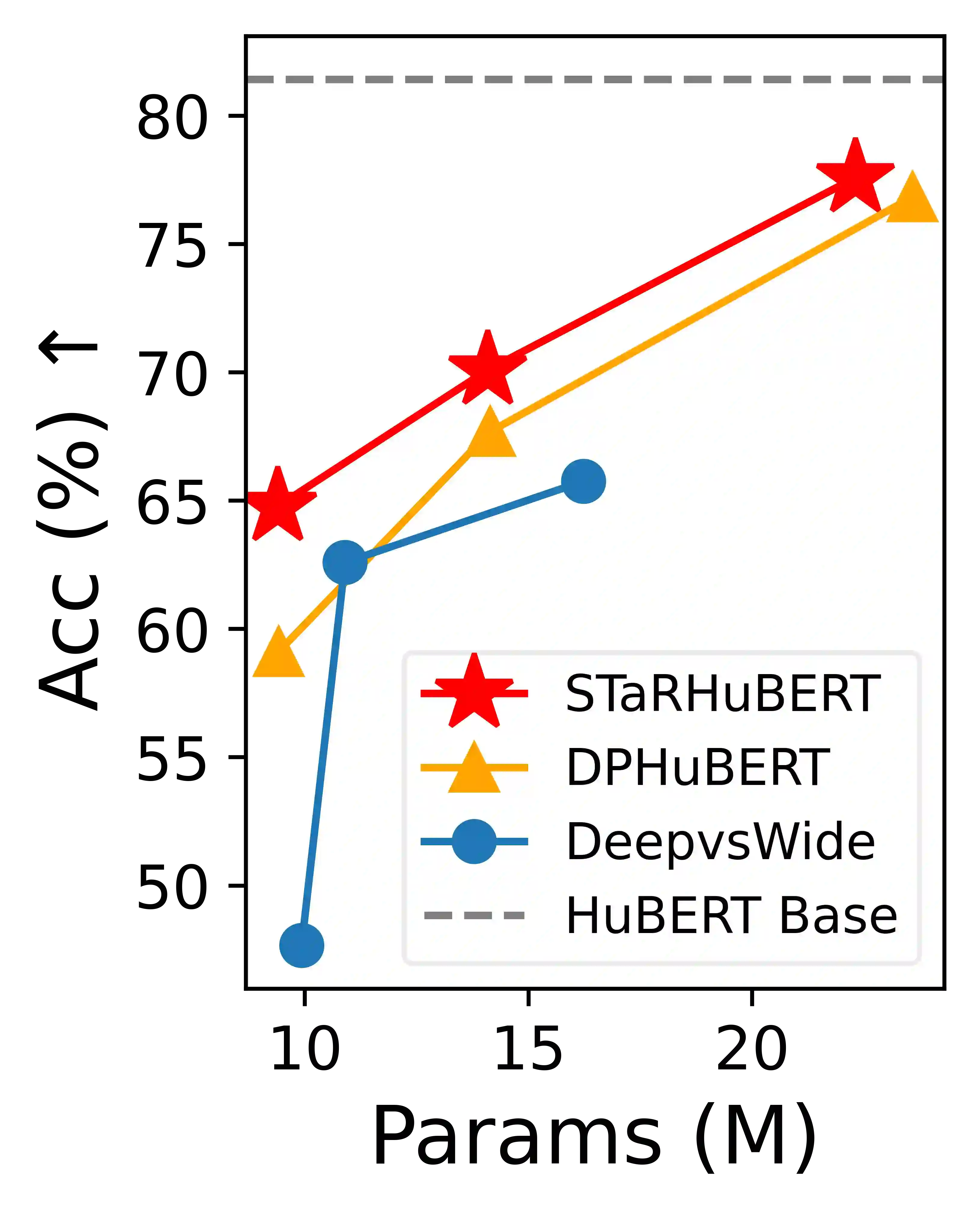
Albeit great performance of Transformer-based speech selfsupervised learning (SSL) models, their large parameter size and computational cost make them unfavorable to utilize. In this study, we propose to compress the speech SSL models by distilling speech temporal relation (STaR). Unlike previous works that directly match the representation for each speech frame, STaR distillation transfers temporal relation between speech frames, which is more suitable for lightweight student with limited capacity. We explore three STaR distillation objectives and select the best combination as the final STaR loss. Our model distilled from HuBERT BASE achieves an overall score of 79.8 on SUPERB benchmark, the best performance among models with up to 27 million parameters. We show that our method is applicable across different speech SSL models and maintains robust performance with further reduced parameters.
翻译:尽管基于Transformer的语音自监督学习(SSL)模型性能卓越,但其庞大的参数量和计算成本限制了实际应用。本研究提出通过蒸馏语音时序关系(STaR)来压缩语音SSL模型。不同于以往直接匹配各语音帧表示的方法,STaR蒸馏传递语音帧间的时序关系,更适用于容量有限的轻量级学生模型。我们探索了三种STaR蒸馏目标函数,并选择最优组合作为最终STaR损失函数。从HuBERT BASE蒸馏得到的模型在SUPERB基准测试中获得79.8的综合得分,这是参数量不超过2700万模型中的最佳性能。实验表明,本方法可适用于不同语音SSL模型,且在进一步压缩参数时仍保持鲁棒性能。