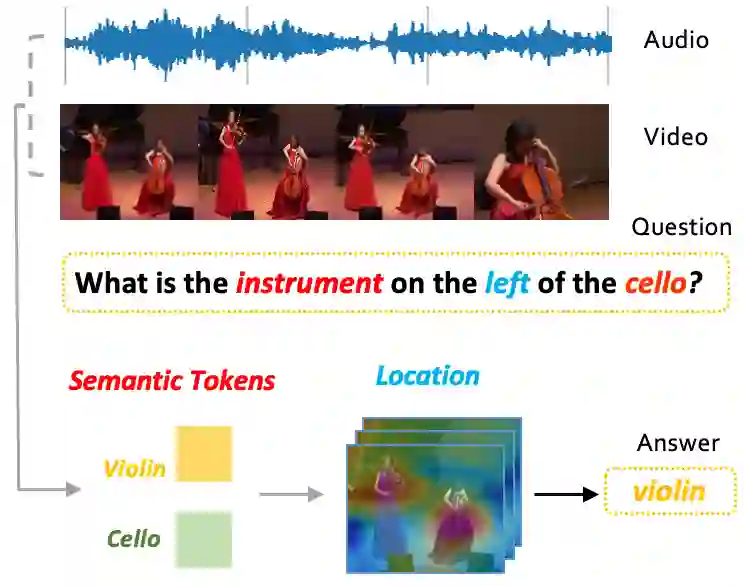
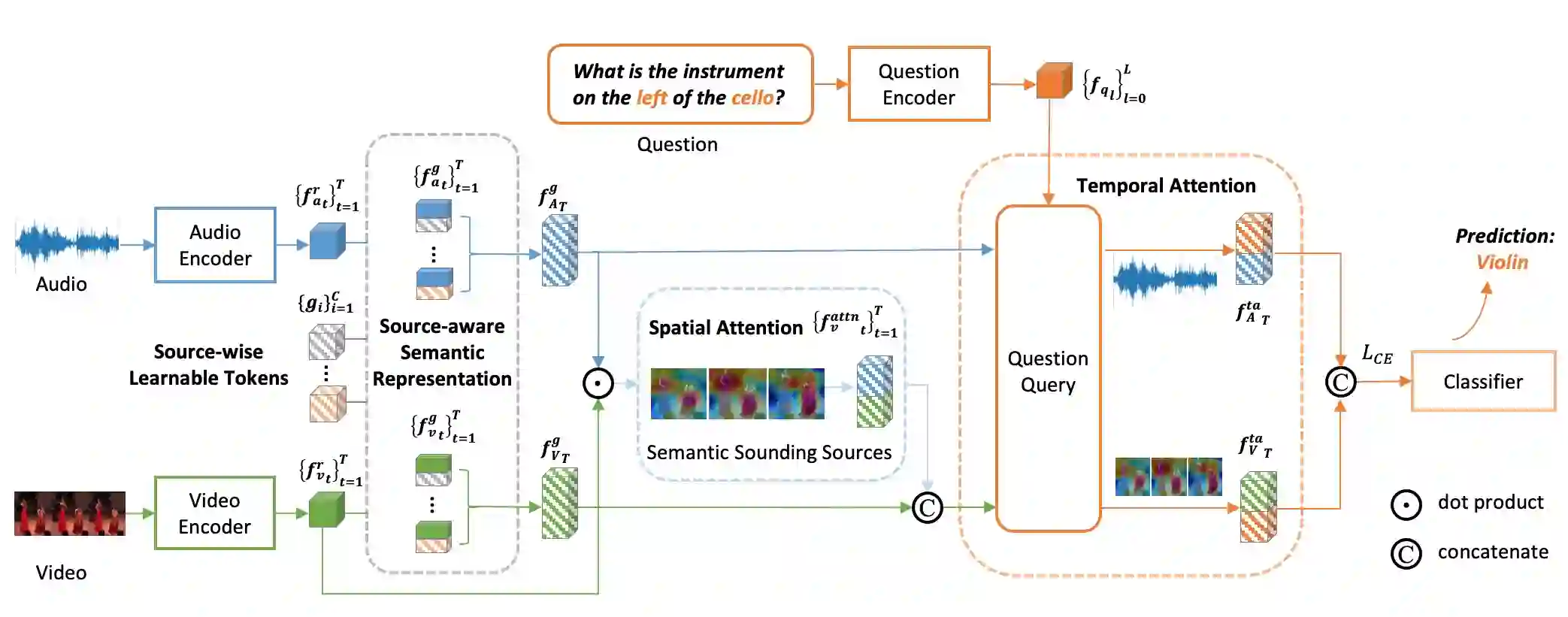
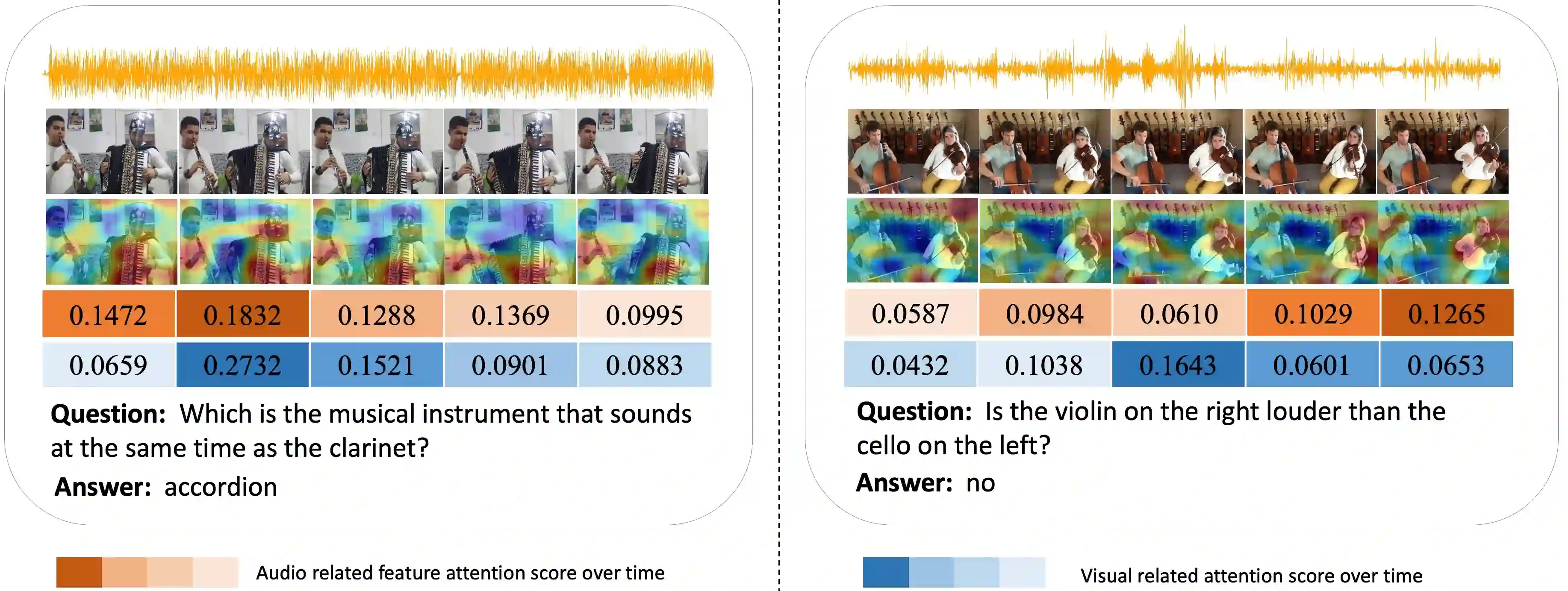
Audio-Visual Question Answering (AVQA) is a challenging task that involves answering questions based on both auditory and visual information in videos. A significant challenge is interpreting complex multi-modal scenes, which include both visual objects and sound sources, and connecting them to the given question. In this paper, we introduce the Source-aware Semantic Representation Network (SaSR-Net), a novel model designed for AVQA. SaSR-Net utilizes source-wise learnable tokens to efficiently capture and align audio-visual elements with the corresponding question. It streamlines the fusion of audio and visual information using spatial and temporal attention mechanisms to identify answers in multi-modal scenes. Extensive experiments on the Music-AVQA and AVQA-Yang datasets show that SaSR-Net outperforms state-of-the-art AVQA methods.
翻译:音视频问答(AVQA)是一项具有挑战性的任务,需要基于视频中的听觉和视觉信息回答问题。一个关键挑战在于解析包含视觉对象和声源在内的复杂多模态场景,并将其与给定问题相关联。本文提出了源感知语义表征网络(SaSR-Net),这是一种专为AVQA设计的新型模型。SaSR-Net利用源感知可学习令牌,高效捕获音视频元素并将其与对应问题对齐。该模型通过空间与时间注意力机制,简化音频与视觉信息的融合过程,从而在多模态场景中定位答案。在Music-AVQA和AVQA-Yang数据集上的大量实验表明,SaSR-Net的性能优于当前最先进的AVQA方法。