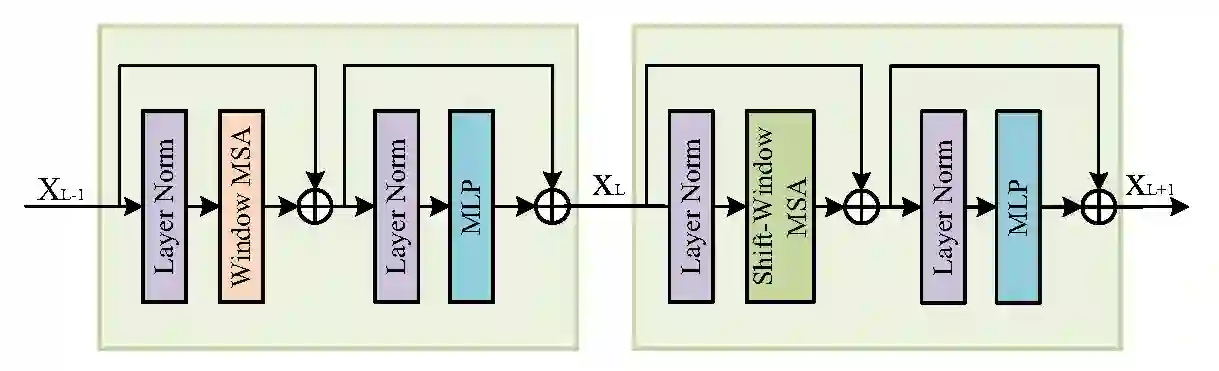
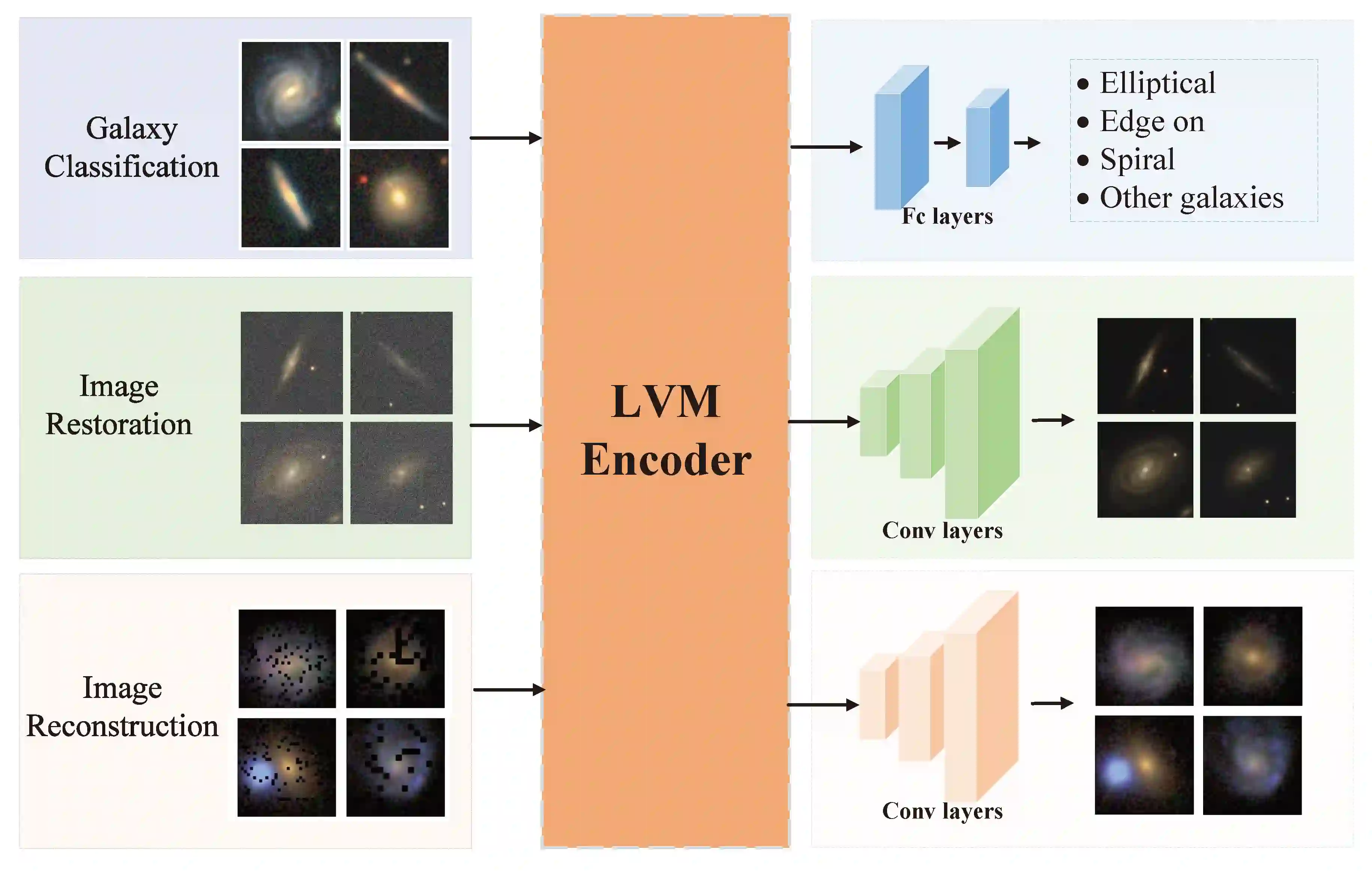
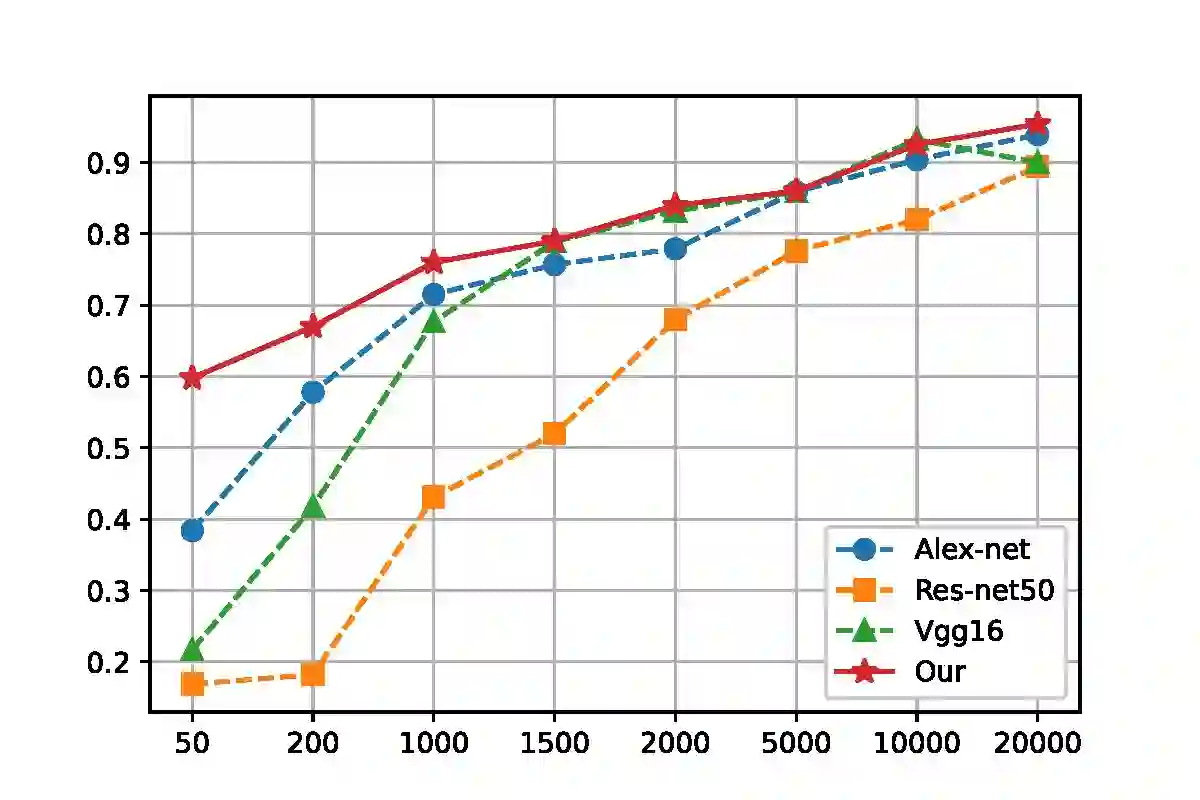
The exponential growth of astronomical datasets provides an unprecedented opportunity for humans to gain insight into the Universe. However, effectively analyzing this vast amount of data poses a significant challenge. Astronomers are turning to deep learning techniques to address this, but the methods are limited by their specific training sets, leading to considerable duplicate workloads too. Hence, as an example to present how to overcome the issue, we built a framework for general analysis of galaxy images, based on a large vision model (LVM) plus downstream tasks (DST), including galaxy morphological classification, image restoration, object detection, parameter extraction, and more. Considering the low signal-to-noise ratio of galaxy images and the imbalanced distribution of galaxy categories, we have incorporated a Human-in-the-loop (HITL) module into our large vision model, which leverages human knowledge to enhance the reliability and interpretability of processing galaxy images interactively. The proposed framework exhibits notable few-shot learning capabilities and versatile adaptability to all the abovementioned tasks on galaxy images in the DESI legacy imaging surveys. Expressly, for object detection, trained by 1000 data points, our DST upon the LVM achieves an accuracy of 96.7%, while ResNet50 plus Mask R-CNN gives an accuracy of 93.1%; for morphology classification, to obtain AUC ~0.9, LVM plus DST and HITL only requests 1/50 training sets compared to ResNet18. Expectedly, multimodal data can be integrated similarly, which opens up possibilities for conducting joint analyses with datasets spanning diverse domains in the era of multi-message astronomy.
翻译:天文数据集的指数级增长为人类深入理解宇宙提供了前所未有的机遇。然而,有效分析海量数据仍是一大挑战。天文学家正借助深度学习技术应对这一难题,但现有方法受限于特定训练集,导致大量重复性工作。为此,我们构建了一个基于大型视觉模型(LVM)与下游任务(DST)的星系图像通用分析框架,涵盖星系形态分类、图像复原、目标检测、参数提取等功能。针对星系图像信噪比低及类别分布不平衡的问题,我们在大型视觉模型中嵌入人机协同(HITL)模块,通过注入人类知识增强星系图像交互式处理的可靠性与可解释性。该框架在DESI遗留巡天项目的星系图像上展现出显著的小样本学习能力与多任务适应性。具体而言,在目标检测任务中,基于LVM的下游模型仅用1000个训练数据点即可达到96.7%的准确率,而ResNet50+Mask R-CNN的准确率为93.1%;在形态分类任务中,为达到约0.9的AUC值,LVM+DST+HITL仅需ResNet18五十分之一的训练集。展望未来,多模态数据可通过类似方式整合,为多信使天文学时代跨领域数据集联合分析开辟了新可能。