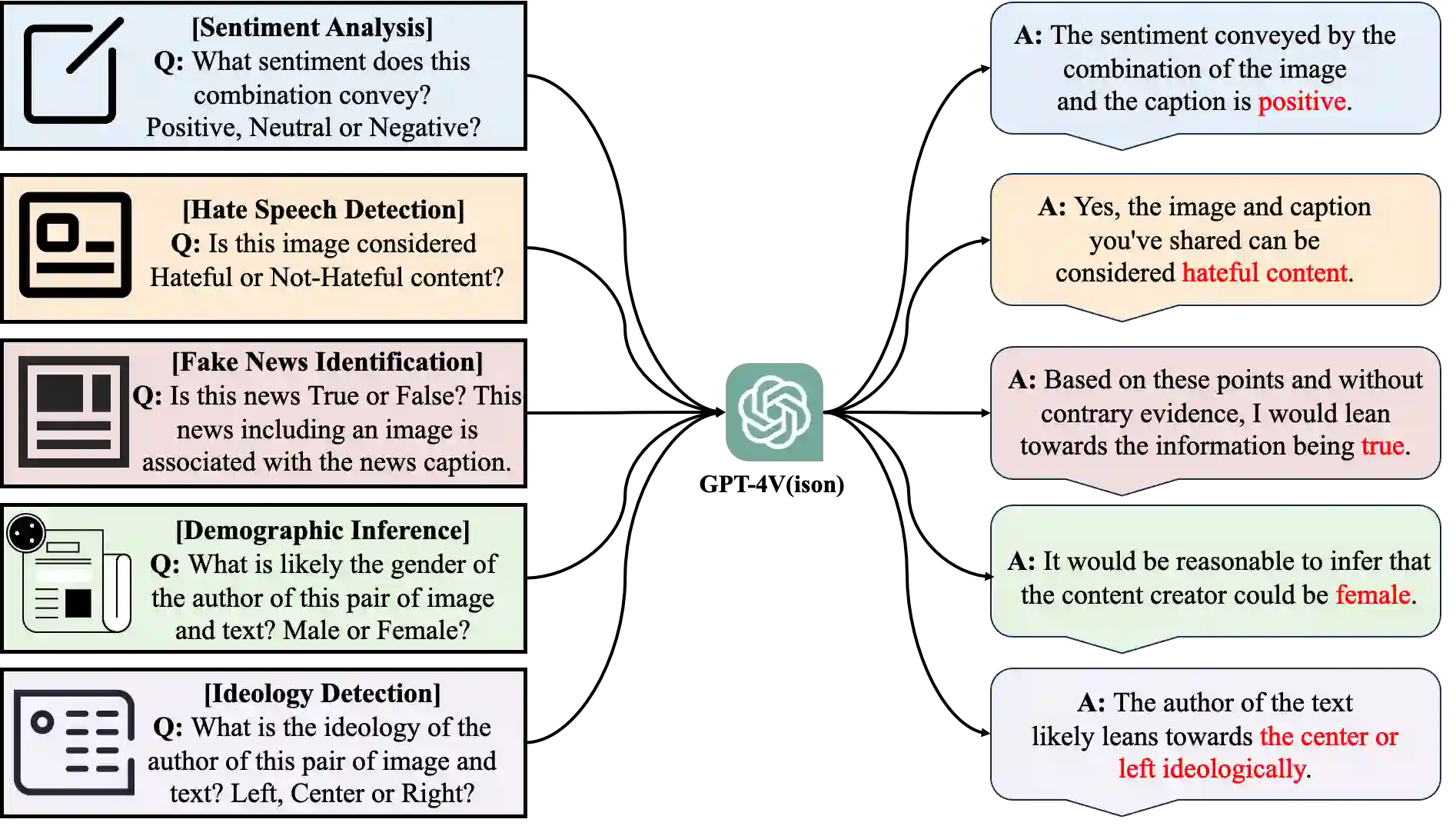
Recent research has offered insights into the extraordinary capabilities of Large Multimodal Models (LMMs) in various general vision and language tasks. There is growing interest in how LMMs perform in more specialized domains. Social media content, inherently multimodal, blends text, images, videos, and sometimes audio. Understanding social multimedia content remains a challenging problem for contemporary machine learning frameworks. In this paper, we explore GPT-4V(ision)'s capabilities for social multimedia analysis. We select five representative tasks, including sentiment analysis, hate speech detection, fake news identification, demographic inference, and political ideology detection, to evaluate GPT-4V. Our investigation begins with a preliminary quantitative analysis for each task using existing benchmark datasets, followed by a careful review of the results and a selection of qualitative samples that illustrate GPT-4V's potential in understanding multimodal social media content. GPT-4V demonstrates remarkable efficacy in these tasks, showcasing strengths such as joint understanding of image-text pairs, contextual and cultural awareness, and extensive commonsense knowledge. Despite the overall impressive capacity of GPT-4V in the social media domain, there remain notable challenges. GPT-4V struggles with tasks involving multilingual social multimedia comprehension and has difficulties in generalizing to the latest trends in social media. Additionally, it exhibits a tendency to generate erroneous information in the context of evolving celebrity and politician knowledge, reflecting the known hallucination problem. The insights gleaned from our findings underscore a promising future for LMMs in enhancing our comprehension of social media content and its users through the analysis of multimodal information.
翻译:近期研究揭示了大规模多模态模型(LMMs)在各类通用视觉与语言任务中的卓越能力。人们日益关注LMMs在更专业领域的表现。社交媒体内容天然具有多模态特性,融合文本、图像、视频乃至音频。理解社交多媒体内容对当代机器学习框架仍是一项挑战。本文探索了GPT-4V(ision)在社交多媒体分析中的能力,选取情感分析、仇恨言论检测、虚假新闻识别、人口统计推断和政治意识形态检测五项代表性任务进行评估。研究首先利用现有基准数据集对每项任务进行初步定量分析,随后仔细审视结果并选取定性样本,展示GPT-4V在理解多模态社交媒体内容方面的潜力。GPT-4V在这些任务中展现出显著效能,其优势包括图文对联合理解、语境与文化感知以及广泛常识知识。尽管GPT-4V在社交媒体领域整体表现令人印象深刻,但仍存在显著挑战:在处理多语言社交多媒体理解任务时力有不逮,难以泛化至社交媒体最新趋势;此外,在涉及不断演变的公众人物与政客知识时易生成错误信息,反映出已知的幻觉问题。研究结论表明,LMMs通过分析多模态信息以深化我们对社交媒体内容及其用户的理解,前景广阔。