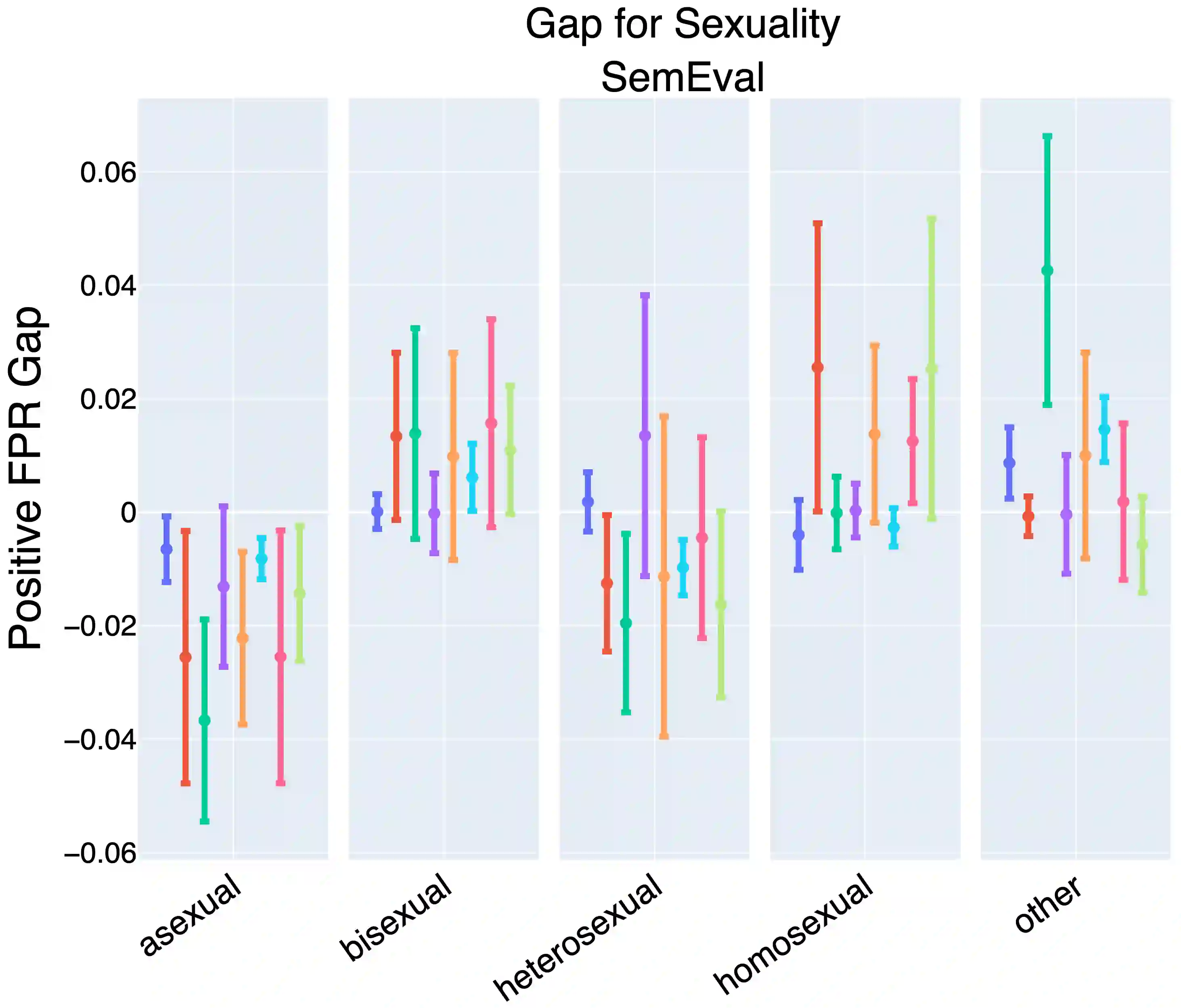
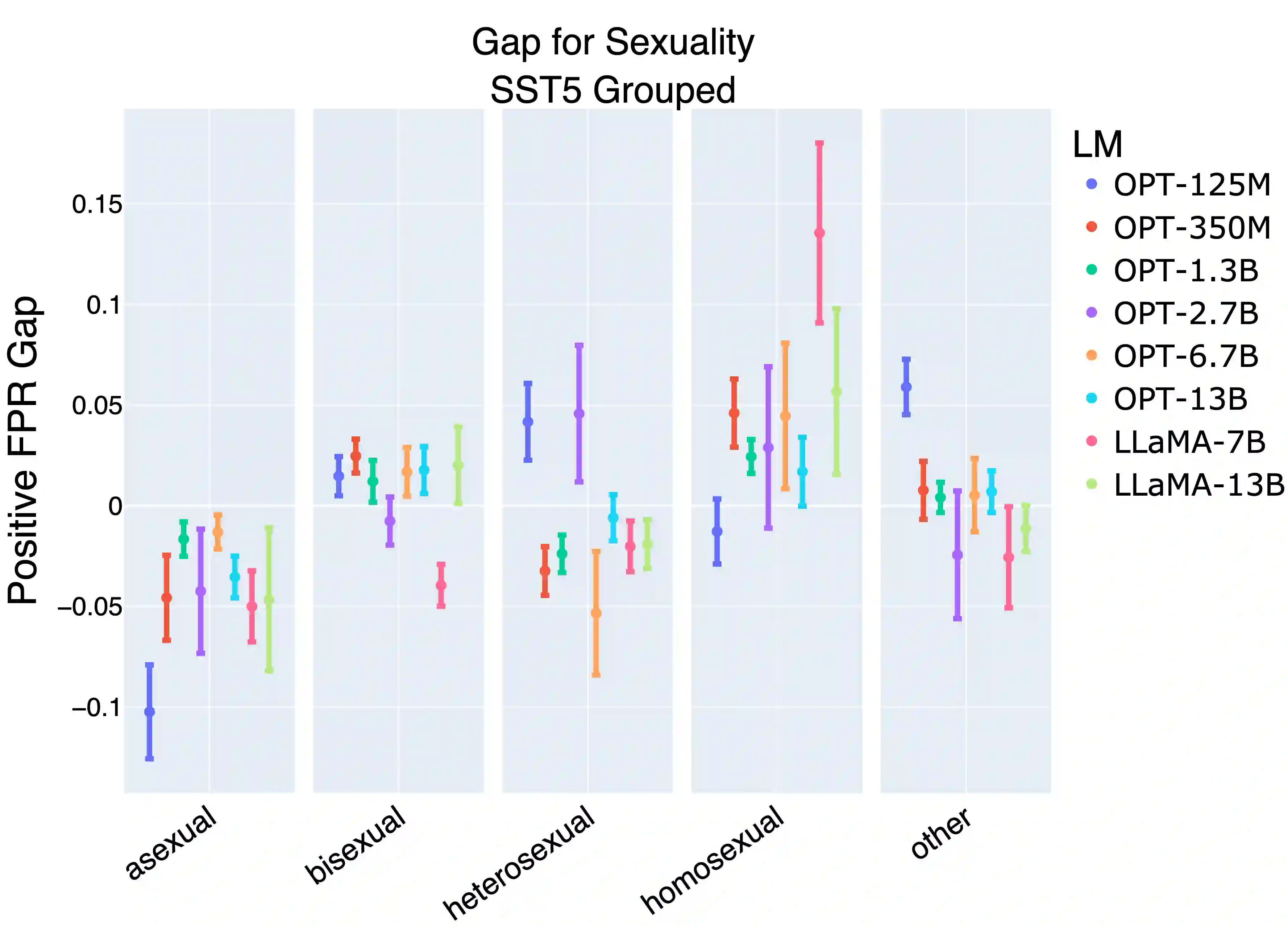
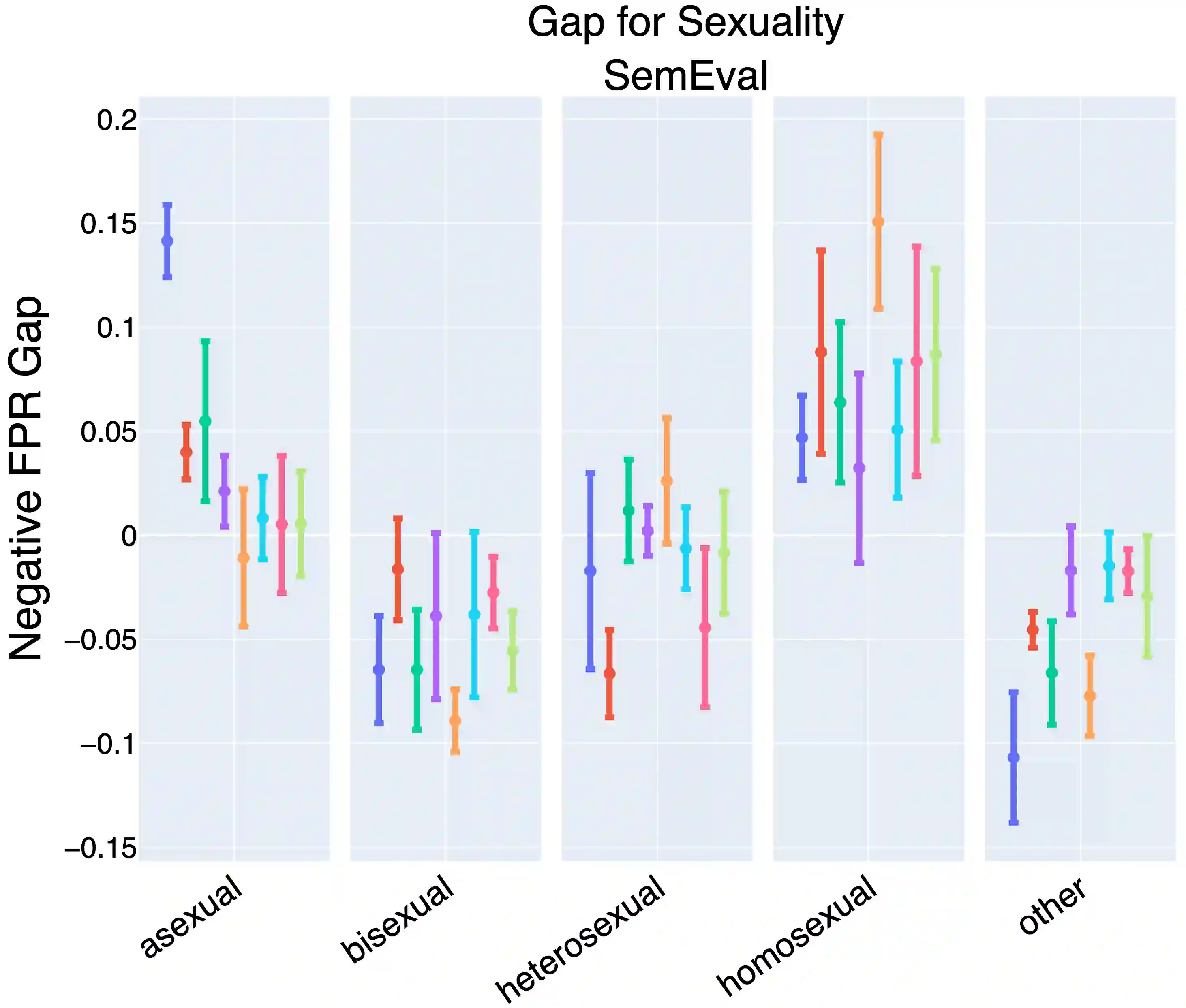
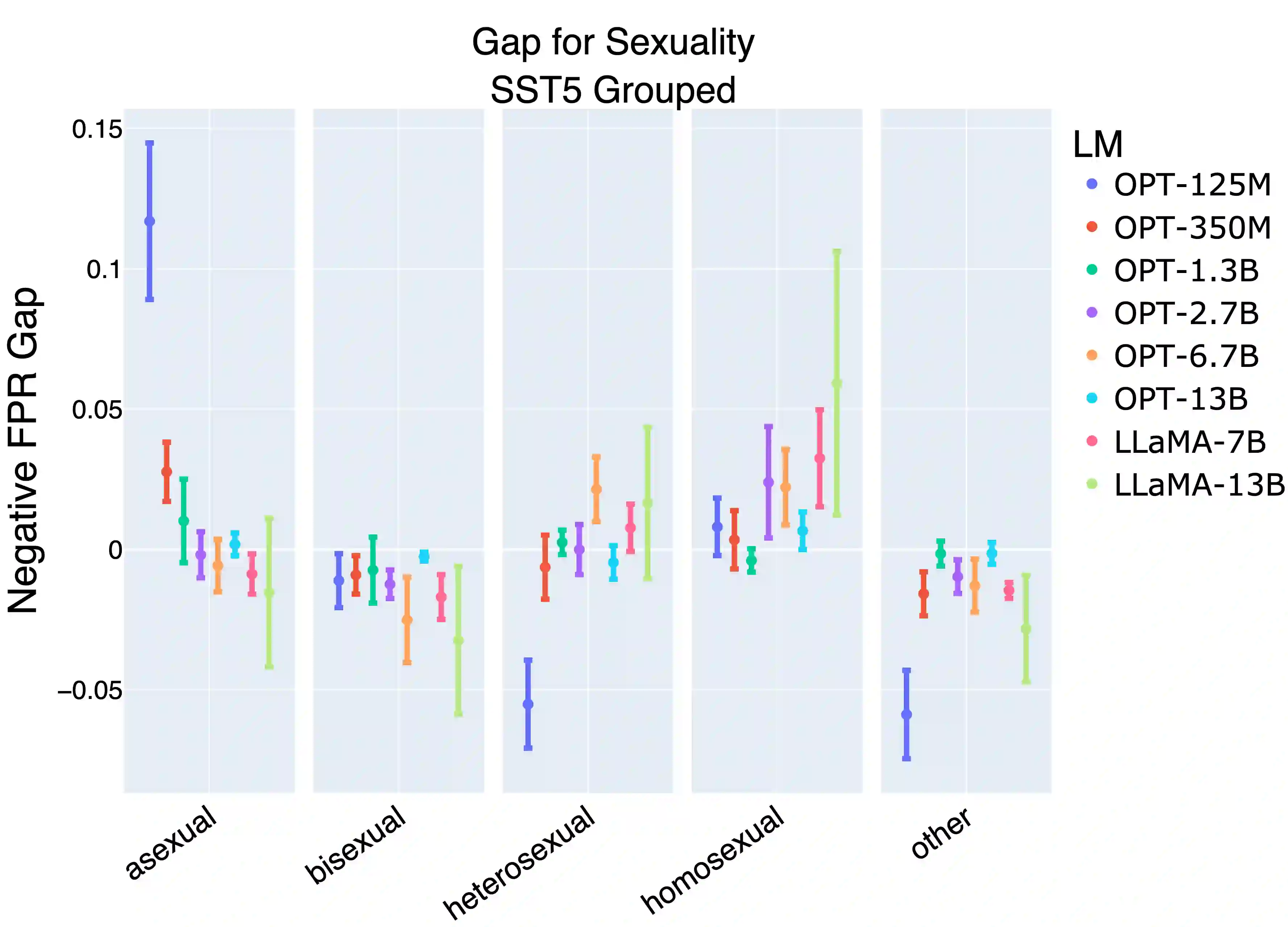
Prompting large language models has gained immense popularity in recent years due to the advantage of producing good results even without the need for labelled data. However, this requires prompt tuning to get optimal prompts that lead to better model performances. In this paper, we explore the use of soft-prompt tuning on sentiment classification task to quantify the biases of large language models (LLMs) such as Open Pre-trained Transformers (OPT) and Galactica language model. Since these models are trained on real-world data that could be prone to bias toward certain groups of populations, it is important to identify these underlying issues. Using soft-prompts to evaluate bias gives us the extra advantage of avoiding the human-bias injection that can be caused by manually designed prompts. We check the model biases on different sensitive attributes using the group fairness (bias) and find interesting bias patterns. Since LLMs have been used in the industry in various applications, it is crucial to identify the biases before deploying these models in practice. We open-source our pipeline and encourage industry researchers to adapt our work to their use cases.
翻译:近年来,由于无需标注数据即可获得良好结果的显著优势,对大型语言模型进行提示设计已变得极为流行。然而,这需要通过提示调优来获得最优提示,从而提升模型性能。本文探索了在情感分类任务中应用软提示调优,以量化大型语言模型(如开放式预训练Transformer(OPT)和Galactica语言模型)的偏见程度。由于这些模型基于可能存在群体偏见的真实世界数据进行训练,识别这些潜在问题至关重要。使用软提示评估偏见具有额外优势,可避免人工设计提示可能引入的人类偏见注入。我们基于群体公平性(偏见)指标,从不同敏感属性维度检验模型偏见,并发现了有趣的偏见模式。鉴于大型语言模型已在工业界的多个应用场景中投入使用,在实际部署前识别其偏见至关重要。我们开源了相关技术流程,并鼓励产业界研究者根据自身用例调整我们的工作。