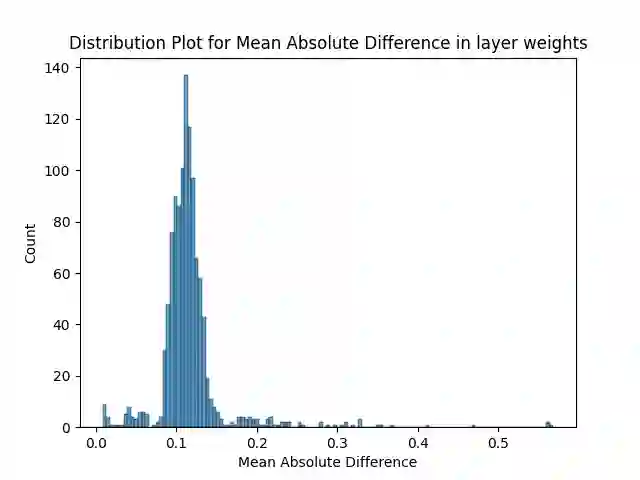
The attention mechanism forms the foundational blocks for transformer language models. Recent approaches show that scaling the model achieves human-level performance. However, with increasing demands for scaling and constraints on hardware memory, the inference costs of these models remain high. To reduce the inference time, Multi-Query Attention (MQA) and Grouped-Query Attention (GQA) were proposed in (Shazeer, 2019) and (Ainslieet al., 2023) respectively. In this paper, we propose a variation of Grouped-Query Attention, termed Weighted Grouped-Query Attention (WGQA). We introduced new learnable parameters for each key and value head in the T5 decoder attention blocks, enabling the model to take a weighted average during finetuning. Our model achieves an average of 0.53% improvement over GQA, and the performance converges to traditional Multi-head attention (MHA) with no additional overhead during inference. We evaluated the introduction of these parameters and subsequent finetuning informs the model about the grouping mechanism during training, thereby enhancing performance. Additionally, we demonstrate the scaling laws in our analysis by comparing the results between T5-small and T5-base architecture.
翻译:注意力机制构成了Transformer语言模型的基础模块。近期研究表明,扩大模型规模可实现人类水平的性能。然而,随着对模型扩展需求的增长和硬件内存的限制,这些模型的推理成本仍然居高不下。为降低推理时间,Shazeer(2019)和Ainslie等人(2023)分别提出了多查询注意力(MQA)和分组查询注意力(GQA)。本文提出一种分组查询注意力的变体,称为加权分组查询注意力(WGQA)。我们在T5解码器注意力模块中为每个键和值头引入了新的可学习参数,使模型能够在微调期间进行加权平均计算。相较于GQA,我们的模型平均实现了0.53%的性能提升,且推理时无需额外开销即可收敛至传统多头注意力(MHA)的性能水平。实验评估表明,这些参数的引入及后续微调能使模型在训练过程中理解分组机制,从而提升性能。此外,通过对比T5-small与T5-base架构的结果,我们在分析中验证了缩放定律的适用性。