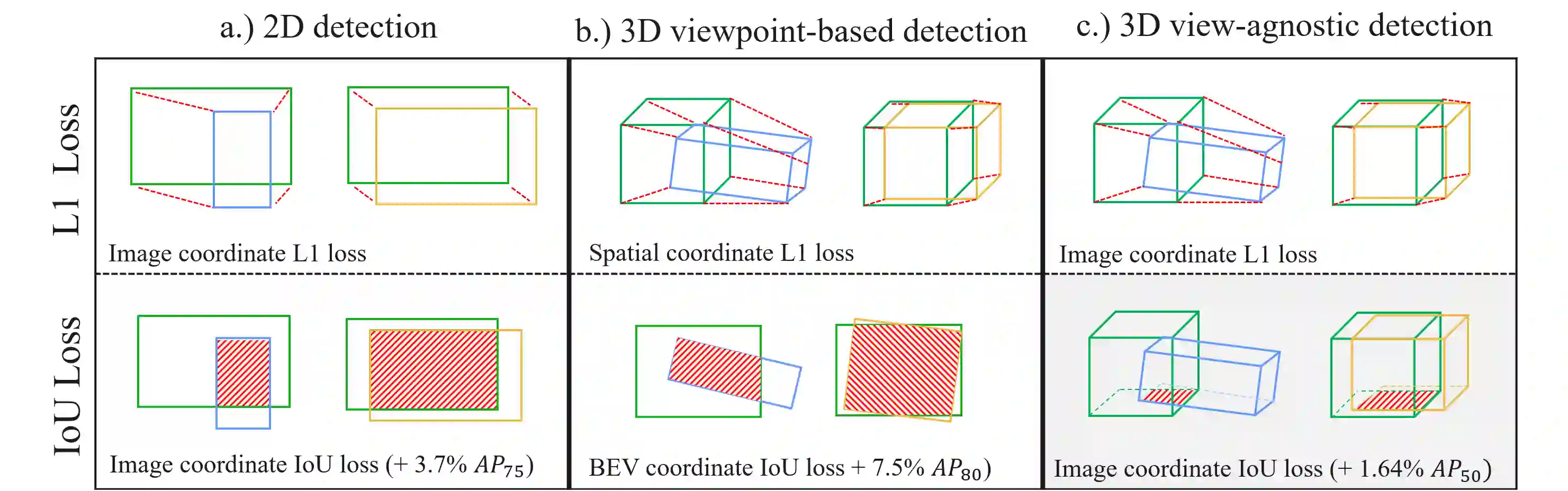
Monocular 3D object detection is a challenging task because depth information is difficult to obtain from 2D images. A subset of viewpoint-agnostic monocular 3D detection methods also do not explicitly leverage scene homography or geometry during training, meaning that a model trained thusly can detect objects in images from arbitrary viewpoints. Such works predict the projections of the 3D bounding boxes on the image plane to estimate the location of the 3D boxes, but these projections are not rectangular so the calculation of IoU between these projected polygons is not straightforward. This work proposes an efficient, fully differentiable algorithm for the calculation of IoU between two convex polygons, which can be utilized to compute the IoU between two 3D bounding box footprints viewed from an arbitrary angle. We test the performance of the proposed polygon IoU loss (PIoU loss) on three state-of-the-art viewpoint-agnostic 3D detection models. Experiments demonstrate that the proposed PIoU loss converges faster than L1 loss and that in 3D detection models, a combination of PIoU loss and L1 loss gives better results than L1 loss alone (+1.64% AP70 for MonoCon on cars, +0.18% AP70 for RTM3D on cars, and +0.83%/+2.46% AP50/AP25 for MonoRCNN on cyclists).
翻译:单目三维目标检测是一项具有挑战性的任务,因为从二维图像中难以获取深度信息。一类视角无关的单目三维检测方法在训练过程中并未显式利用场景单应性或几何信息,这意味着以此方式训练的模型能够从任意视角的图像中检测目标。此类方法通过预测三维边界框在图像平面上的投影来估计三维边界框的位置,但由于这些投影并非矩形,因此在这些投影多边形之间计算交并比(IoU)并非易事。本文提出了一种高效且完全可微分的算法,用于计算两个凸多边形之间的IoU,该算法可用于计算从任意角度观察的两个三维边界框投影之间的IoU。我们在三个最先进的视角无关三维检测模型上测试了所提出的多边形IoU损失(PIoU损失)的性能。实验表明,所提出的PIoU损失比L1损失收敛更快,并且在三维检测模型中,PIoU损失与L1损失的组合比单独使用L1损失效果更好(对于MonoCon在汽车类别上AP70提升+1.64%,对于RTM3D在汽车类别上AP70提升+0.18%,对于MonoRCNN在自行车类别上AP50/AP25分别提升+0.83%和+2.46%)。