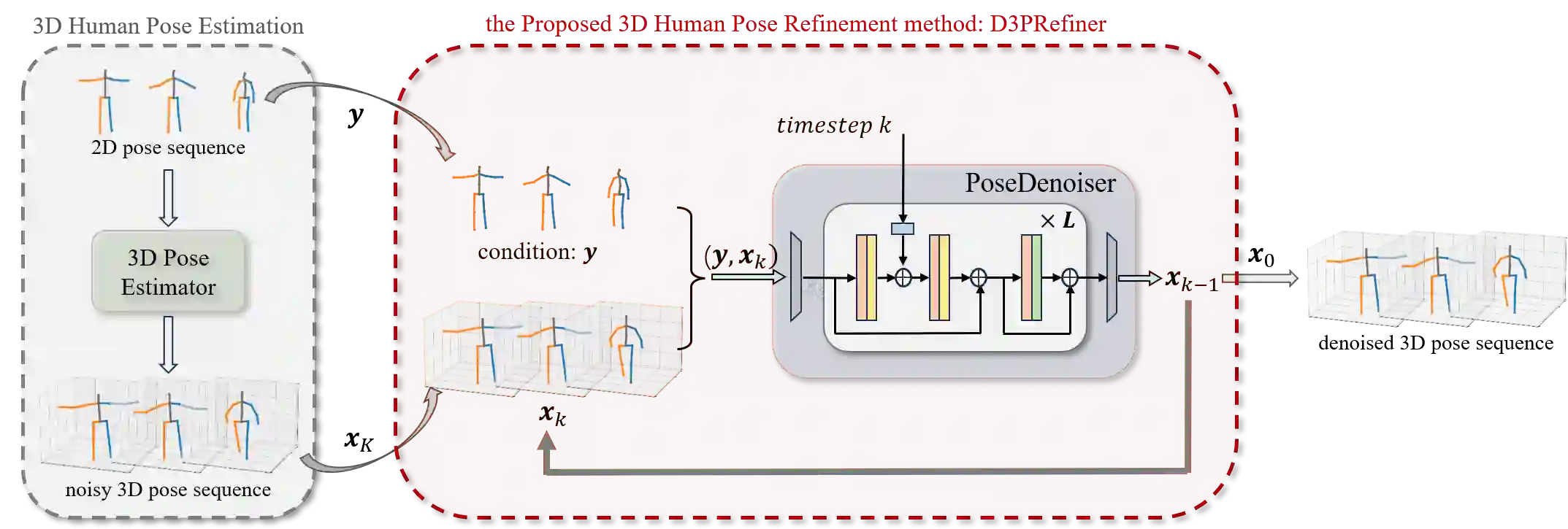
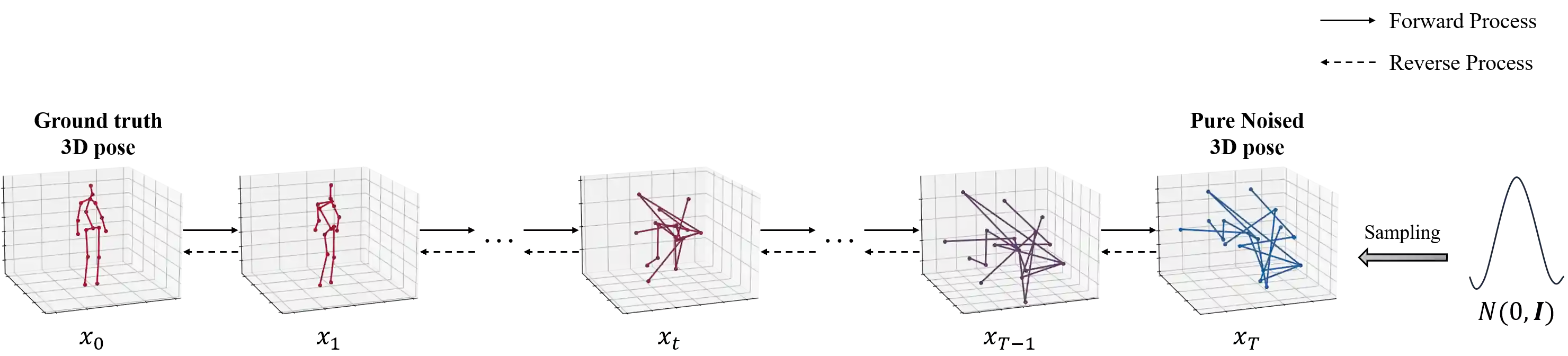
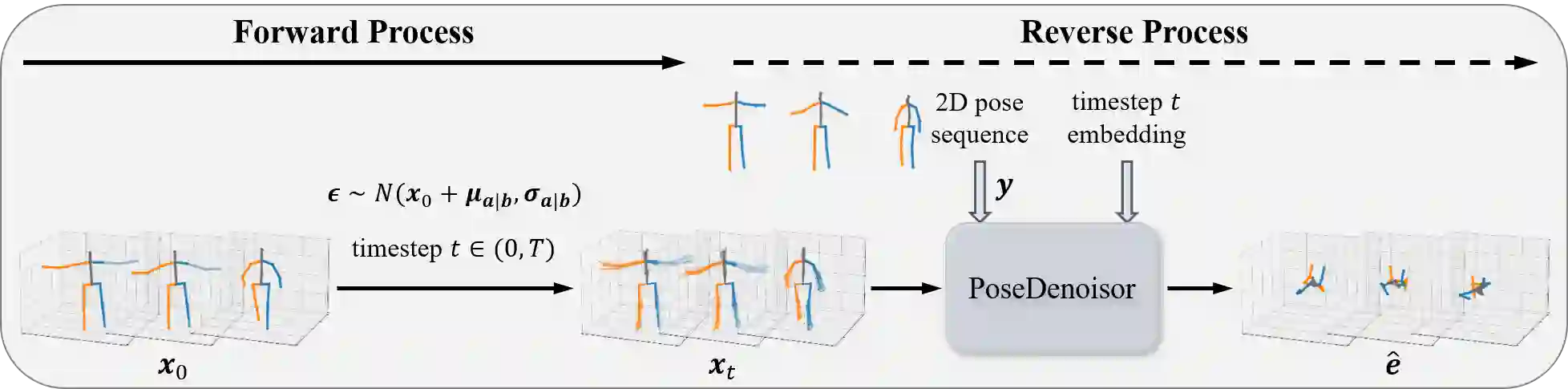
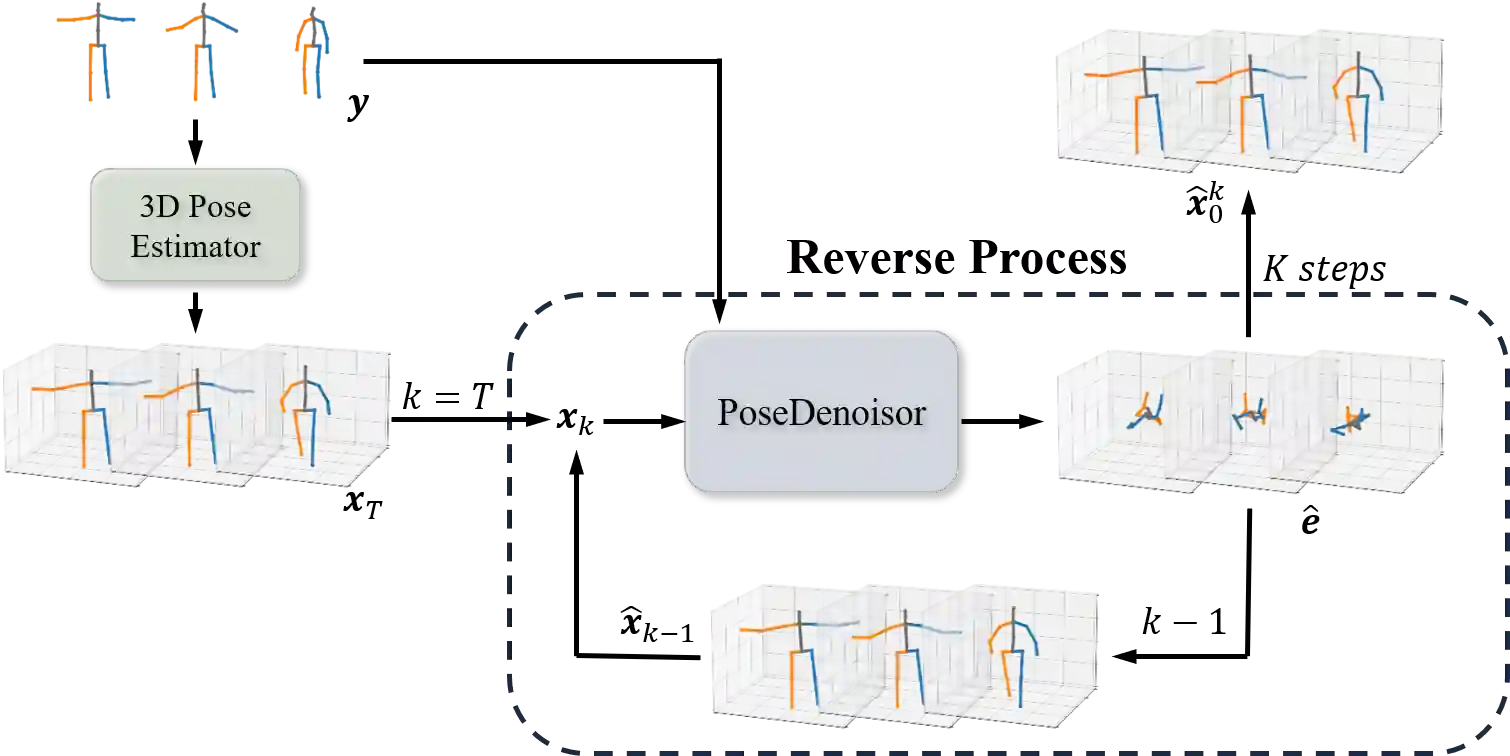
Three-dimensional (3D) human pose estimation using a monocular camera has gained increasing attention due to its ease of implementation and the abundance of data available from daily life. However, owing to the inherent depth ambiguity in images, the accuracy of existing monocular camera-based 3D pose estimation methods remains unsatisfactory, and the estimated 3D poses usually include much noise. By observing the histogram of this noise, we find each dimension of the noise follows a certain distribution, which indicates the possibility for a neural network to learn the mapping between noisy poses and ground truth poses. In this work, in order to obtain more accurate 3D poses, a Diffusion-based 3D Pose Refiner (D3PRefiner) is proposed to refine the output of any existing 3D pose estimator. We first introduce a conditional multivariate Gaussian distribution to model the distribution of noisy 3D poses, using paired 2D poses and noisy 3D poses as conditions to achieve greater accuracy. Additionally, we leverage the architecture of current diffusion models to convert the distribution of noisy 3D poses into ground truth 3D poses. To evaluate the effectiveness of the proposed method, two state-of-the-art sequence-to-sequence 3D pose estimators are used as basic 3D pose estimation models, and the proposed method is evaluated on different types of 2D poses and different lengths of the input sequence. Experimental results demonstrate the proposed architecture can significantly improve the performance of current sequence-to-sequence 3D pose estimators, with a reduction of at least 10.3% in the mean per joint position error (MPJPE) and at least 11.0% in the Procrustes MPJPE (P-MPJPE).
翻译:利用单目相机进行三维人体姿态估计因其实现简便且日常生活中的数据来源丰富而日益受到关注。然而,由于图像中固有的深度模糊性,现有基于单目相机的三维姿态估计方法的精度仍不理想,且估计出的三维姿态通常包含大量噪声。通过观察该噪声的直方图,我们发现噪声的每一维均服从特定分布,这表明神经网络具备学习含噪姿态与真实姿态间映射关系的可能性。为获取更精确的三维姿态,本文提出一种基于扩散的三维姿态精化器(D3PRefiner),用于优化现有任意三维姿态估计器的输出。我们首先引入条件多元高斯分布对含噪三维姿态的分布进行建模,以配对二维姿态和含噪三维姿态作为条件来提升精度。此外,我们利用当前扩散模型的架构将含噪三维姿态的分布转化为真实三维姿态。为评估所提方法的有效性,采用两种最先进的序列到序列三维姿态估计器作为基础三维姿态估计模型,并在不同类型的二维姿态及不同输入序列长度上开展验证。实验结果表明,所提架构能显著提升当前序列到序列三维姿态估计器的性能,其中平均关节位置误差(MPJPE)降低至少10.3%,Procrustes平均关节位置误差(P-MPJPE)降低至少11.0%。