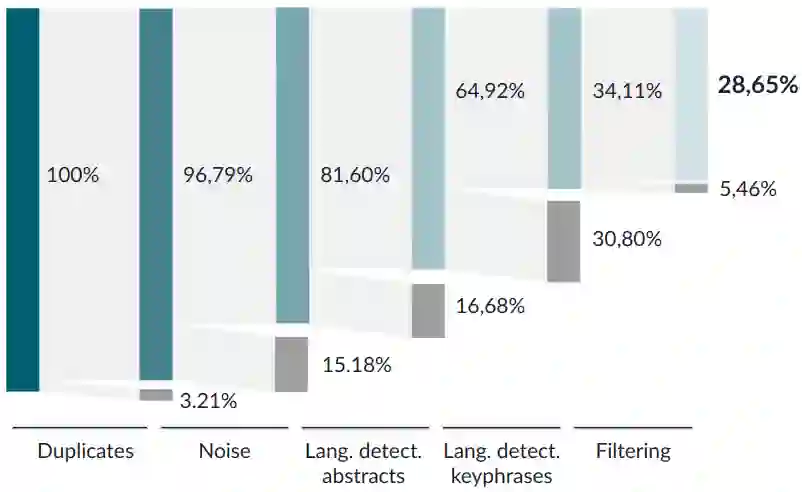
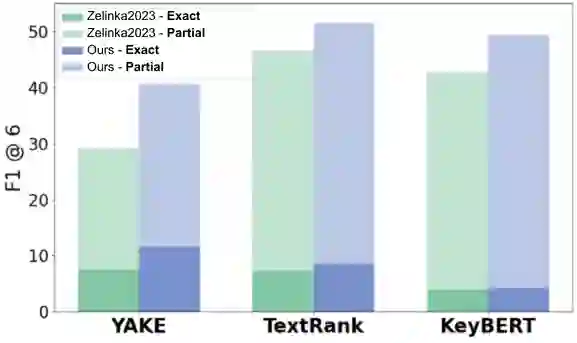
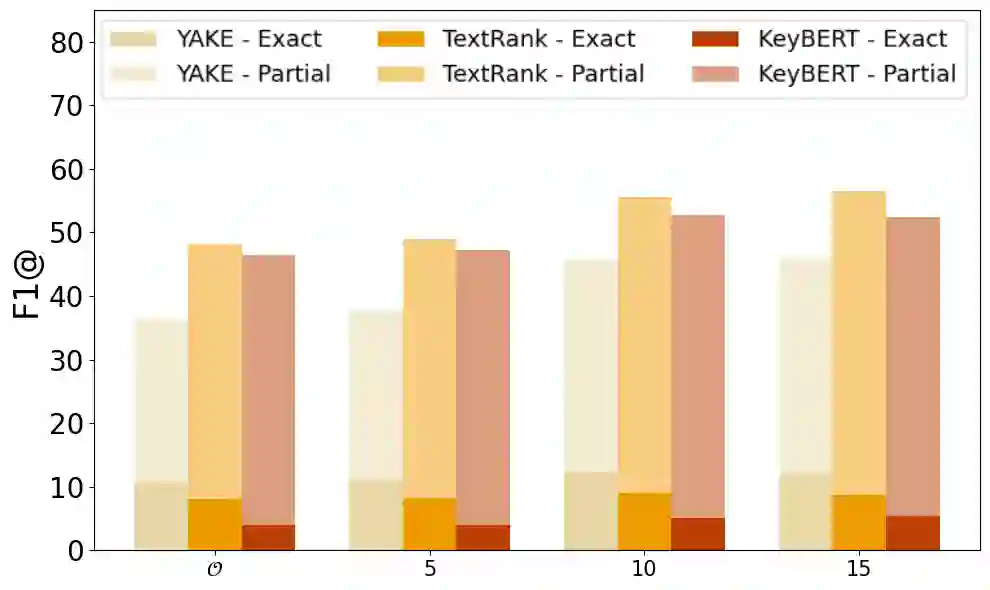
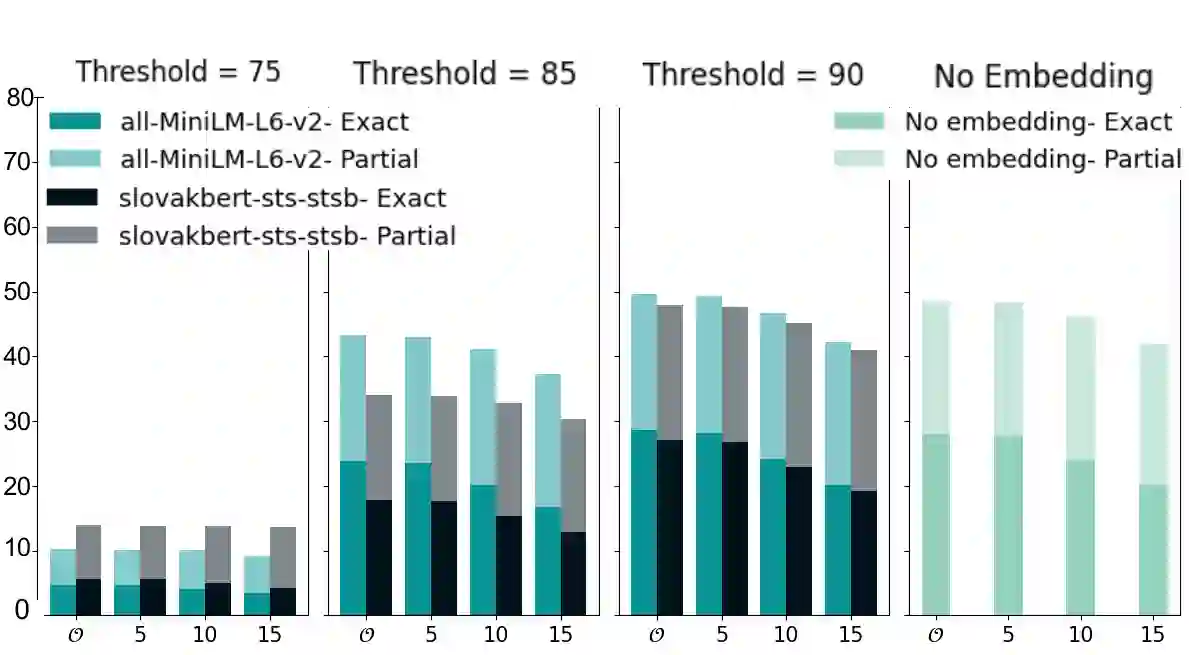
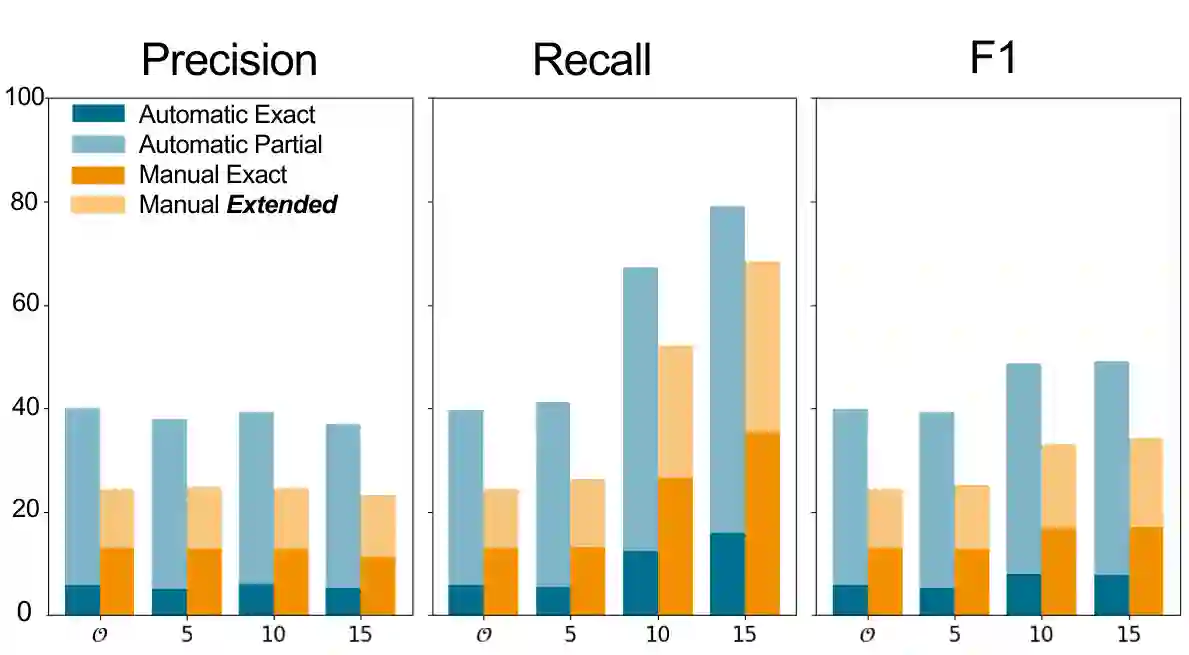
Keyphrase extraction for morphologically rich, low-resource languages remains understudied, largely due to the scarcity of suitable evaluation datasets. We address this gap for Slovak by constructing a dataset of 227,432 scientific abstracts with author-assigned keyphrases -- scraped and systematically cleaned from the Slovak Central Register of Theses -- representing a 25-fold increase over the largest prior Slovak resource and approaching the scale of established English benchmarks such as KP20K. Using this dataset, we benchmark three unsupervised baselines (YAKE, TextRank, KeyBERT with SlovakBERT embeddings) and evaluate KeyLLM, an LLM-based extraction method using GPT-3.5-turbo. Unsupervised baselines achieve at most 11.6\% exact-match $F1@6$, with a large gap to partial matching (up to 51.5\%), reflecting the difficulty of matching inflected surface forms to author-assigned keyphrases. KeyLLM narrows this exact--partial gap, producing keyphrases closer to the canonical forms assigned by authors, while manual evaluation on 100 documents ($κ= 0.61$) confirms that KeyLLM captures relevant concepts that automated exact matching underestimates. Our analysis identifies morphological mismatch as the dominant failure mode for statistical methods -- a finding relevant to other inflected languages. The dataset (https://huggingface.co/datasets/NaiveNeuron/SlovKE) and evaluation code (https://github.com/NaiveNeuron/SlovKE) are publicly available.
翻译:针对形态丰富、资源稀缺语言的关键词提取研究仍显不足,这主要源于缺乏合适的评估数据集。本研究针对斯洛伐克语填补了这一空白,通过构建包含227,432篇科学摘要及作者标注关键词的数据集——数据采集自斯洛伐克学位论文中央注册系统并经系统化清洗——其规模达到先前最大斯洛伐克语资源的25倍,并接近KP20K等成熟英语基准数据集的体量。基于该数据集,我们对三种无监督基线方法(YAKE、TextRank、采用SlovakBERT嵌入的KeyBERT)进行了基准测试,并评估了使用GPT-3.5-turbo的大型语言模型提取方法KeyLLM。无监督基线方法在精确匹配$F1@6$指标上最高仅达到11.6%,与部分匹配结果(最高51.5%)存在显著差距,这反映了屈折变化的表层形式与作者标注关键词之间的匹配难度。KeyLLM有效缩小了精确匹配与部分匹配间的差距,生成的关键词更接近作者标注的规范形式;同时基于100篇文档的人工评估($κ=0.61$)证实,KeyLLM能捕捉到自动化精确匹配所低估的相关概念。我们的分析指出形态失配是统计方法的主要失效模式——这一发现对其他屈折语言同样具有参考价值。数据集(https://huggingface.co/datasets/NaiveNeuron/SlovKE)与评估代码(https://github.com/NaiveNeuron/SlovKE)已公开发布。