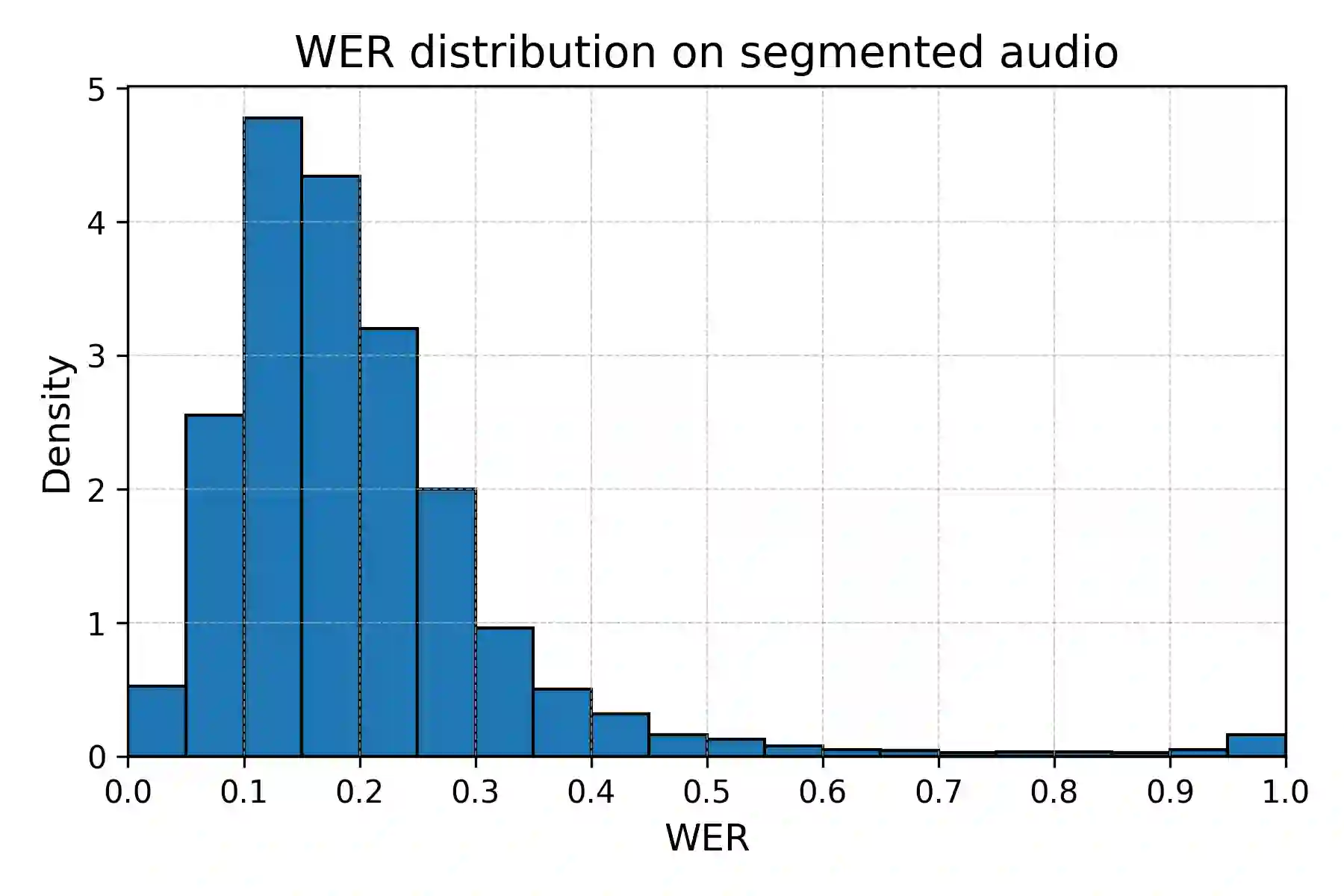
Slovak remains a low-resource language for automatic speech recognition (ASR), with fewer than 100 hours of publicly available training data. We present SloPal, a comprehensive Slovak parliamentary corpus comprising 330,000 speaker-segmented transcripts (66 million words, 220 million tokens) spanning 2001--2024, with rich metadata including speaker names, roles, and session information. From this collection, we derive SloPalSpeech, a 2,806-hour aligned speech dataset with segments up to 30 seconds, constructed using a language-agnostic anchor-based alignment pipeline and optimized for Whisper-based ASR training. Fine-tuning Whisper on SloPalSpeech reduces Word Error Rate (WER) by up to 70\%, with the fine-tuned small model (244M parameters) approaching base large-v3 (1.5B parameters) performance at 6$\times$ fewer parameters. We publicly release the SloPal text corpus, SloPalSpeech aligned audio, and four fine-tuned Whisper models at https://huggingface.co/collections/NaiveNeuron/slopal, providing the most comprehensive open Slovak parliamentary language resource to date.
翻译:斯洛伐克语在自动语音识别领域仍属低资源语言,公开可用的训练数据不足100小时。本文介绍SloPal——一个全面的斯洛伐克议会语料库,包含33万条说话人分段转录文本(6600万词,2.2亿标记),时间跨度为2001至2024年,并附有说话人姓名、角色及会议信息等丰富元数据。基于该文本集,我们构建了SloPalSpeech——一个2806小时的对齐语音数据集,其语音片段最长30秒,采用与语言无关的基于锚点的对齐流程构建,并针对基于Whisper的ASR训练进行了优化。在SloPalSpeech上微调Whisper模型可将词错误率降低高达70%,其中经微调的小型模型(2.44亿参数)在参数量减少6倍的情况下,性能接近基础large-v3模型(15亿参数)。我们公开发布了SloPal文本语料库、SloPalSpeech对齐音频及四个微调Whisper模型,发布地址为https://huggingface.co/collections/NaiveNeuron/slopal,提供了迄今为止最全面的开源斯洛伐克议会语言资源。