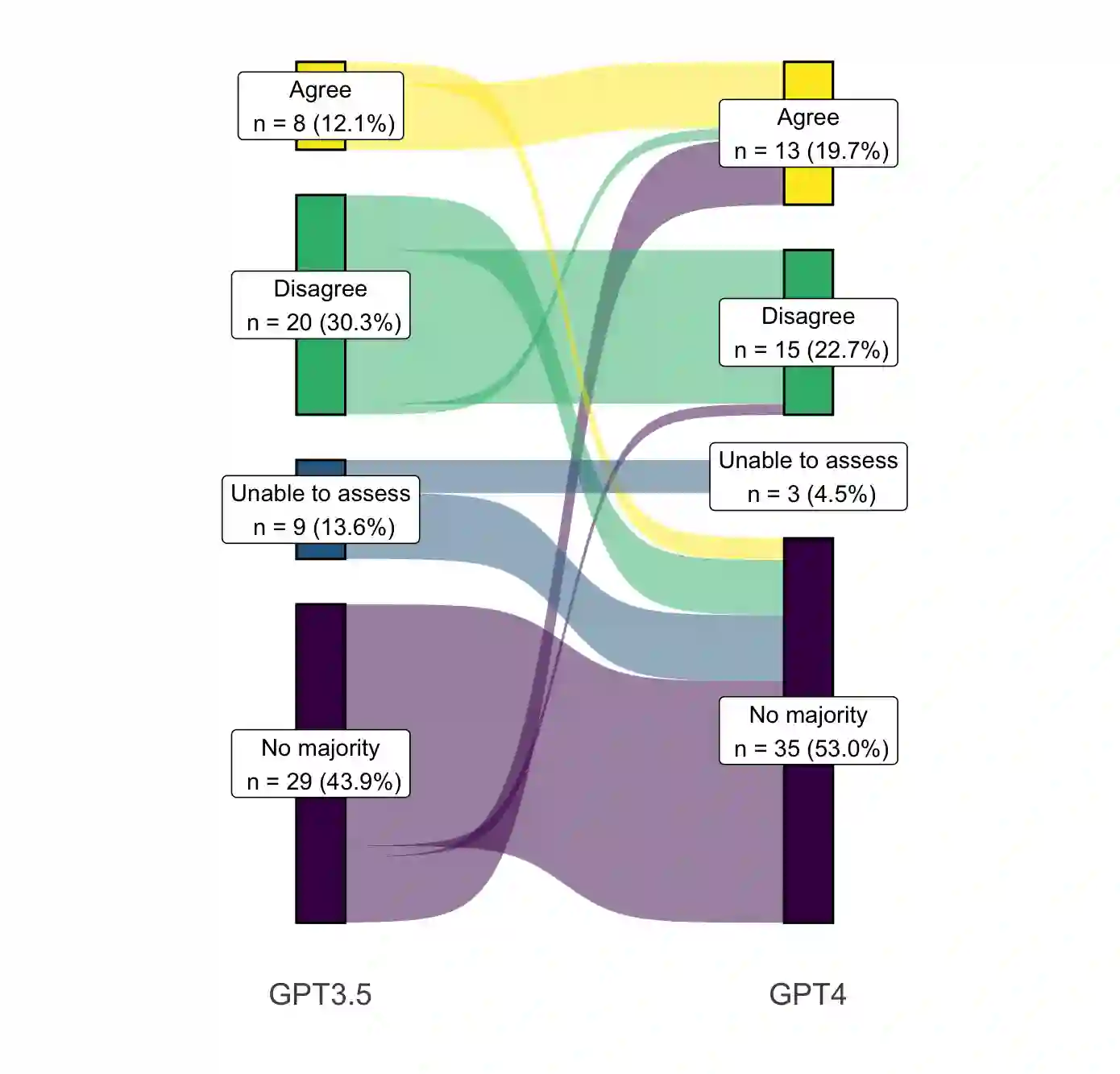
Despite growing interest in using large language models (LLMs) in healthcare, current explorations do not assess the real-world utility and safety of LLMs in clinical settings. Our objective was to determine whether two LLMs can serve information needs submitted by physicians as questions to an informatics consultation service in a safe and concordant manner. Sixty six questions from an informatics consult service were submitted to GPT-3.5 and GPT-4 via simple prompts. 12 physicians assessed the LLM responses' possibility of patient harm and concordance with existing reports from an informatics consultation service. Physician assessments were summarized based on majority vote. For no questions did a majority of physicians deem either LLM response as harmful. For GPT-3.5, responses to 8 questions were concordant with the informatics consult report, 20 discordant, and 9 were unable to be assessed. There were 29 responses with no majority on "Agree", "Disagree", and "Unable to assess". For GPT-4, responses to 13 questions were concordant, 15 discordant, and 3 were unable to be assessed. There were 35 responses with no majority. Responses from both LLMs were largely devoid of overt harm, but less than 20% of the responses agreed with an answer from an informatics consultation service, responses contained hallucinated references, and physicians were divided on what constitutes harm. These results suggest that while general purpose LLMs are able to provide safe and credible responses, they often do not meet the specific information need of a given question. A definitive evaluation of the usefulness of LLMs in healthcare settings will likely require additional research on prompt engineering, calibration, and custom-tailoring of general purpose models.
翻译:尽管将大语言模型(LLMs)应用于医疗领域的兴趣日益增长,但当前探索尚未评估LLMs在临床环境中的实际效用与安全性。本研究旨在验证两类LLM模型能否以安全且一致的方式,满足医生通过信息学咨询服务平台提交的医疗信息需求。我们通过简单提示向GPT-3.5和GPT-4提交了66个来自信息学咨询服务的临床问题。12名医生对LLM回复中可能导致患者伤害的风险以及与信息学咨询报告的一致性进行了评估,并通过多数投票法汇总评估结果。结果显示:未有任何问题的LLM回复被多数医生判定具有危害性。对于GPT-3.5,8个问题的回复与信息学咨询报告一致,20个不一致,9个无法评估,另有29个回复在"一致""不一致""无法评估"三项中未形成多数意见。对于GPT-4,13个问题的回复一致,15个不一致,3个无法评估,35个回复未形成多数意见。两类LLM的回复整体未呈现明显危害性,但仅有不足20%的回复与信息学咨询服务的结论相符,部分回复包含虚构文献引用,且医生对"危害"的界定存在分歧。研究表明:通用LLM虽能提供安全可信的回复,但往往无法精准满足特定问题的信息需求。要全面评估LLM在医疗场景中的实用性,仍需在提示工程、模型校准及通用模型的定制化适配方面开展进一步研究。