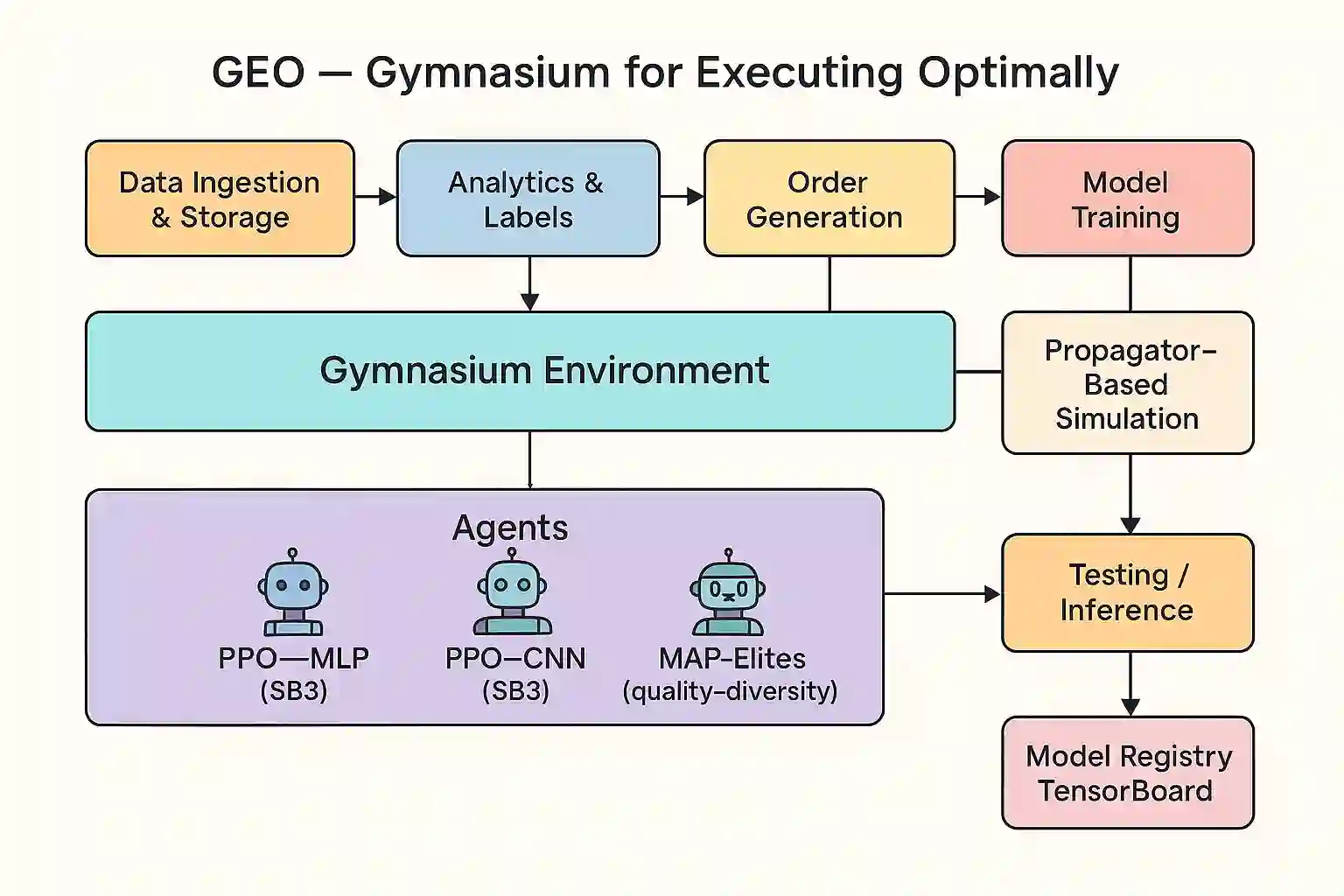
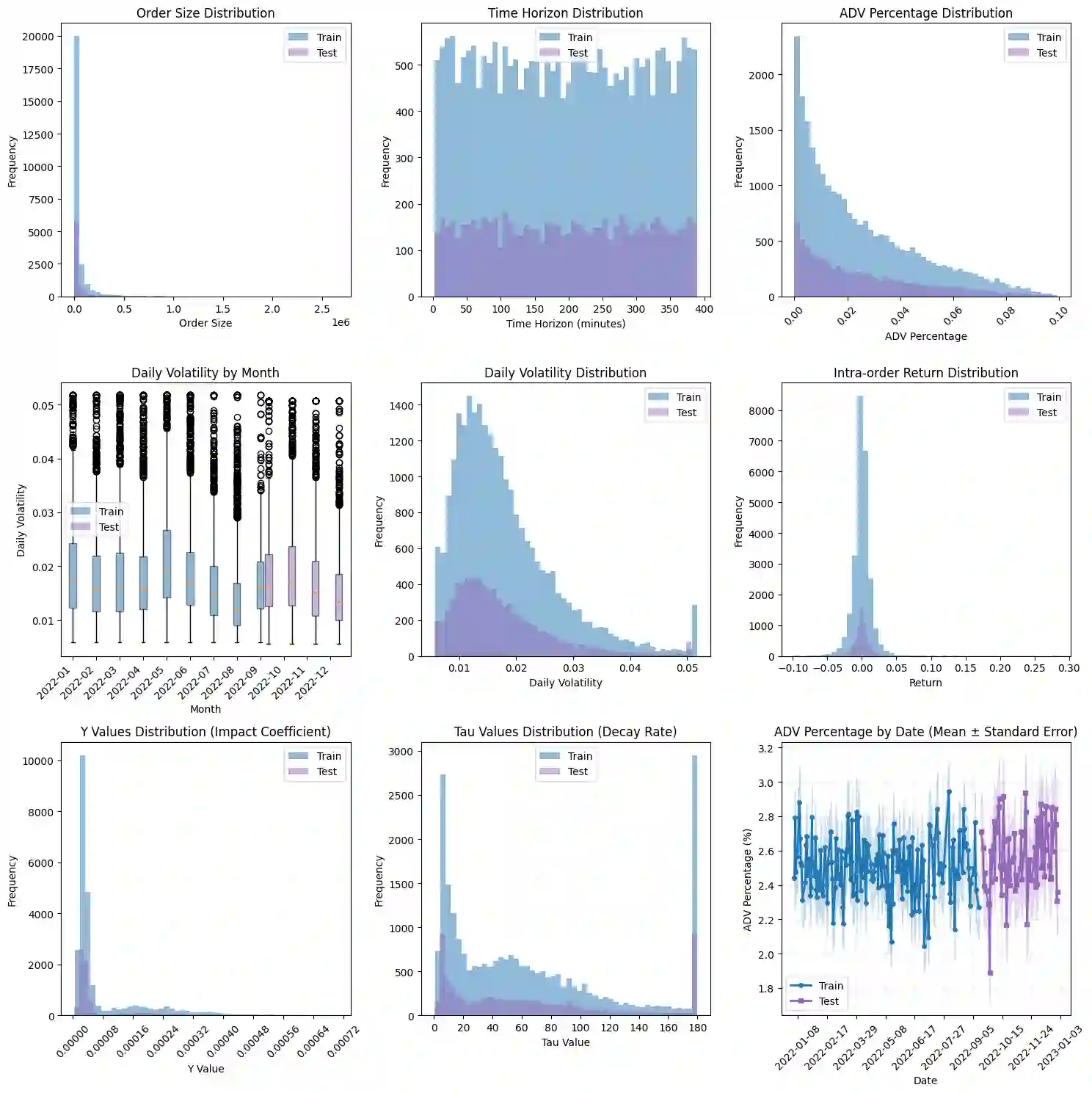
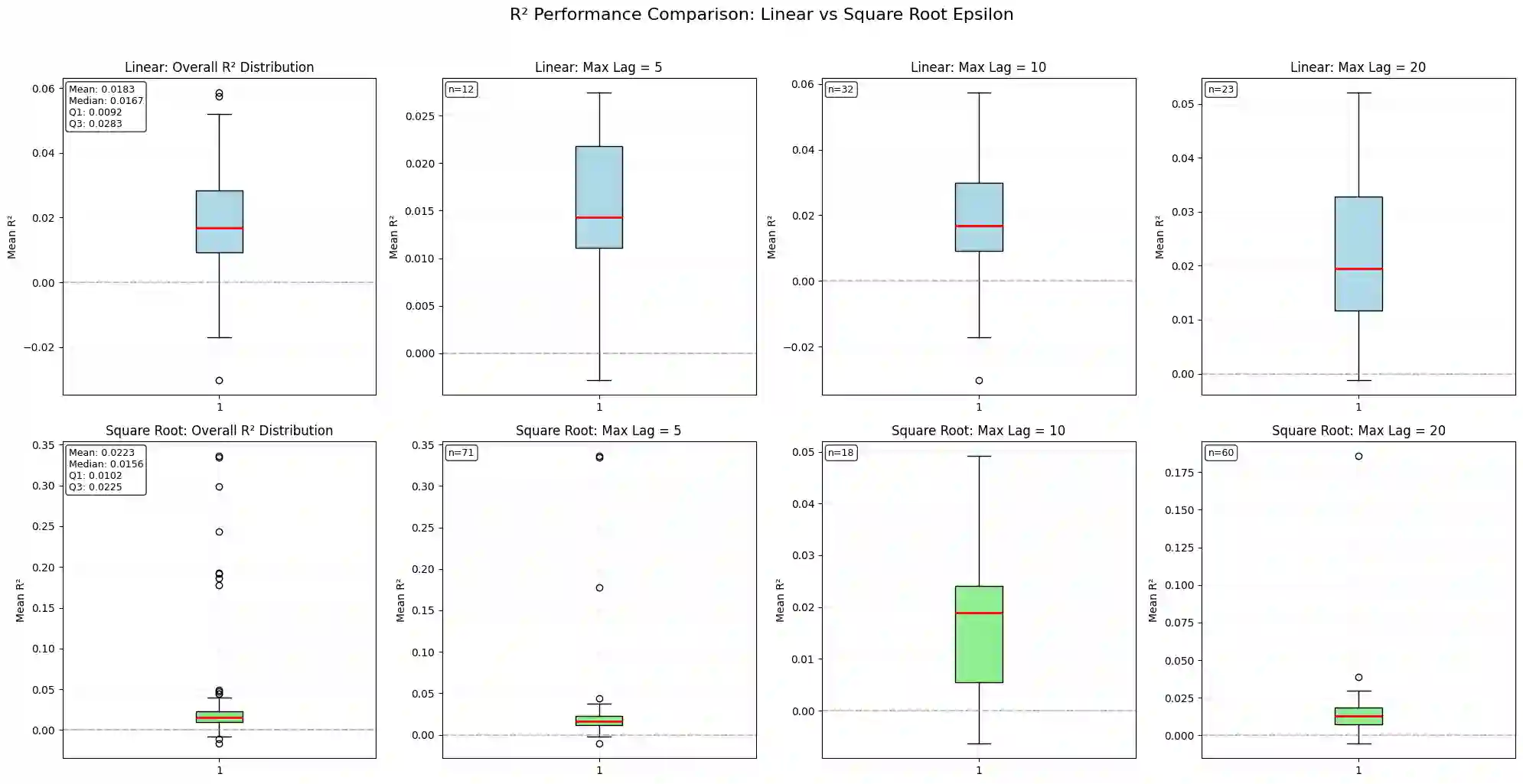
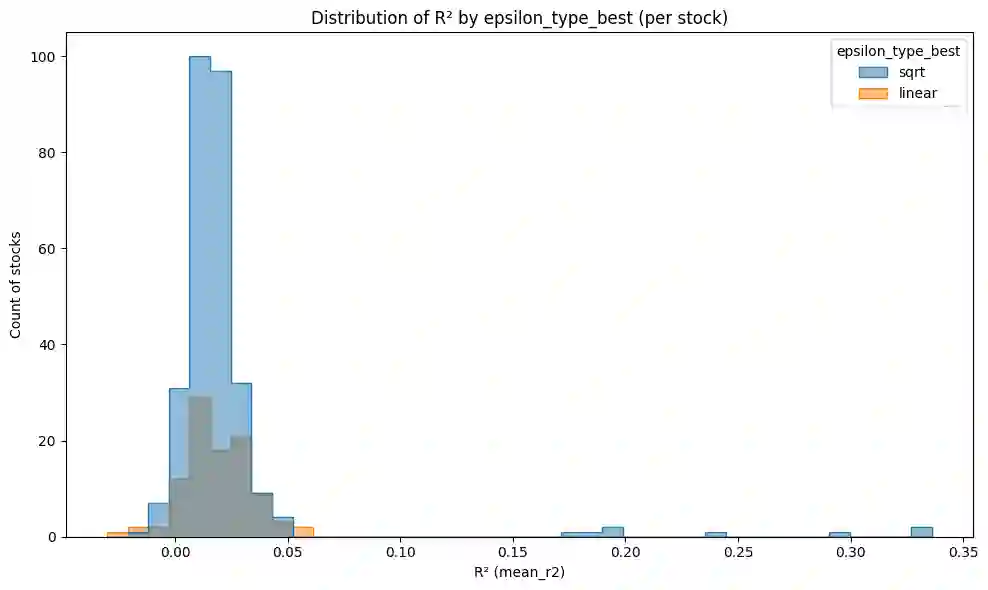
We present the first application of MAP-Elites, a quality-diversity algorithm, to trade execution. Rather than searching for a single optimal policy, MAP-Elites generates a diverse portfolio of regime-specialist strategies indexed by liquidity and volatility conditions. Individual specialists achieve 8-10% performance improvements within their behavioural niches, while other cells show degradation, suggesting opportunities for ensemble approaches that combine improved specialists with the baseline PPO policy. Results indicate that quality-diversity methods offer promise for regime-adaptive execution, though substantial computational resources per behavioural cell may be required for robust specialist development across all market conditions. To ensure experimental integrity, we develop a calibrated Gymnasium environment focused on order scheduling rather than tactical placement decisions. The simulator features a transient impact model with exponential decay and square-root volume scaling, fit to 400+ U.S. equities with R^2>0.02 out-of-sample. Within this environment, two Proximal Policy Optimization architectures - both MLP and CNN feature extractors - demonstrate substantial improvements over industry baselines, with the CNN variant achieving 2.13 bps arrival slippage versus 5.23 bps for VWAP on 4,900 out-of-sample orders ($21B notional). These results validate both the simulation realism and provide strong single-policy baselines for quality-diversity methods.
翻译:本文首次将MAP-Elites这一质量多样性算法应用于交易执行领域。与寻找单一最优策略不同,MAP-Elites生成了一组多样化的、由流动性和波动率条件索引的机制专业化策略组合。个体专业化策略在其行为生态位内实现了8-10%的性能提升,而其他单元则表现出性能退化,这为将改进后的专业化策略与基线PPO策略相结合的集成方法提供了机会。结果表明,质量多样性方法为机制自适应执行提供了前景,尽管要在所有市场条件下实现稳健的专业化策略开发,每个行为单元可能需要大量的计算资源。为确保实验的完整性,我们开发了一个经过校准的Gymnasium环境,专注于订单调度而非战术性放置决策。该模拟器采用具有指数衰减和平方根成交量缩放特性的瞬态冲击模型,基于400多只美国股票数据进行拟合,样本外R^2>0.02。在此环境中,两种近端策略优化架构——包括MLP和CNN特征提取器——均展现出相对于行业基线的显著改进,其中CNN变体在4,900个样本外订单(名义价值210亿美元)上实现了2.13个基点的到达滑点,而VWAP策略为5.23个基点。这些结果既验证了模拟的真实性,也为质量多样性方法提供了强有力的单策略基线。