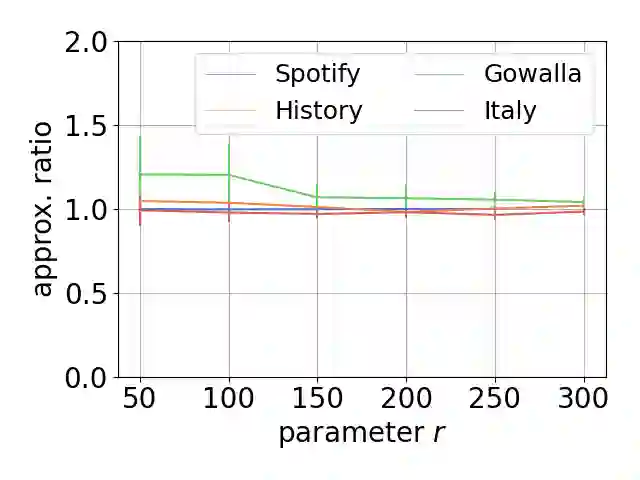
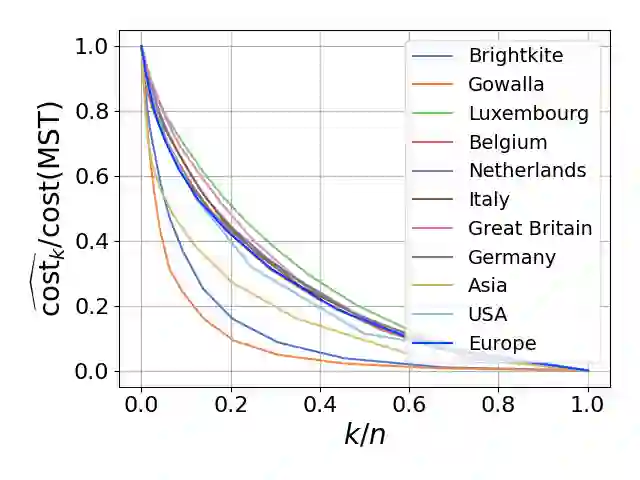
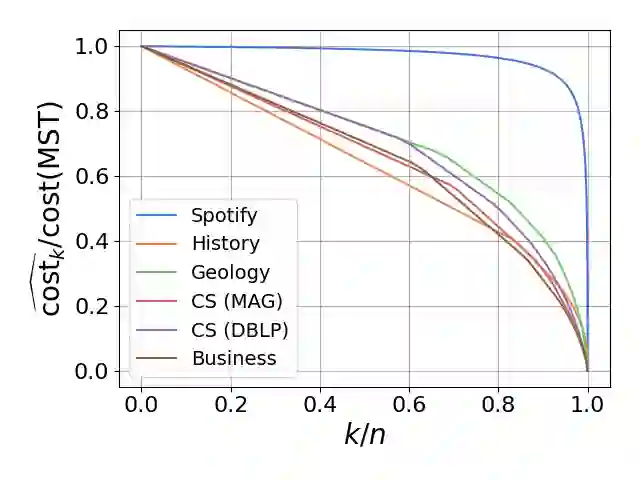
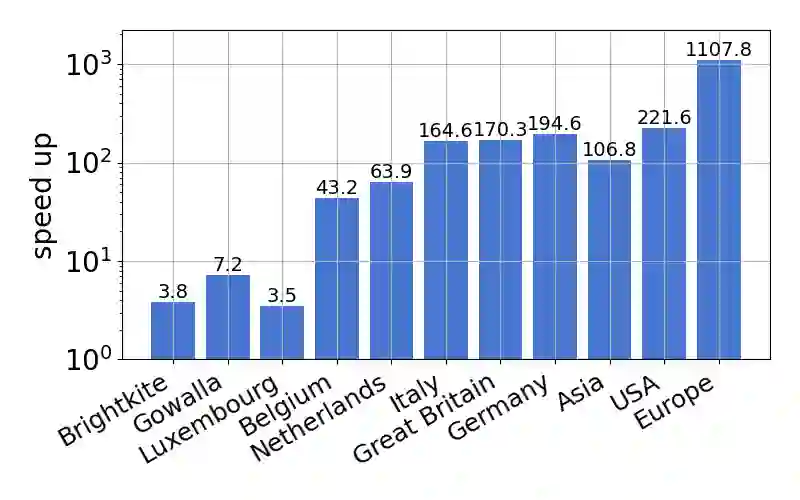
Single-linkage clustering is a fundamental method for data analysis. Algorithmically, one can compute a single-linkage $k$-clustering (a partition into $k$ clusters) by computing a minimum spanning tree and dropping the $k-1$ most costly edges. This clustering minimizes the sum of spanning tree weights of the clusters. This motivates us to define the cost of a single-linkage $k$-clustering as the weight of the corresponding spanning forest, denoted by $\mathrm{cost}_k$. Besides, if we consider single-linkage clustering as computing a hierarchy of clusterings, the total cost of the hierarchy is defined as the sum of the individual clusterings, denoted by $\mathrm{cost}(G) = \sum_{k=1}^{n} \mathrm{cost}_k$. In this paper, we assume that the distances between data points are given as a graph $G$ with average degree $d$ and edge weights from $\{1,\dots, W\}$. Given query access to the adjacency list of $G$, we present a sampling-based algorithm that computes a succinct representation of estimates $\widehat{\mathrm{cost}}_k$ for all $k$. The running time is $\tilde O(d\sqrt{W}/\varepsilon^3)$, and the estimates satisfy $\sum_{k=1}^{n} |\widehat{\mathrm{cost}}_k - \mathrm{cost}_k| \le \varepsilon\cdot \mathrm{cost}(G)$, for any $0<\varepsilon <1$. Thus we can approximate the cost of every $k$-clustering upto $(1+\varepsilon)$ factor \emph{on average}. In particular, our result ensures that we can estimate $\cost(G)$ upto a factor of $1\pm \varepsilon$ in the same running time. We also extend our results to the setting where edges represent similarities. In this case, the clusterings are defined by a maximum spanning tree, and our algorithms run in $\tilde{O}(dW/\varepsilon^3)$ time. We futher prove nearly matching lower bounds for estimating the total clustering cost and we extend our algorithms to metric space settings.
翻译:单链接聚类是一种基础的数据分析方法。从算法角度,可以通过计算最小生成树并删除代价最高的 $k-1$ 条边来计算单链接 $k$ 聚类(即划分为 $k$ 个簇)。这种聚类方式最小化了各簇生成树权重之和。这促使我们将单链接 $k$ 聚类的成本定义为对应生成森林的权重,记为 $\mathrm{cost}_k$。此外,若将单链接聚类视为计算聚类层次结构,则层次结构的总成本定义为各聚类成本之和,记为 $\mathrm{cost}(G) = \sum_{k=1}^{n} \mathrm{cost}_k$。本文假设数据点间的距离以平均度为 $d$、边权重取自 $\{1,\dots, W\}$ 的图 $G$ 给出。在拥有对 $G$ 邻接表的查询访问权限的前提下,我们提出一种基于采样的算法,可为所有 $k$ 值计算估计值 $\widehat{\mathrm{cost}}_k$ 的简洁表示。算法运行时间为 $\tilde O(d\sqrt{W}/\varepsilon^3)$,且估计值满足 $\sum_{k=1}^{n} |\widehat{\mathrm{cost}}_k - \mathrm{cost}_k| \le \varepsilon\cdot \mathrm{cost}(G)$(对任意 $0<\varepsilon <1$)。因此我们能够以 $(1+\varepsilon)$ 因子在平均意义上近似每个 $k$ 聚类的成本。特别地,我们的结果保证可在相同运行时间内以 $1\pm \varepsilon$ 因子估计 $\cost(G)$。我们还将结果扩展到边表示相似度的场景:此时聚类由最大生成树定义,算法运行时间为 $\tilde{O}(dW/\varepsilon^3)$。我们进一步证明了估计总聚类成本的近乎匹配的下界,并将算法扩展至度量空间场景。