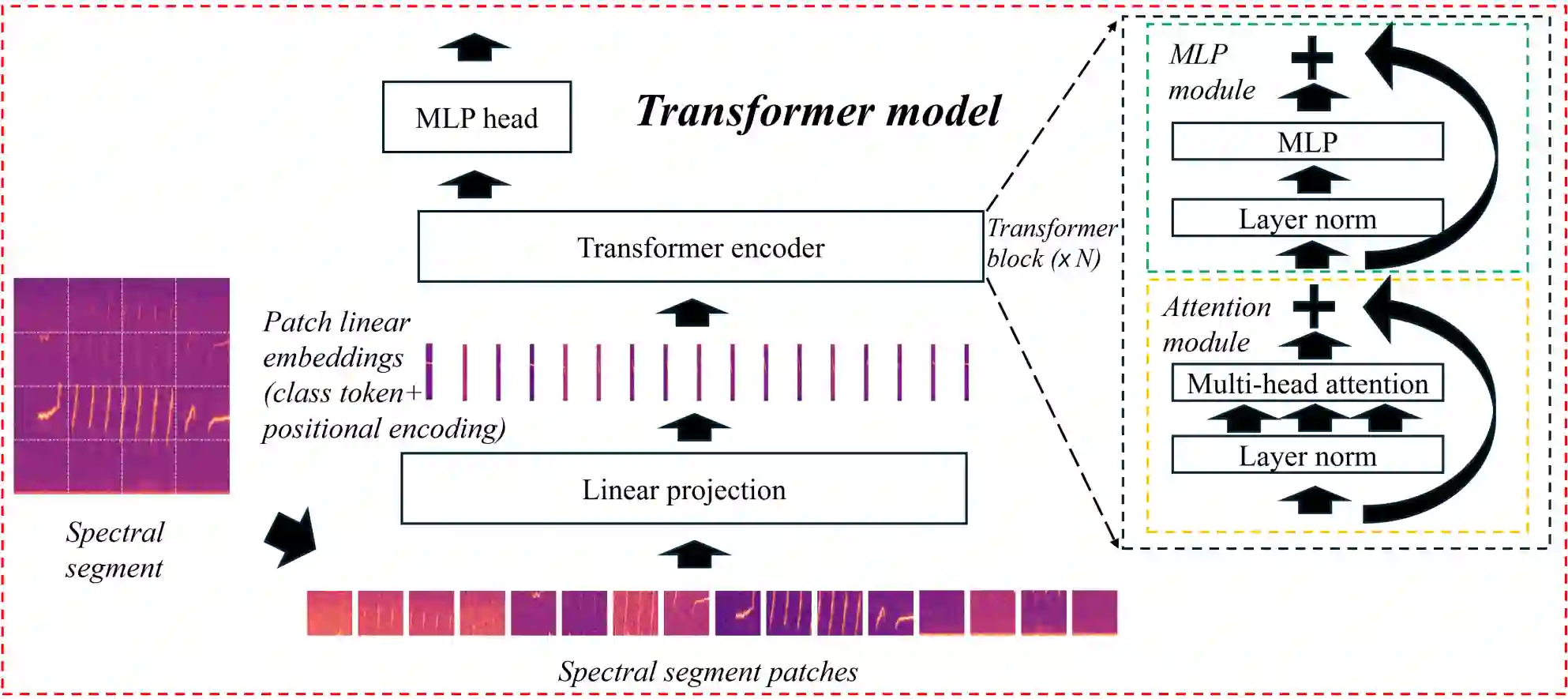
Marmoset, a highly vocalized primate, has become a popular animal model for studying social-communicative behavior and its underlying mechanism. In the study of vocal communication, it is vital to know the caller identities, call contents, and vocal exchanges. Previous work of a CNN has achieved a joint model for call segmentation, classification, and caller identification for marmoset vocalizations. However, the CNN has limitations in modeling long-range acoustic patterns; the Transformer architecture that has been shown to outperform CNNs, utilizes the self-attention mechanism that efficiently segregates information parallelly over long distances and captures the global structure of marmoset vocalization. We propose using the Transformer to jointly segment and classify the marmoset calls and identify the callers for each vocalization.
翻译:狨猴作为一种高度发声的灵长类动物,已成为研究社会交流行为及其潜在机制的常用动物模型。在发声交流研究中,明确发声者身份、叫声内容及声音交互至关重要。先前基于CNN的研究已实现狨猴发声的叫声分割、分类与发声者识别的联合建模。然而,CNN在建模长程声学模式方面存在局限;Transformer架构通过自注意力机制,能够高效并行处理长距离信息并捕捉狨猴发声的全局结构特征,其性能已被证实优于CNN。本研究提出采用Transformer架构,对狨猴叫声进行同步分割与分类,并对每段发声进行发声者识别。