
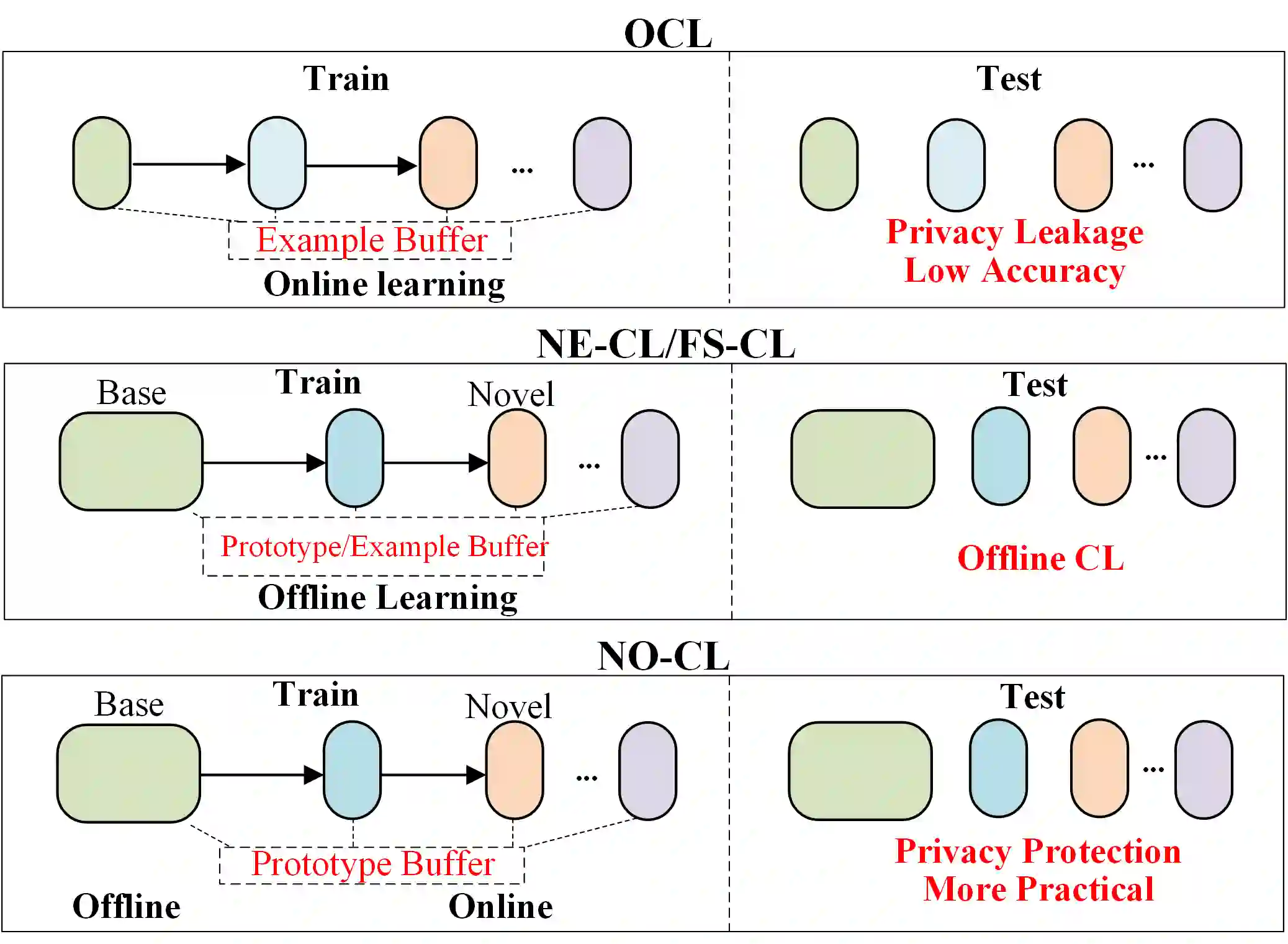
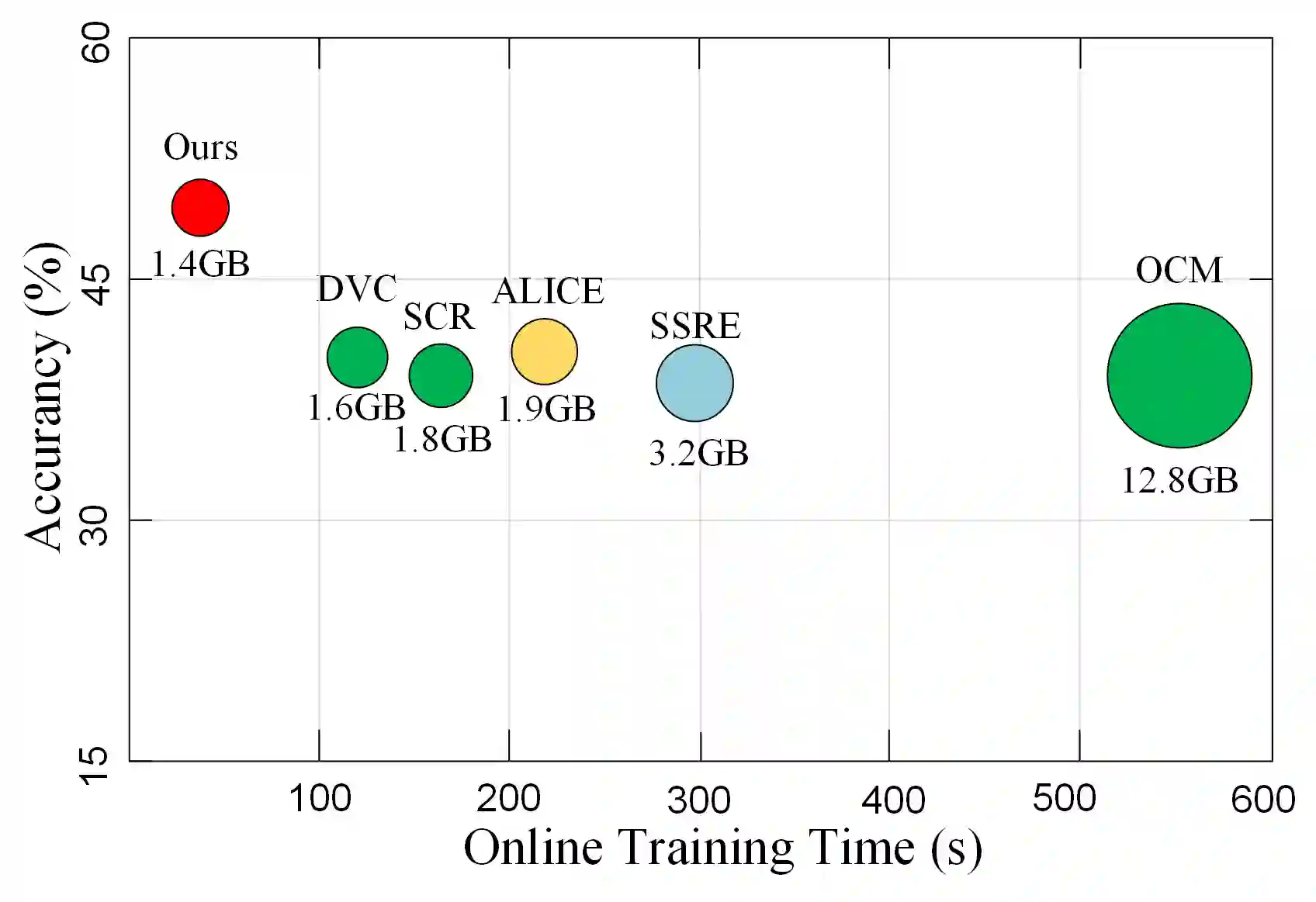
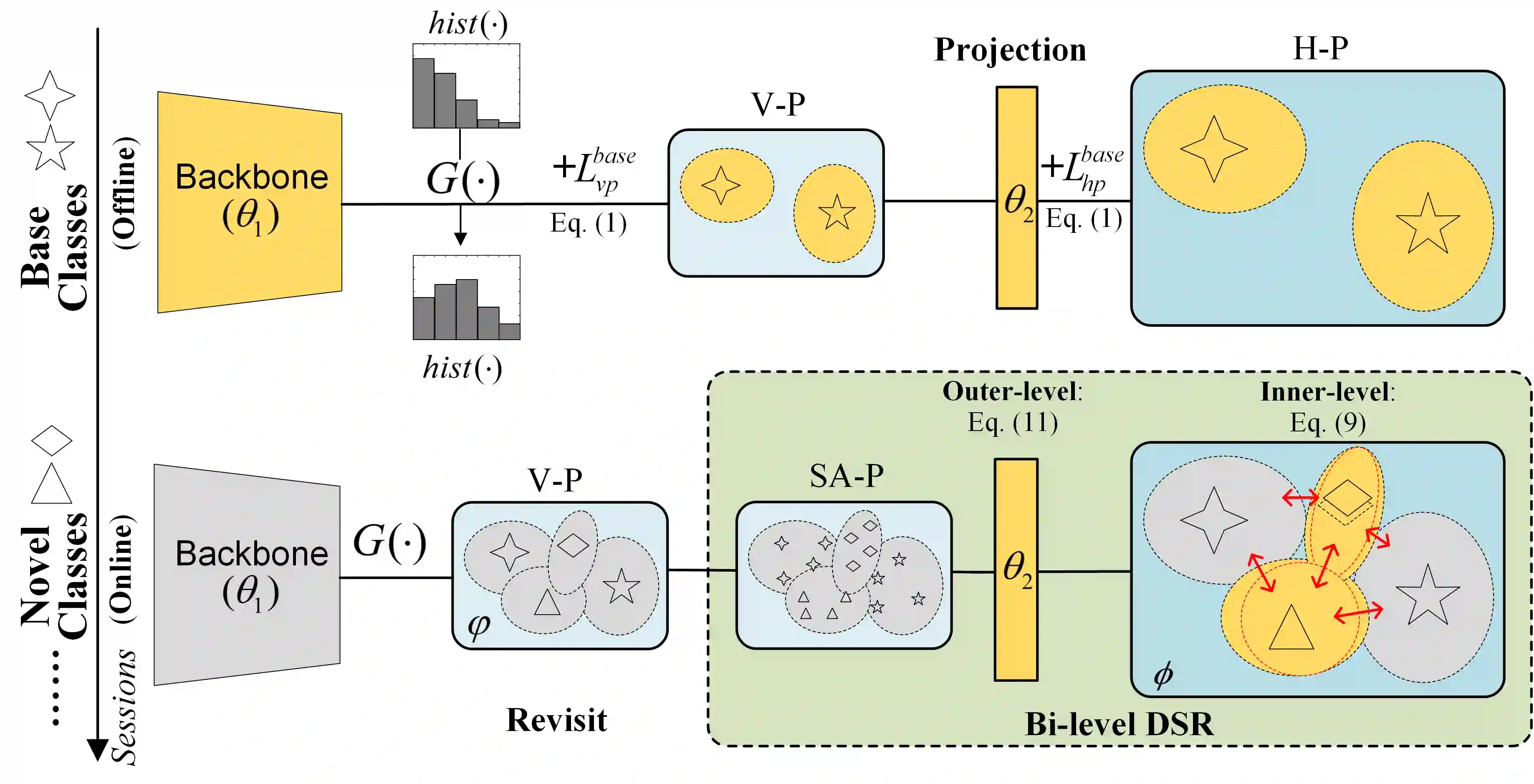
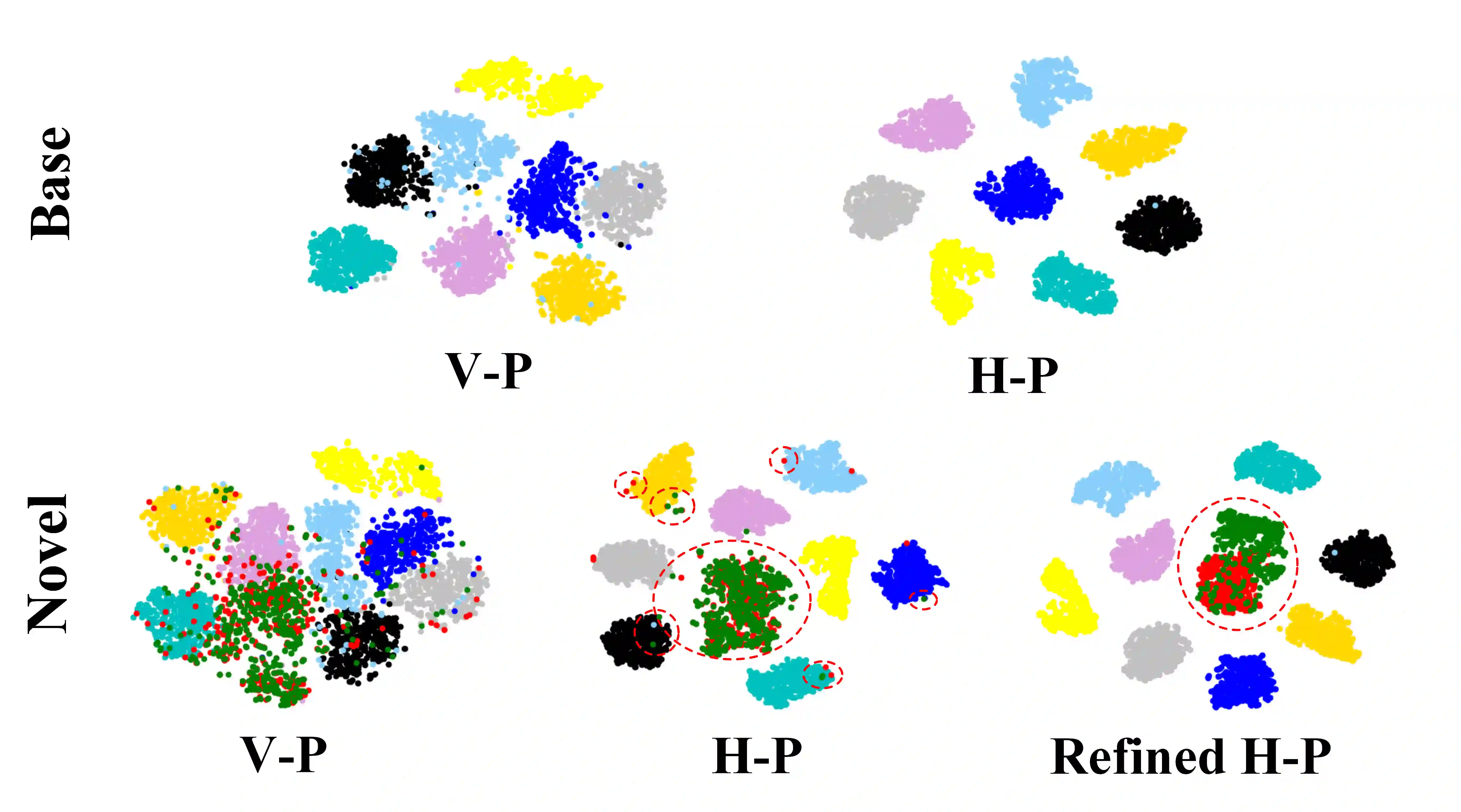
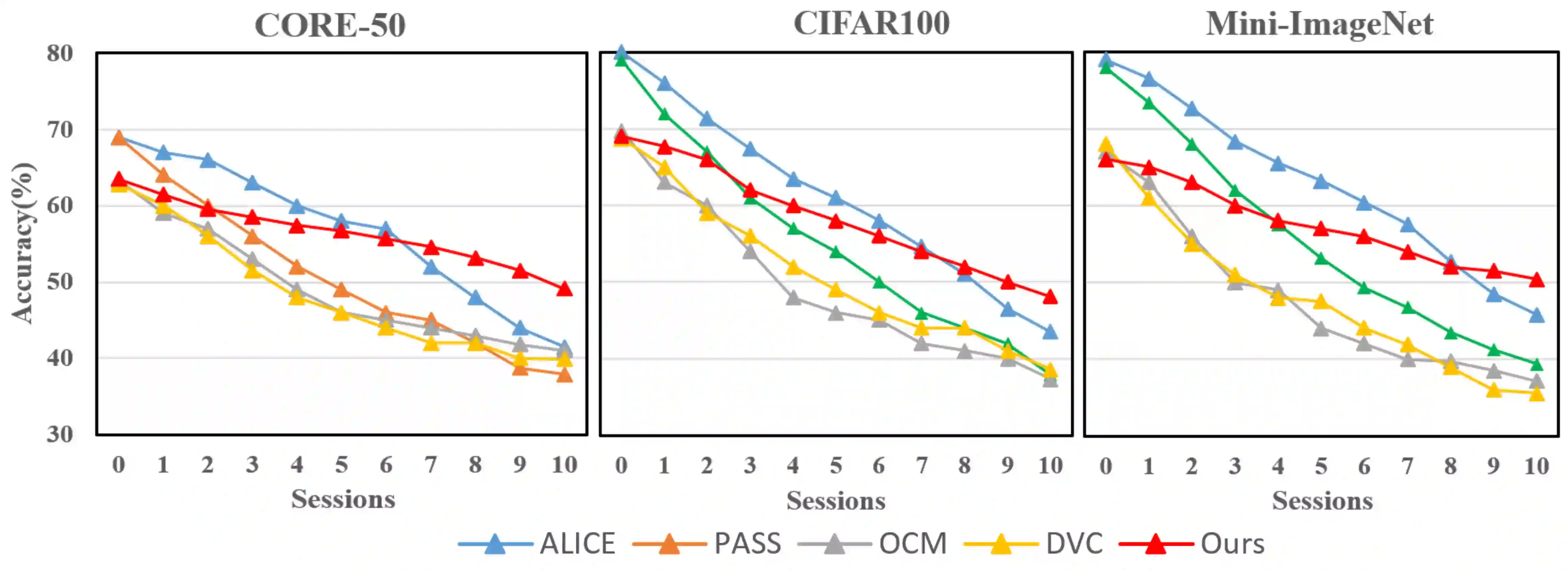
This paper investigates a new, practical, but challenging problem named Non-exemplar Online Class-incremental continual Learning (NO-CL), which aims to preserve the discernibility of base classes without buffering data examples and efficiently learn novel classes continuously in a single-pass (i.e., online) data stream. The challenges of this task are mainly two-fold: (1) Both base and novel classes suffer from severe catastrophic forgetting as no previous samples are available for replay. (2) As the online data can only be observed once, there is no way to fully re-train the whole model, e.g., re-calibrate the decision boundaries via prototype alignment or feature distillation. In this paper, we propose a novel Dual-prototype Self-augment and Refinement method (DSR) for NO-CL problem, which consists of two strategies: 1) Dual class prototypes: vanilla and high-dimensional prototypes are exploited to utilize the pre-trained information and obtain robust quasi-orthogonal representations rather than example buffers for both privacy preservation and memory reduction. 2) Self-augment and refinement: Instead of updating the whole network, we optimize high-dimensional prototypes alternatively with the extra projection module based on self-augment vanilla prototypes, through a bi-level optimization problem. Extensive experiments demonstrate the effectiveness and superiority of the proposed DSR in NO-CL.
翻译:本文研究了一个新颖、实用但具有挑战性的问题——无样本在线类增量连续学习(NO-CL),其目标是在不缓存数据样本的前提下保持基类判别性,并在单次遍历(即在线)数据流中高效连续地学习新类别。该任务的挑战主要来自两方面:(1)基类和新类别均面临严重的灾难性遗忘问题,因为缺乏可供重放的先前样本;(2)由于在线数据仅能被观测一次,无法对整个模型进行充分重训练,例如通过原型对齐或特征蒸馏来重新校准决策边界。针对NO-CL问题,本文提出了一种新颖的双原型自增强与优化方法(DSR),包含两种策略:(1)双类原型:利用基础原型和高维原型来运用预训练信息,获得鲁棒的准正交表示,从而取代样本缓冲区,实现隐私保护和内存缩减;(2)自增强与优化:不更新整个网络,而是通过双层优化问题,基于自增强基础原型,交替优化高维原型与额外的投影模块。大量实验证明了所提DSR方法在NO-CL中的有效性和优越性。
相关内容

Source: Apple - iOS 8


