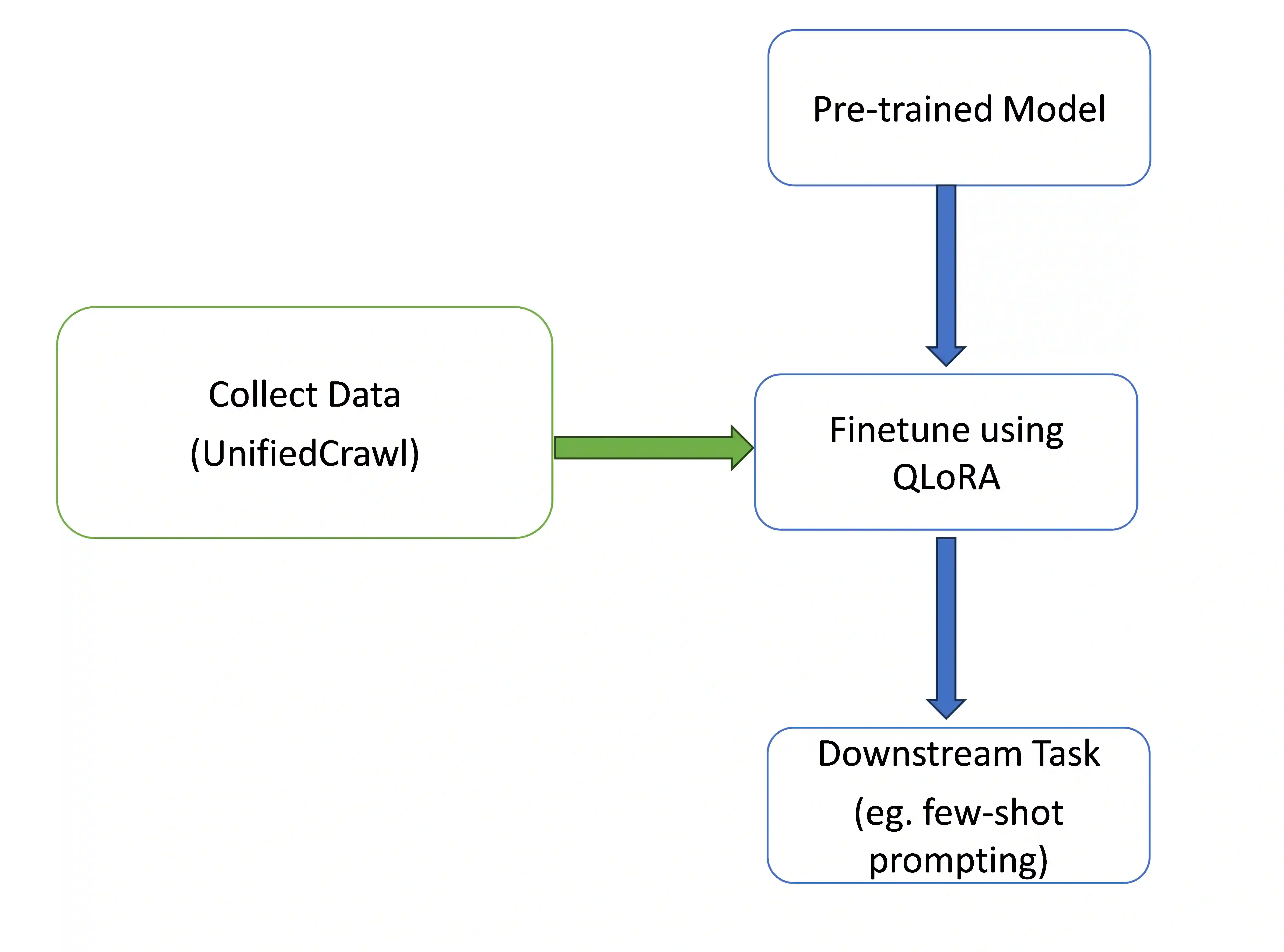
Large language models (LLMs) under-perform on low-resource languages due to limited training data. We present a method to efficiently collect text data for low-resource languages from the entire Common Crawl corpus. Our approach, UnifiedCrawl, filters and extracts common crawl using minimal compute resources, yielding mono-lingual datasets much larger than previously available sources. We demonstrate that leveraging this data to fine-tuning multilingual LLMs via efficient adapter methods (QLoRA) significantly boosts performance on the low-resource language, while minimizing VRAM usage. Our experiments show large improvements in language modeling perplexity and an increase in few-shot prompting scores. Our work and released source code provide an affordable approach to improve LLMs for low-resource languages using consumer hardware. Our source code is available here at https://github.com/bethelmelesse/unifiedcrawl.
翻译:大语言模型(LLMs)因训练数据有限而在低资源语言上表现不佳。本文提出一种方法,可从整个Common Crawl语料库中高效收集低资源语言的文本数据。我们的方法UnifiedCrawl使用极少的计算资源对Common Crawl进行过滤和提取,从而获得比以往可用来源规模大得多的单语数据集。我们证明,通过高效适配器方法(QLoRA)利用该数据对多语言大语言模型进行微调,可显著提升其在低资源语言上的性能,同时最大限度降低显存使用量。实验结果表明,该方法在语言建模困惑度上带来大幅改善,并提升了少样本提示的得分。我们的工作及开源代码提供了一种利用消费级硬件改进低资源语言大语言模型的低成本途径。源代码发布于:https://github.com/bethelmelesse/unifiedcrawl。