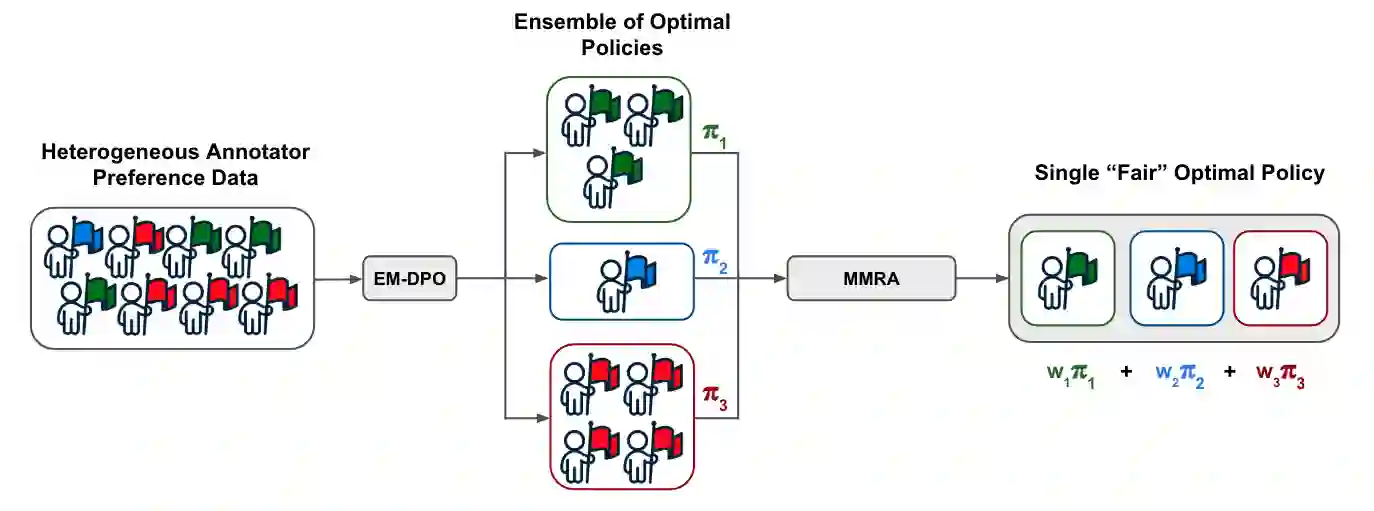
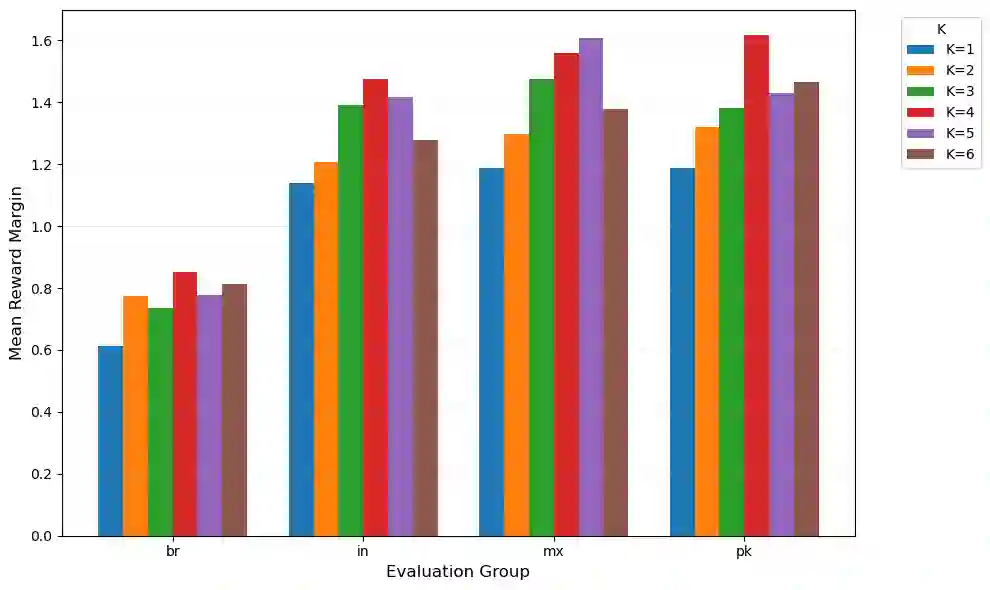
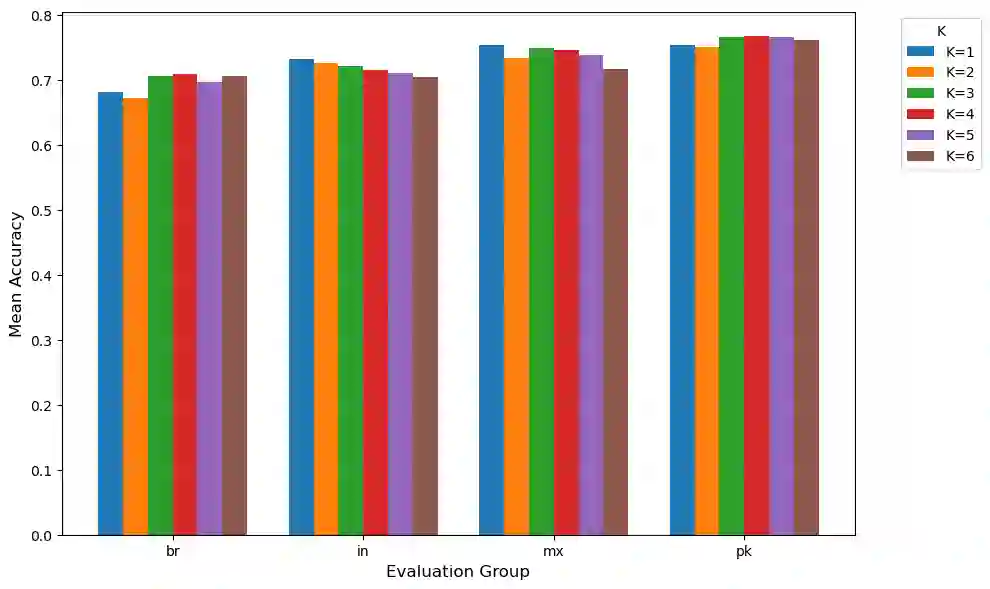
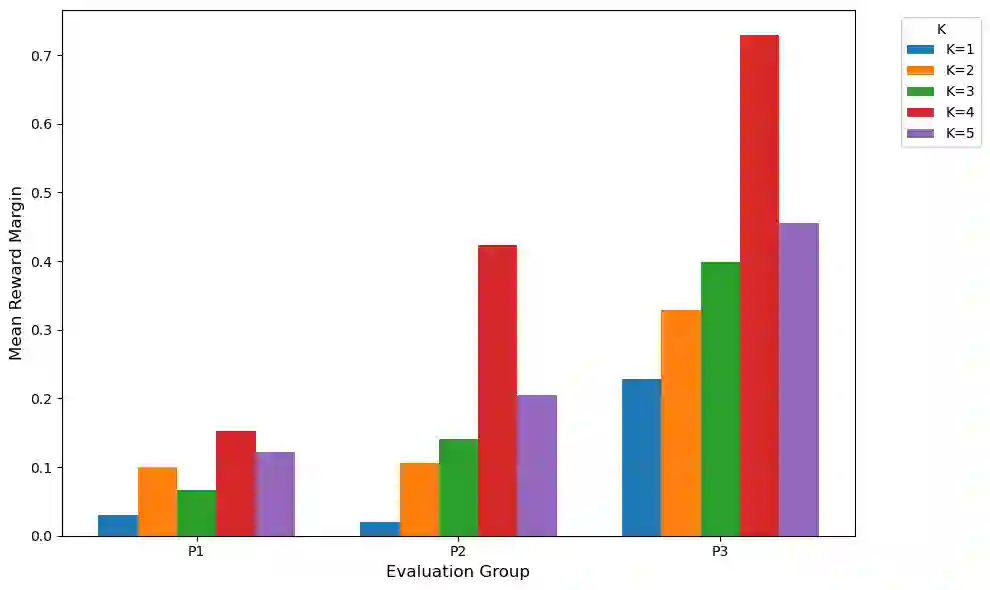
Reinforcement Learning from Human Feedback (RLHF) has become central to aligning large language models with human values, typically by first learning a reward model from preference data which is then used to update the model with reinforcement learning. Recent alternatives such as Direct Preference Optimization (DPO) simplify this pipeline by directly optimizing on preferences. However, both approaches often assume uniform annotator preferences and rely on binary comparisons, overlooking two key limitations: the diversity of human evaluators and the limitations of pairwise feedback. In this work, we address both these issues. First, we connect preference learning in RLHF with the econometrics literature and show that binary comparisons are insufficient for identifying latent user preferences from finite user data and infinite users, while (even incomplete) rankings over three or more responses ensure identifiability. Second, we introduce methods to incorporate heterogeneous preferences into alignment algorithms. We develop an Expectation-Maximization adaptation of DPO that discovers latent annotator types and trains a mixture of LLMs accordingly. Then we propose an aggregation algorithm using a min-max regret fairness criterion to produce a single generative policy with equitable performance guarantees. Together, these contributions establish a theoretical and algorithmic framework for fairness and personalization for diverse users in generative model alignment.
翻译:基于人类反馈的强化学习(RLHF)已成为将大型语言模型与人类价值观对齐的核心方法,通常首先从偏好数据中学习奖励模型,随后利用强化学习更新模型。近期提出的替代方法(如直接偏好优化(DPO))通过直接在偏好数据上进行优化来简化这一流程。然而,这两种方法通常假设标注者偏好一致且依赖二元比较,忽视了两个关键局限:人类评估者的多样性以及成对反馈的局限性。本研究同时解决了这两个问题。首先,我们将RLHF中的偏好学习与计量经济学文献相关联,证明在有限用户数据和无限用户情境下,二元比较不足以识别潜在用户偏好,而对三个或更多回复的(即使是不完整的)排序能确保可识别性。其次,我们提出了将异质偏好融入对齐算法的方法。我们开发了DPO的期望最大化改进版本,能够发现潜在标注者类型并据此训练混合大型语言模型。随后,我们提出了一种基于最小最大遗憾公平准则的聚合算法,以生成具有公平性能保证的单一生成策略。这些贡献共同构建了一个面向生成模型对齐中多样化用户的公平性与个性化理论及算法框架。