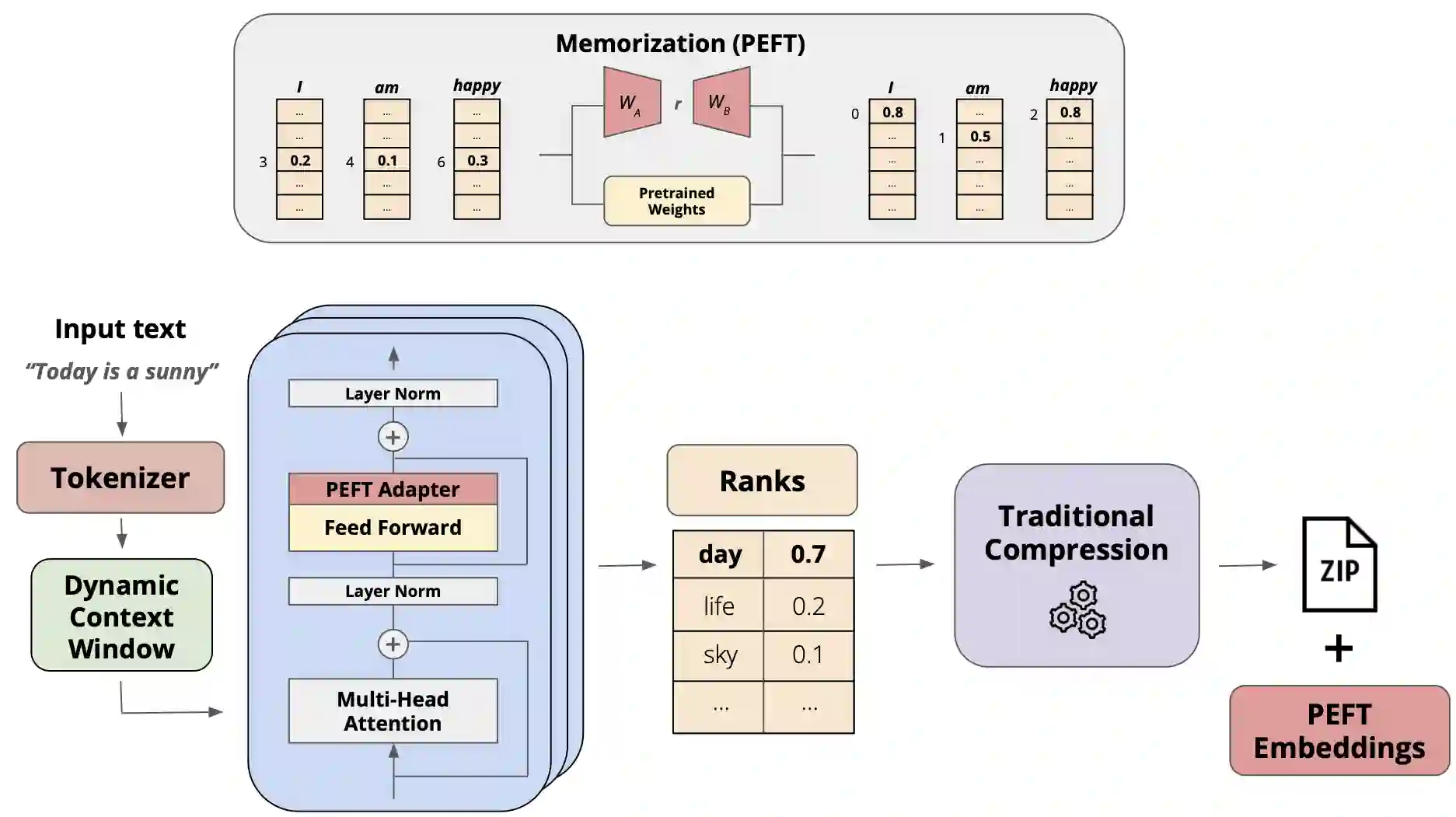
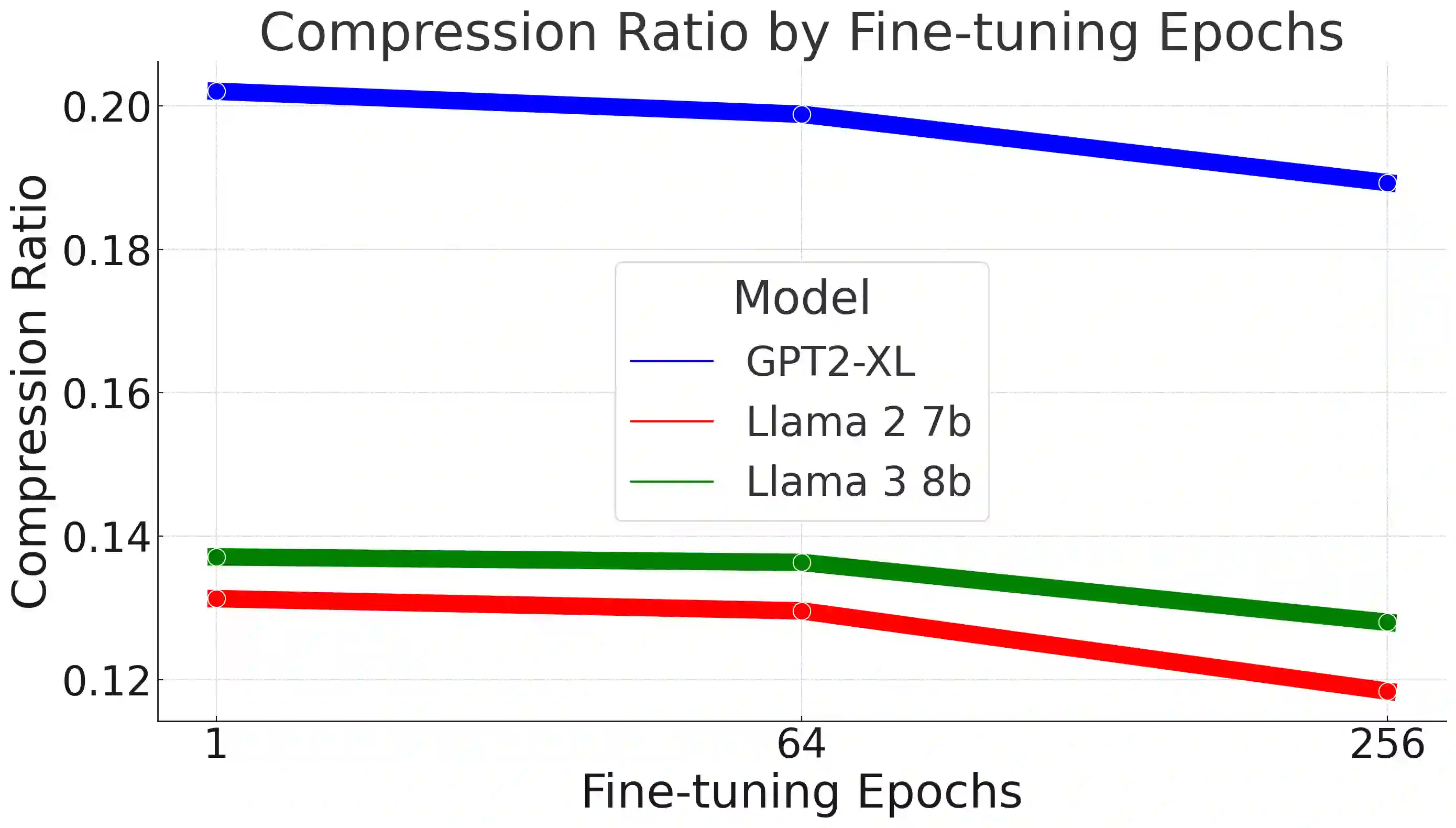
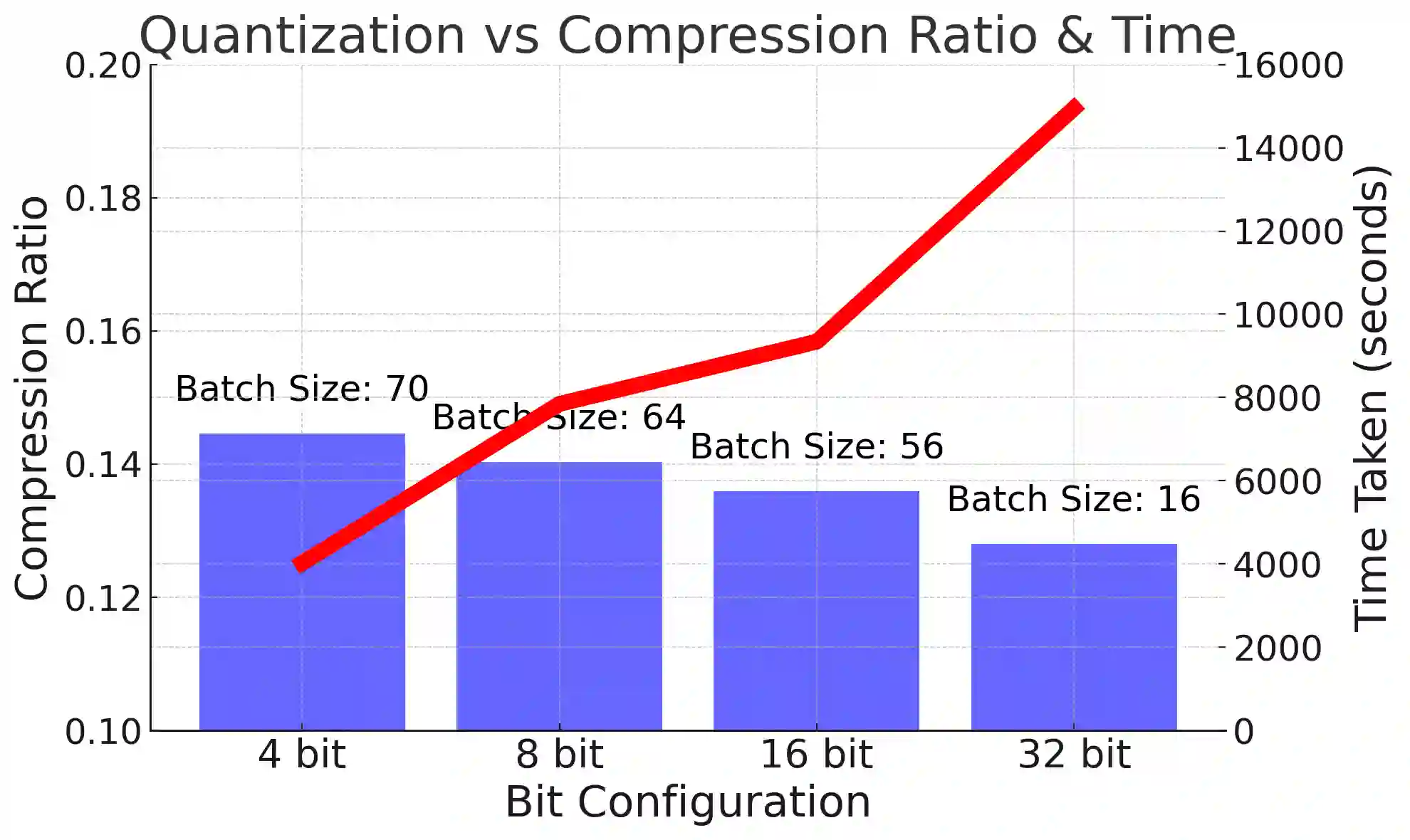
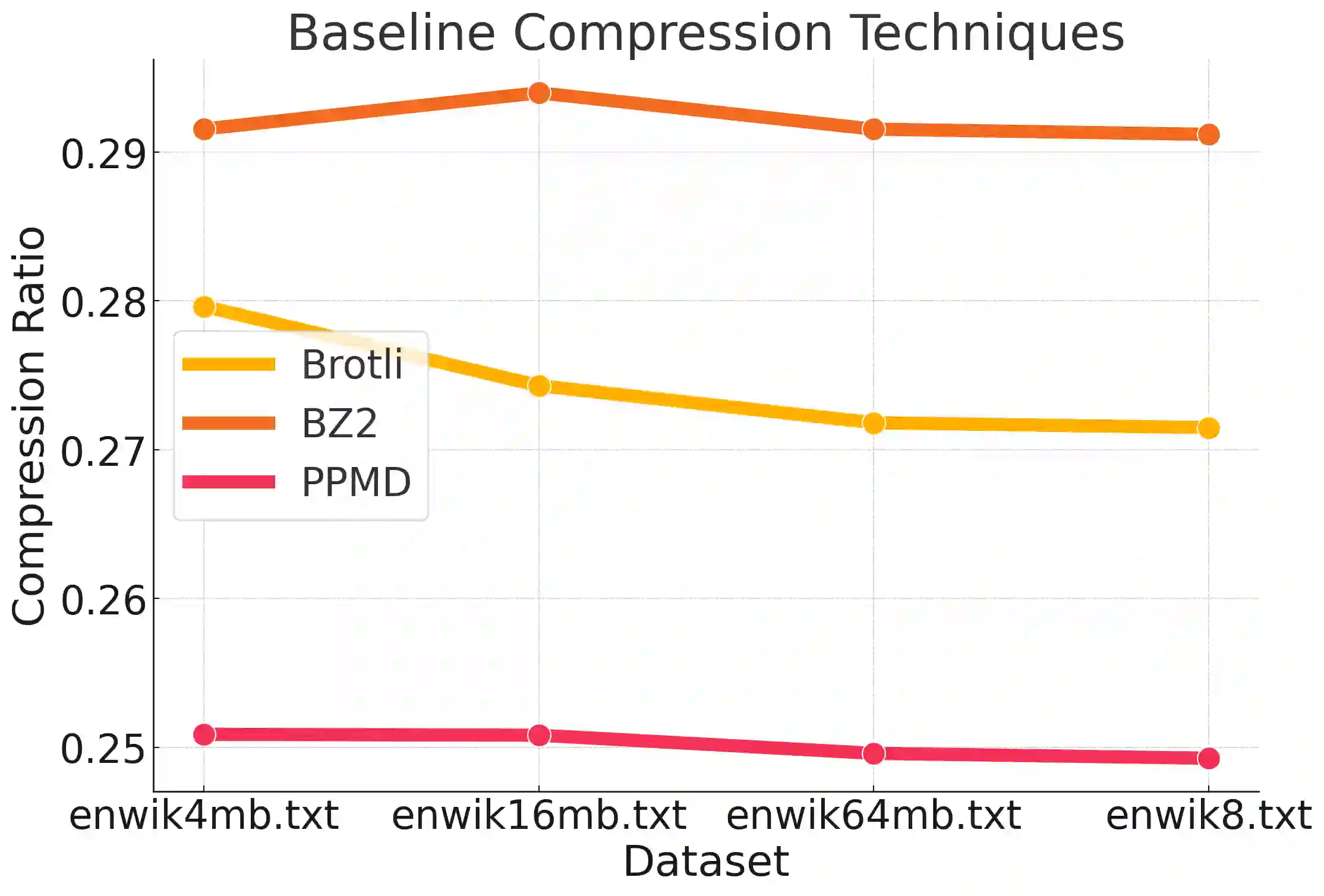
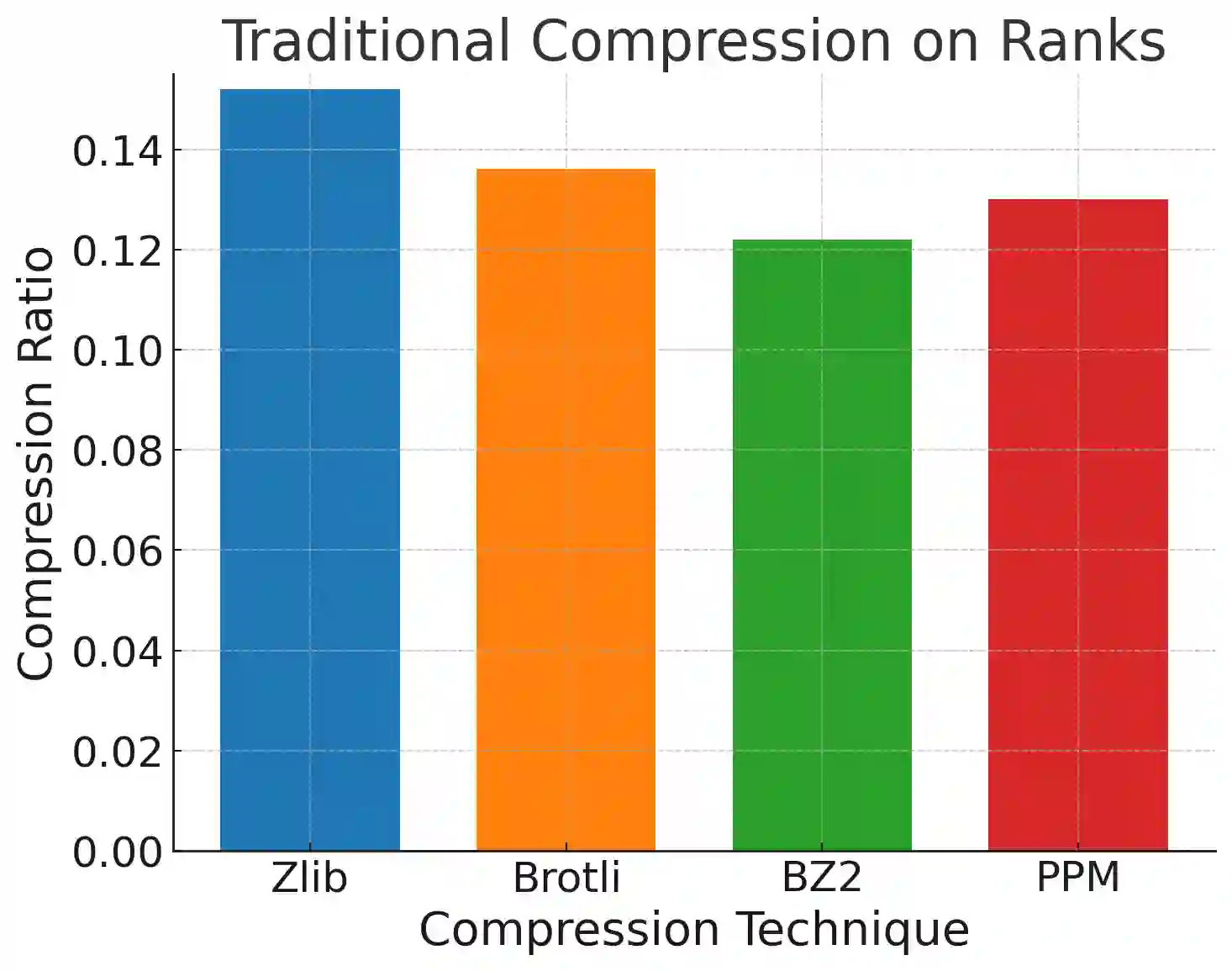
While the language modeling objective has been shown to be deeply connected with compression, it is surprising that modern LLMs are not employed in practical text compression systems. In this paper, we provide an in-depth analysis of neural network and transformer-based compression techniques to answer this question. We compare traditional text compression systems with neural network and LLM-based text compression methods. Although LLM-based systems significantly outperform conventional compression methods, they are highly impractical. Specifically, LLMZip, a recent text compression system using Llama3-8B requires 9.5 days to compress just 10 MB of text, although with huge improvements in compression ratios. To overcome this, we present FineZip - a novel LLM-based text compression system that combines ideas of online memorization and dynamic context to reduce the compression time immensely. FineZip can compress the above corpus in approximately 4 hours compared to 9.5 days, a 54 times improvement over LLMZip and comparable performance. FineZip outperforms traditional algorithmic compression methods with a large margin, improving compression ratios by approximately 50\%. With this work, we take the first step towards making lossless text compression with LLMs a reality. While FineZip presents a significant step in that direction, LLMs are still not a viable solution for large-scale text compression. We hope our work paves the way for future research and innovation to solve this problem.
翻译:尽管语言建模目标已被证明与压缩密切相关,但令人惊讶的是,现代大型语言模型并未应用于实际文本压缩系统。本文通过深入分析基于神经网络和Transformer的压缩技术来回答这一问题。我们比较了传统文本压缩系统与基于神经网络及大型语言模型的文本压缩方法。尽管基于大型语言模型的系统显著优于传统压缩方法,但其实际应用性极低。具体而言,近期使用Llama3-8B的文本压缩系统LLMZip需要9.5天才能压缩仅10MB的文本,尽管压缩率有巨大提升。为克服此问题,我们提出FineZip——一种基于大型语言模型的新型文本压缩系统,它结合在线记忆与动态上下文的思想,大幅缩短压缩时间。FineZip可在约4小时内压缩上述语料,相比LLMZip的9.5天实现了54倍的效率提升,同时保持相当的压缩性能。FineZip以显著优势超越传统算法压缩方法,将压缩率提升约50%。通过这项工作,我们朝着实现基于大型语言模型的无损文本压缩迈出了第一步。尽管FineZip在该方向上取得了重要进展,但大型语言模型仍非大规模文本压缩的可行解决方案。我们希望本研究能为未来解决这一问题的研究与创新铺平道路。