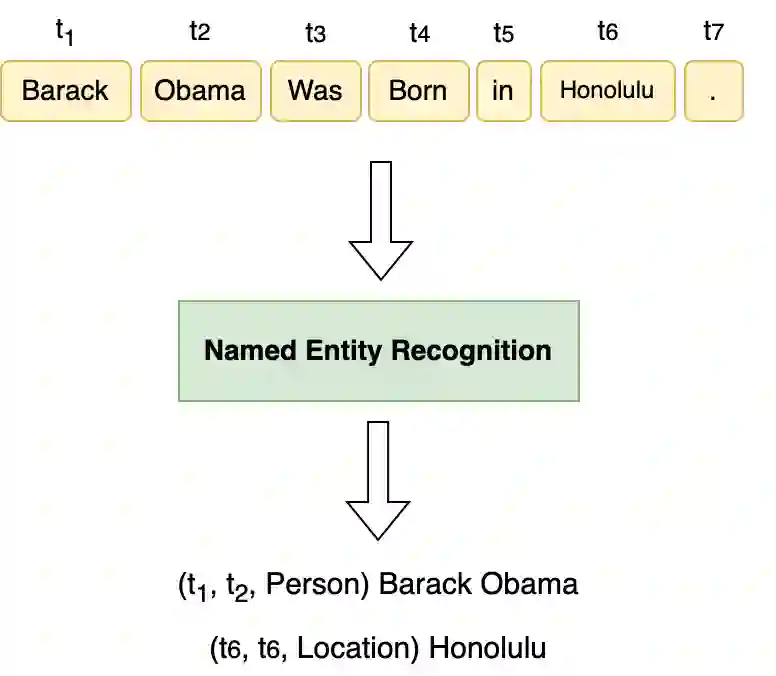
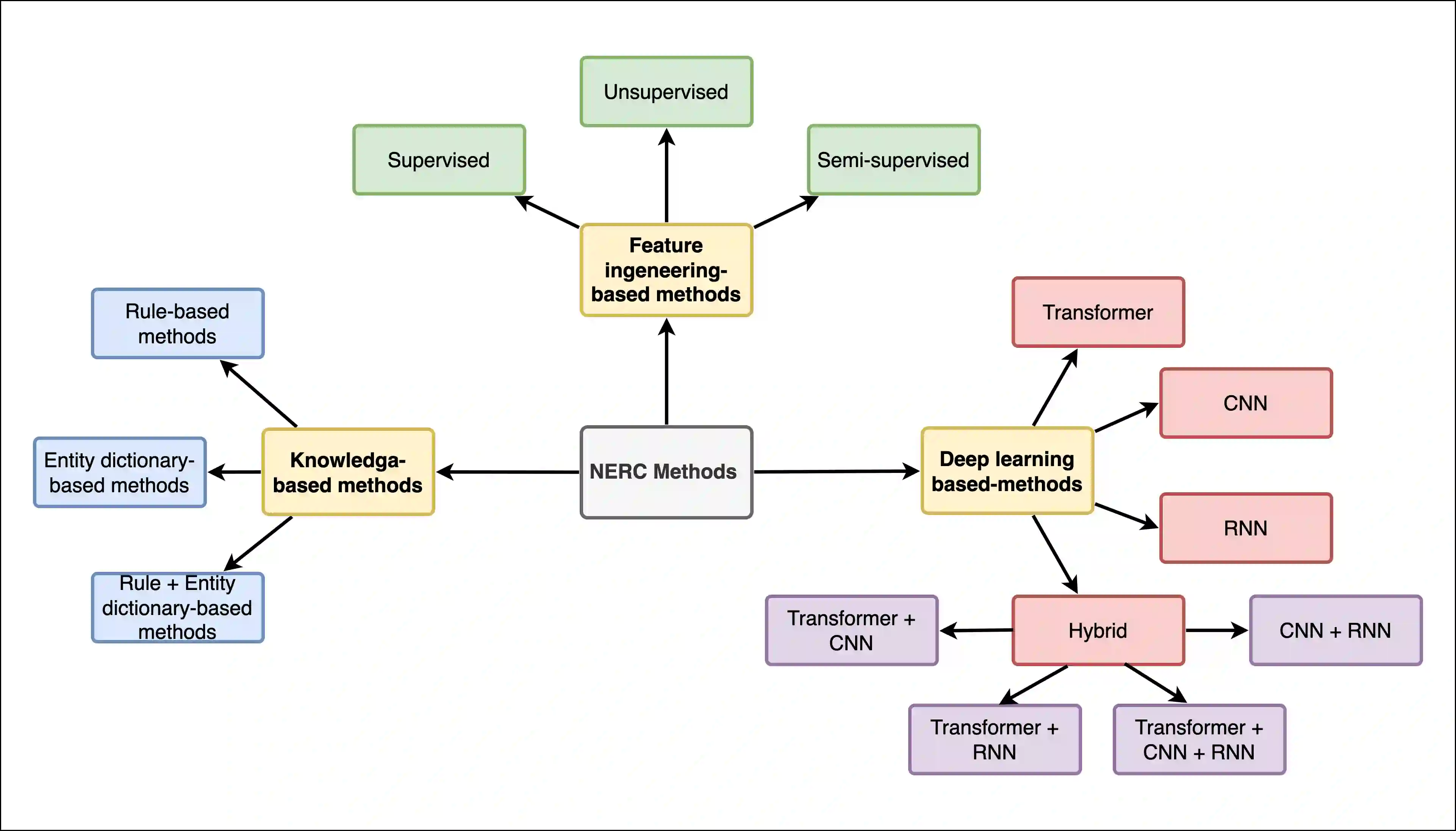
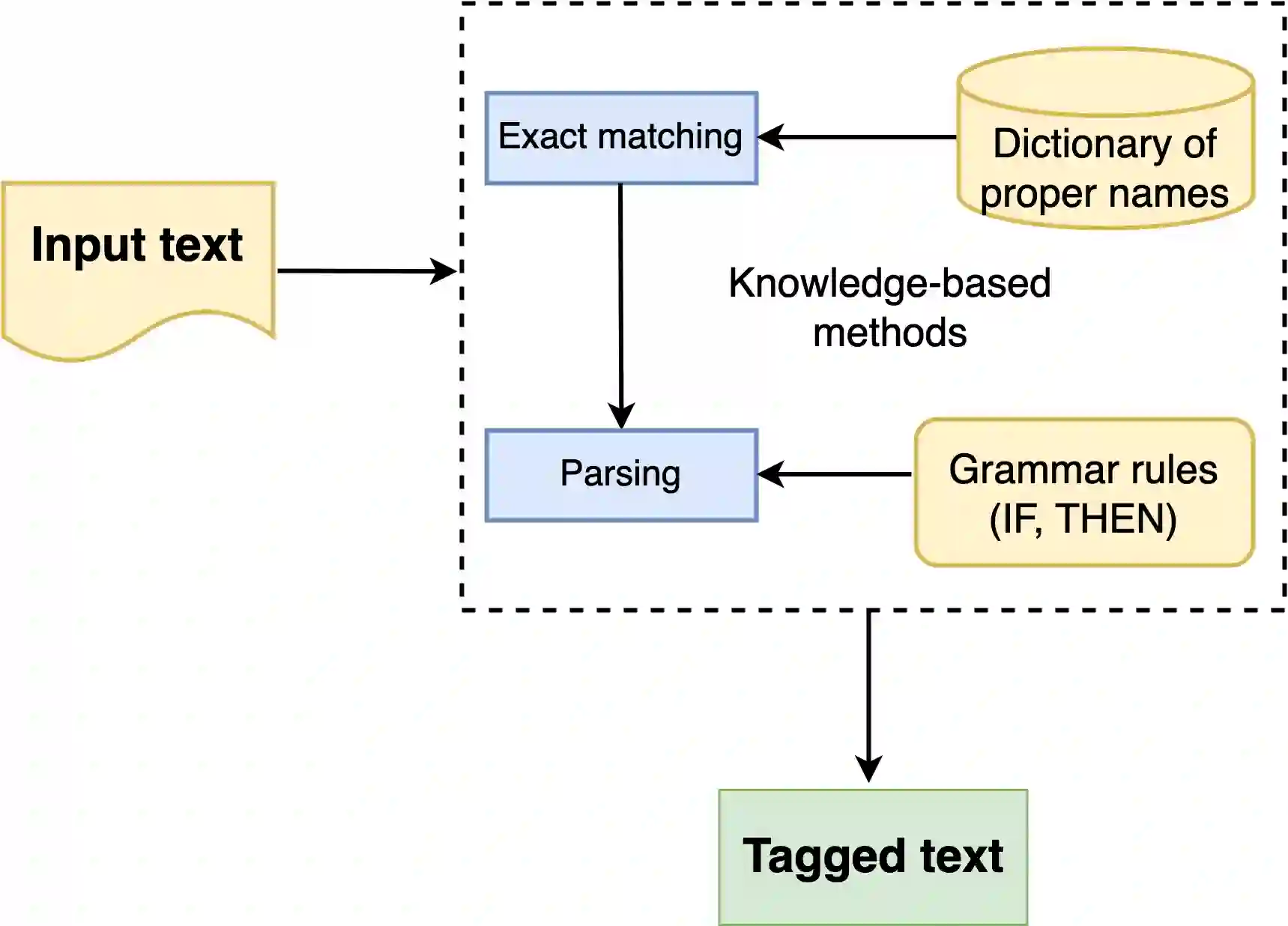
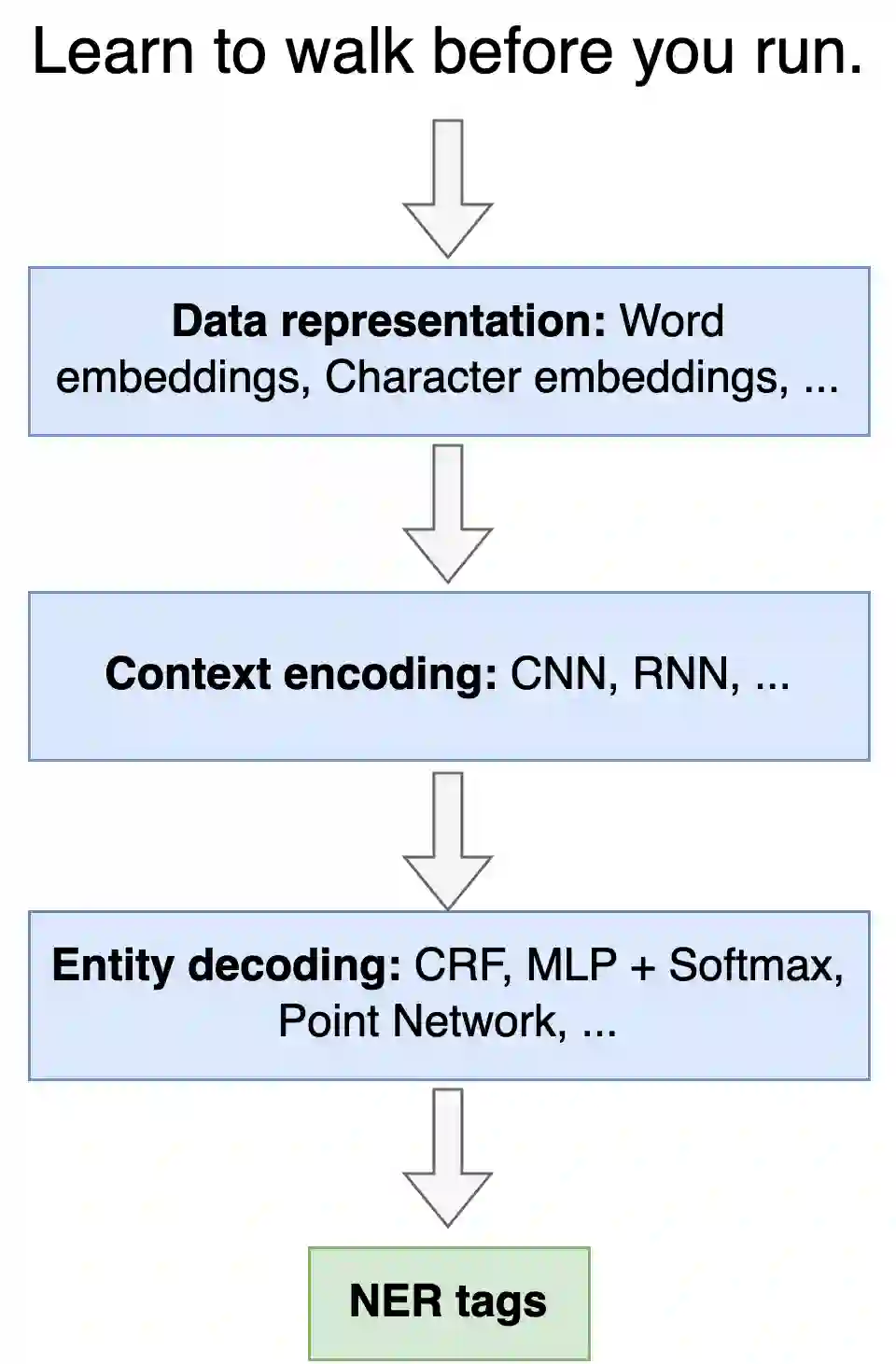
Named Entity Recognition seeks to extract substrings within a text that name real-world objects and to determine their type (for example, whether they refer to persons or organizations). In this survey, we first present an overview of recent popular approaches, but we also look at graph- and transformer- based methods including Large Language Models (LLMs) that have not had much coverage in other surveys. Second, we focus on methods designed for datasets with scarce annotations. Third, we evaluate the performance of the main NER implementations on a variety of datasets with differing characteristics (as regards their domain, their size, and their number of classes). We thus provide a deep comparison of algorithms that are never considered together. Our experiments shed some light on how the characteristics of datasets affect the behavior of the methods that we compare.
翻译:命名实体识别旨在从文本中提取指代现实世界对象的子串并确定其类型(例如,它们是否指涉人物或组织)。在本综述中,我们首先概述近期流行方法,同时关注图与基于Transformer的方法,包括在其他综述中较少涉及的大语言模型(LLMs)。其次,我们聚焦于针对标注稀缺数据集设计的方法。第三,我们在具有不同特征(涉及领域、规模及类别数量)的多个数据集上评估主要NER实现的性能。由此对通常不被共同考虑的算法进行深度比较。我们的实验揭示了数据集特征如何影响所比较方法的行为。