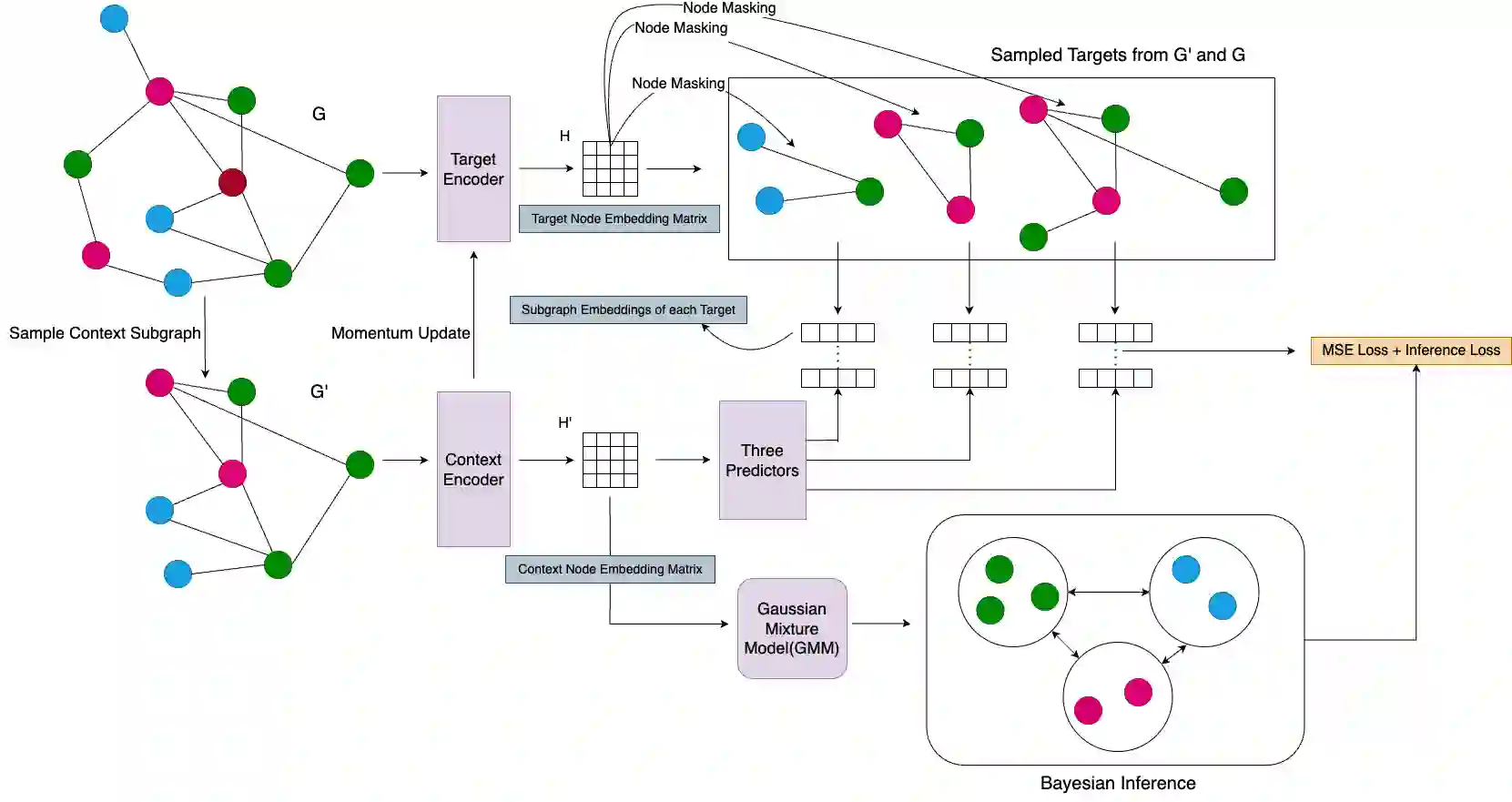
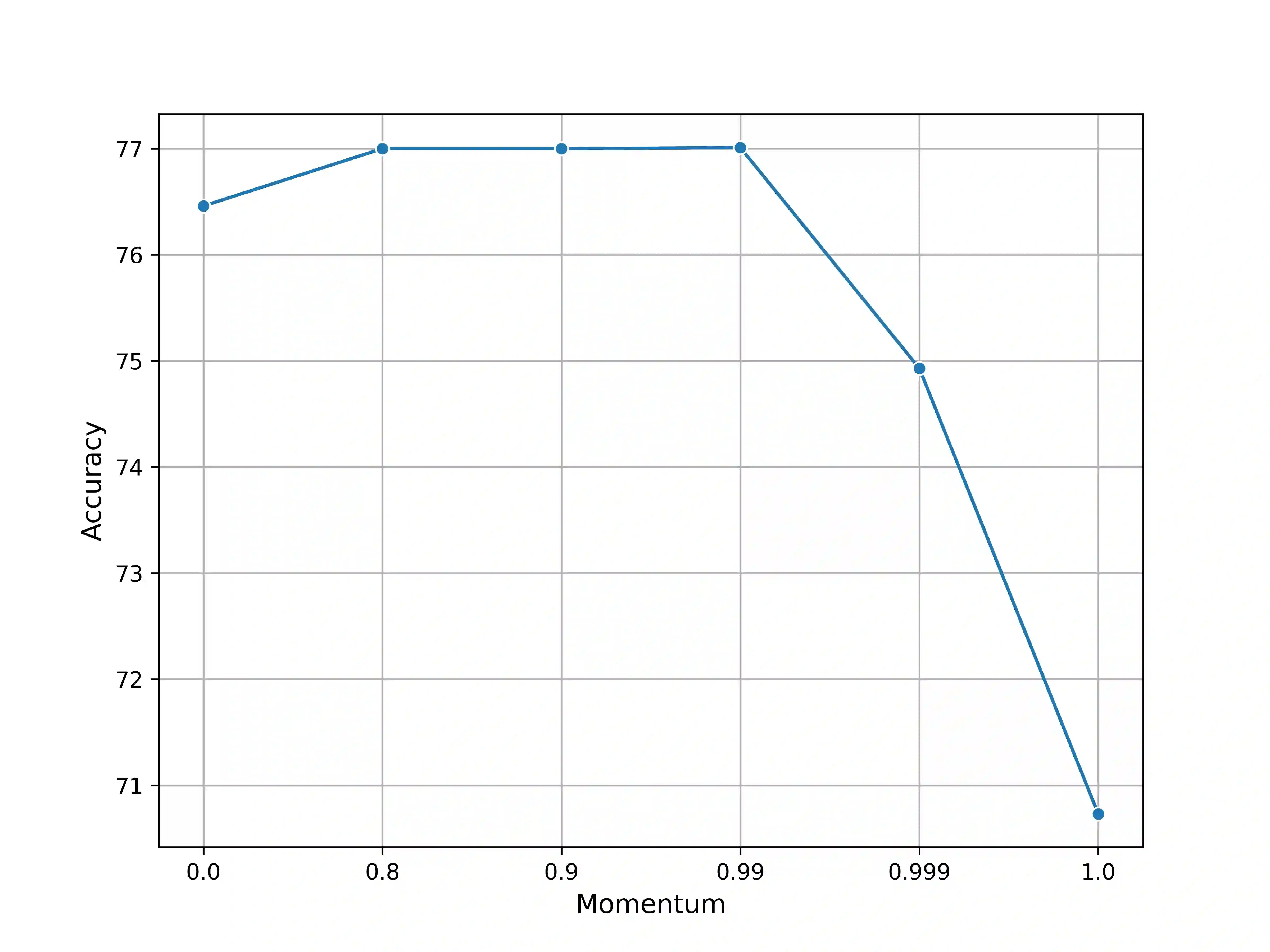
Graph representation learning has emerged as a cornerstone for tasks like node classification and link prediction, yet prevailing self-supervised learning (SSL) methods face challenges such as computational inefficiency, reliance on contrastive objectives, and representation collapse. Existing approaches often depend on feature reconstruction, negative sampling, or complex decoders, which introduce training overhead and hinder generalization. Further, current techniques which address such limitations fail to account for the contribution of node embeddings to a certain prediction in the absence of labeled nodes. To address these limitations, we propose a novel joint embedding predictive framework for graph SSL that eliminates contrastive objectives and negative sampling while preserving semantic and structural information. Additionally, we introduce a semantic-aware objective term that incorporates pseudo-labels derived from Gaussian Mixture Models (GMMs), enhancing node discriminability by evaluating latent feature contributions. Extensive experiments demonstrate that our framework outperforms state-of-the-art graph SSL methods across benchmarks, achieving superior performance without contrastive loss or complex decoders. Key innovations include (1) a non-contrastive, view-invariant joint embedding predictive architecture, (2) Leveraging single context and multiple targets relationship between subgraphs, and (3) GMM-based pseudo-label scoring to capture semantic contributions. This work advances graph SSL by offering a computationally efficient, collapse-resistant paradigm that bridges spatial and semantic graph features for downstream tasks. The code for our paper can be found at https://github.com/Deceptrax123/JPEB-GSSL
翻译:图表示学习已成为节点分类与链接预测等任务的基石,然而主流的自监督学习方法面临着计算效率低下、依赖对比目标以及表示坍缩等挑战。现有方法通常依赖于特征重构、负采样或复杂的解码器,这些会引入训练开销并阻碍泛化能力。此外,当前旨在解决这些局限性的技术未能考虑在缺乏标注节点的情况下,节点嵌入对特定预测的贡献。为应对这些局限,我们提出了一种新颖的联合嵌入预测框架用于图自监督学习,该框架在保留语义与结构信息的同时,消除了对比目标与负采样。此外,我们引入了一个语义感知的目标项,该目标项融合了源自高斯混合模型的伪标签,通过评估潜在特征的贡献来增强节点的可区分性。大量实验表明,我们的框架在多个基准测试中超越了当前最先进的图自监督学习方法,在不使用对比损失或复杂解码器的情况下实现了卓越的性能。关键创新包括:(1) 一种非对比的、视图不变的联合嵌入预测架构;(2) 利用子图间的单上下文与多目标关系;(3) 基于高斯混合模型的伪标签评分以捕捉语义贡献。这项工作通过提出一种计算高效、抗坍缩的范式,为下游任务桥接了空间与语义图特征,从而推动了图自监督学习的发展。本文代码可在 https://github.com/Deceptrax123/JPEB-GSSL 获取。