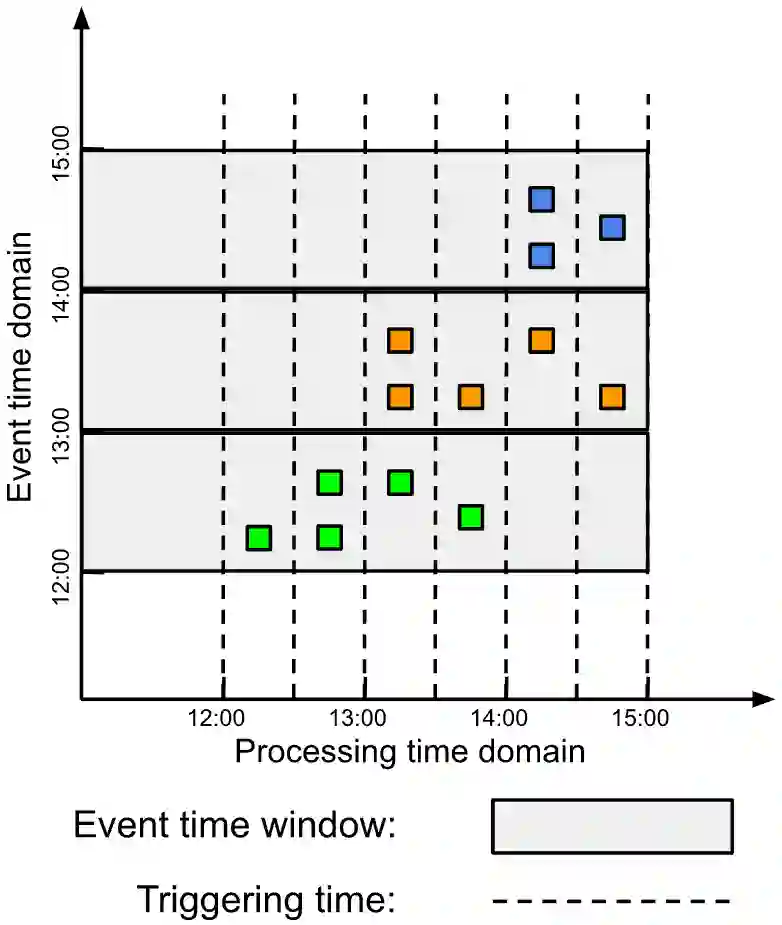
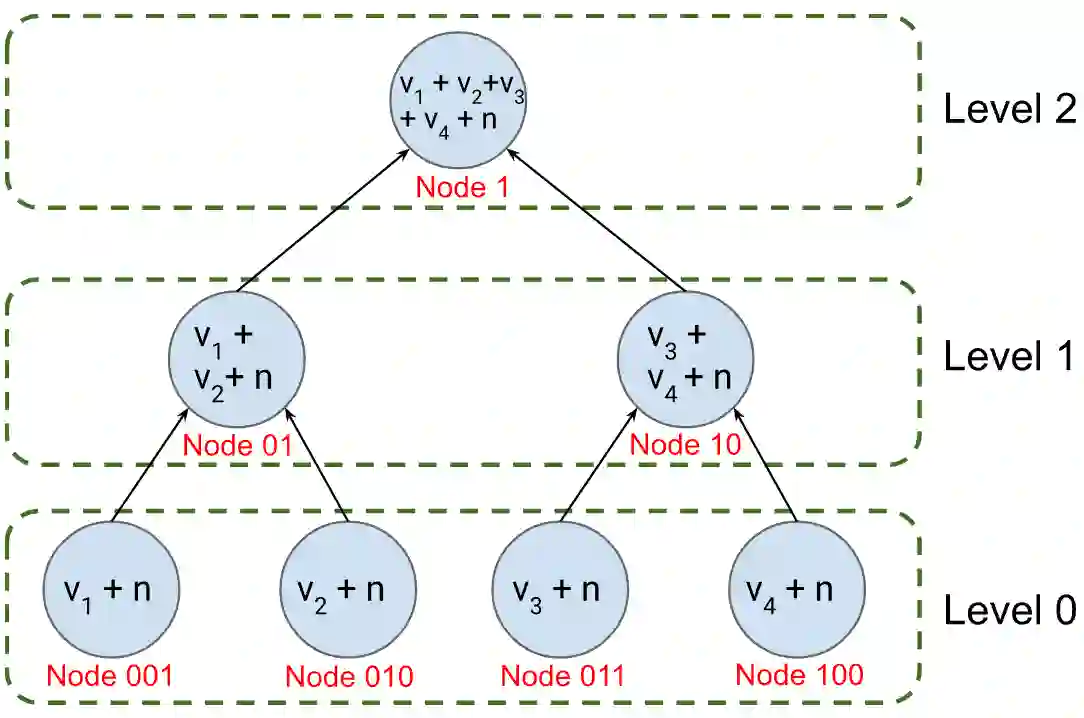
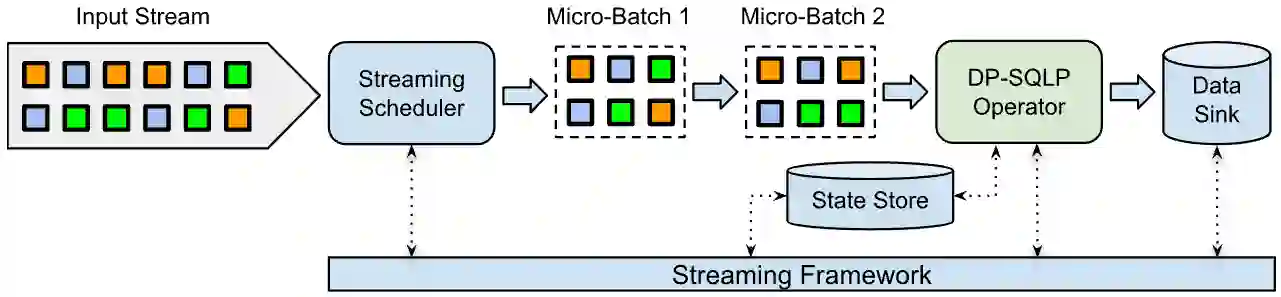
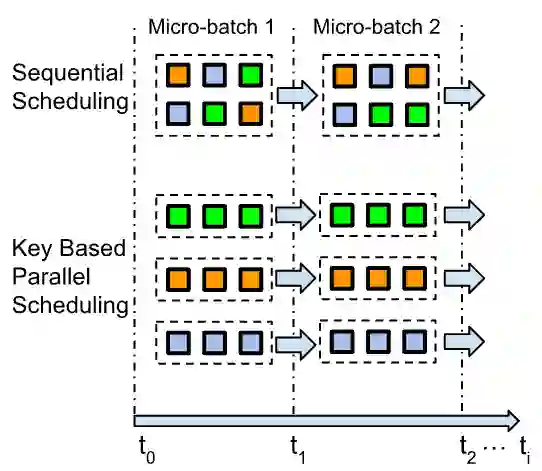
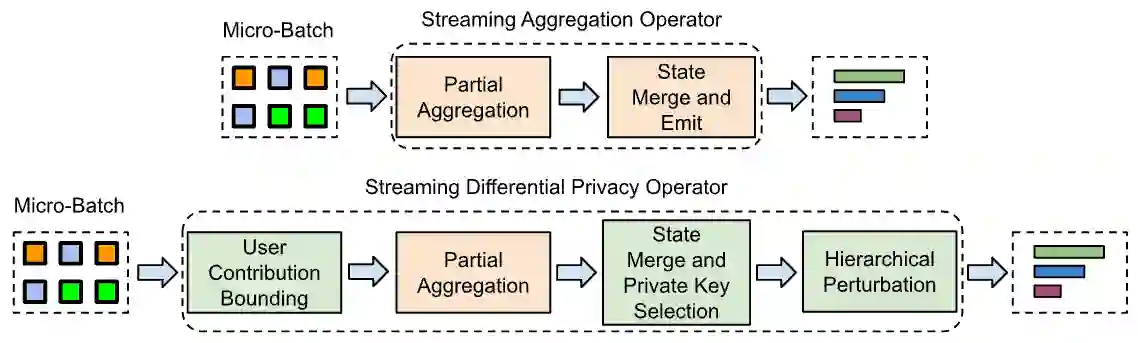
We design, to the best of our knowledge, the first differentially private (DP) stream processing system at scale. Our system --Differential Privacy SQL Pipelines (DP-SQLP)-- is built using a streaming framework similar to Spark streaming, and is built on top of the Spanner database and the F1 query engine from Google. Towards designing DP-SQLP we make both algorithmic and systemic advances, namely, we (i) design a novel DP key selection algorithm that can operate on an unbounded set of possible keys, and can scale to one billion keys that users have contributed, (ii) design a preemptive execution scheme for DP key selection that avoids enumerating all the keys at each triggering time, and (iii) use algorithmic techniques from DP continual observation to release a continual DP histogram of user contributions to different keys over the stream length. We empirically demonstrate the efficacy by obtaining at least $16\times$ reduction in error over meaningful baselines we consider.
翻译:我们设计了一个据我们所知首个大规模差分隐私(DP)流处理系统。我们的系统——差分隐私SQL管道(DP-SQLP)——采用类似于Spark Streaming的流处理框架构建,并基于Google的Spanner数据库和F1查询引擎实现。在DP-SQLP的设计过程中,我们实现了算法和系统层面的双重突破,具体包括:(i) 设计了一种新颖的DP密钥选择算法,可处理无限集合中的潜在密钥,并扩展到用户贡献的十亿级密钥规模;(ii) 提出了一种预防性执行方案用于DP密钥选择,避免在每个触发时刻枚举所有密钥;(iii) 利用差分隐私持续观测技术,在流处理周期内持续发布用户对不同密钥贡献的差分隐私直方图。通过实验验证,我们所考虑的有意义基线方案实现了至少16倍的误差降低。