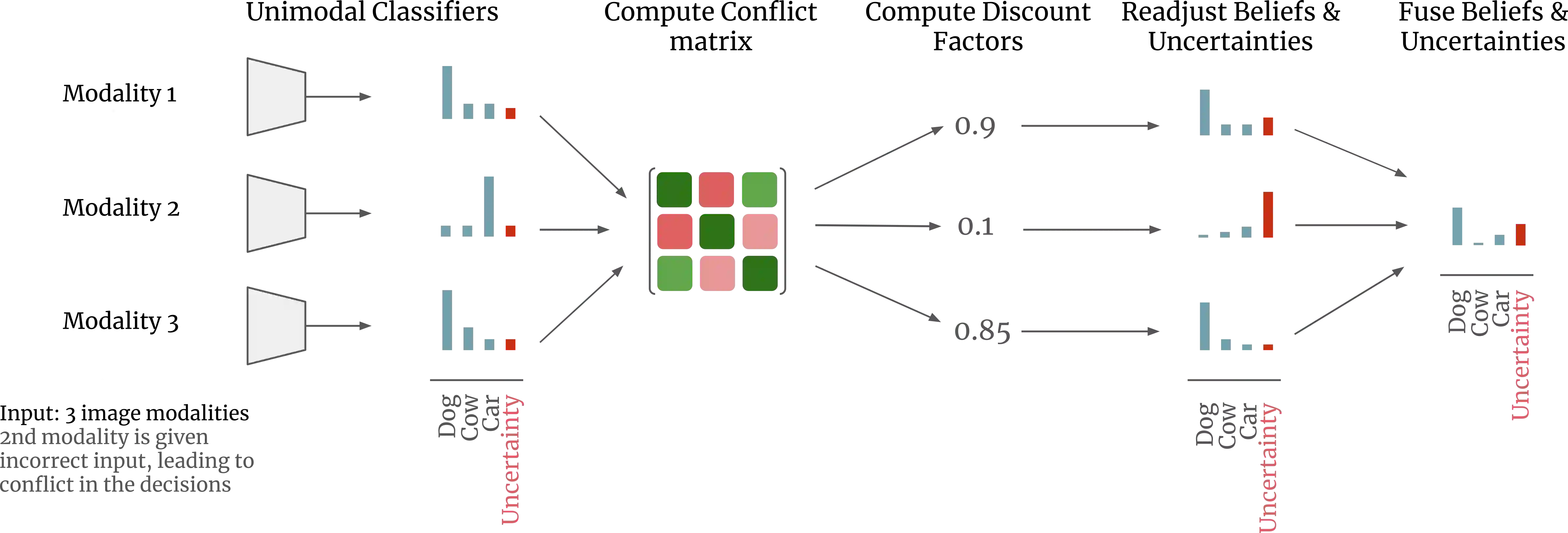
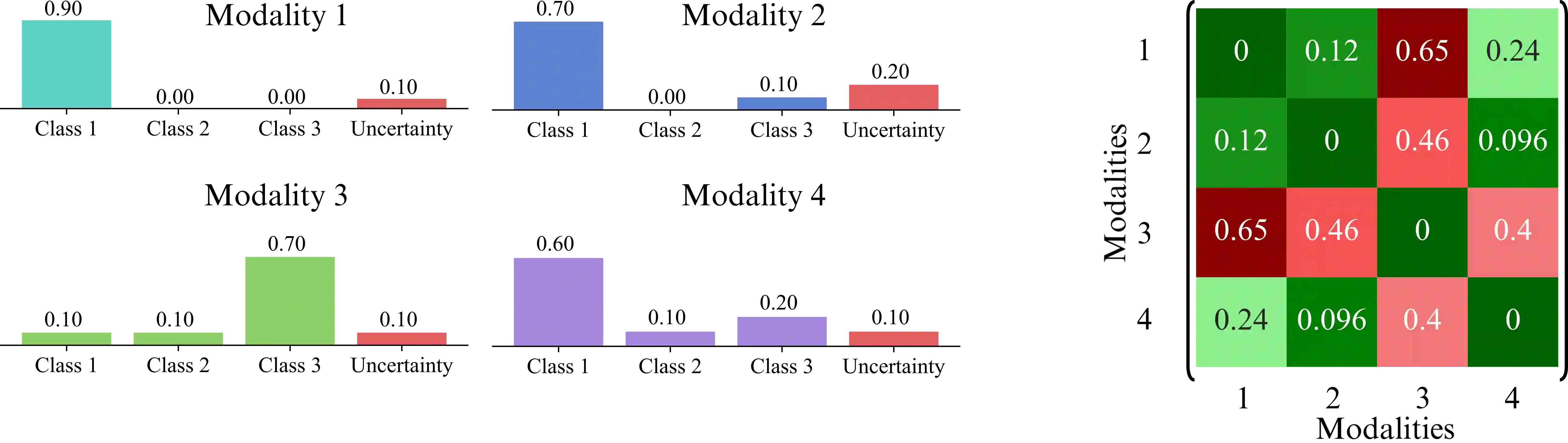
Multimodal AI models are increasingly used in fields like healthcare, finance, and autonomous driving, where information is drawn from multiple sources or modalities such as images, texts, audios, videos. However, effectively managing uncertainty - arising from noise, insufficient evidence, or conflicts between modalities - is crucial for reliable decision-making. Current uncertainty-aware machine learning methods leveraging, for example, evidence averaging, or evidence accumulation underestimate uncertainties in high-conflict scenarios. Moreover, the state-of-the-art evidence averaging strategy is not order invariant and fails to scale to multiple modalities. To address these challenges, we propose a novel multimodal learning method with order-invariant evidence fusion and introduce a conflict-based discounting mechanism that reallocates uncertain mass when unreliable modalities are detected. We provide both theoretical analysis and experimental validation, demonstrating that unlike the previous work, the proposed approach effectively distinguishes between conflicting and non-conflicting samples based on the provided uncertainty estimates, and outperforms the previous models in uncertainty-based conflict detection.
翻译:多模态人工智能模型在医疗、金融和自动驾驶等领域日益普及,这些领域需要从图像、文本、音频、视频等多种来源或模态中提取信息。然而,有效管理不确定性——这些不确定性源于噪声、证据不足或模态间的冲突——对于可靠决策至关重要。当前基于不确定性的机器学习方法(例如利用证据平均或证据累积的方法)在高冲突场景中会低估不确定性。此外,最先进的证据平均策略不具备顺序不变性,且难以扩展到多模态场景。为应对这些挑战,我们提出了一种具有顺序不变证据融合的新型多模态学习方法,并引入了一种基于冲突的折扣机制,该机制在检测到不可靠模态时重新分配不确定质量。我们提供了理论分析和实验验证,证明与先前工作不同,所提出的方法能够基于提供的不确定性估计有效区分冲突与非冲突样本,并在基于不确定性的冲突检测方面优于先前模型。