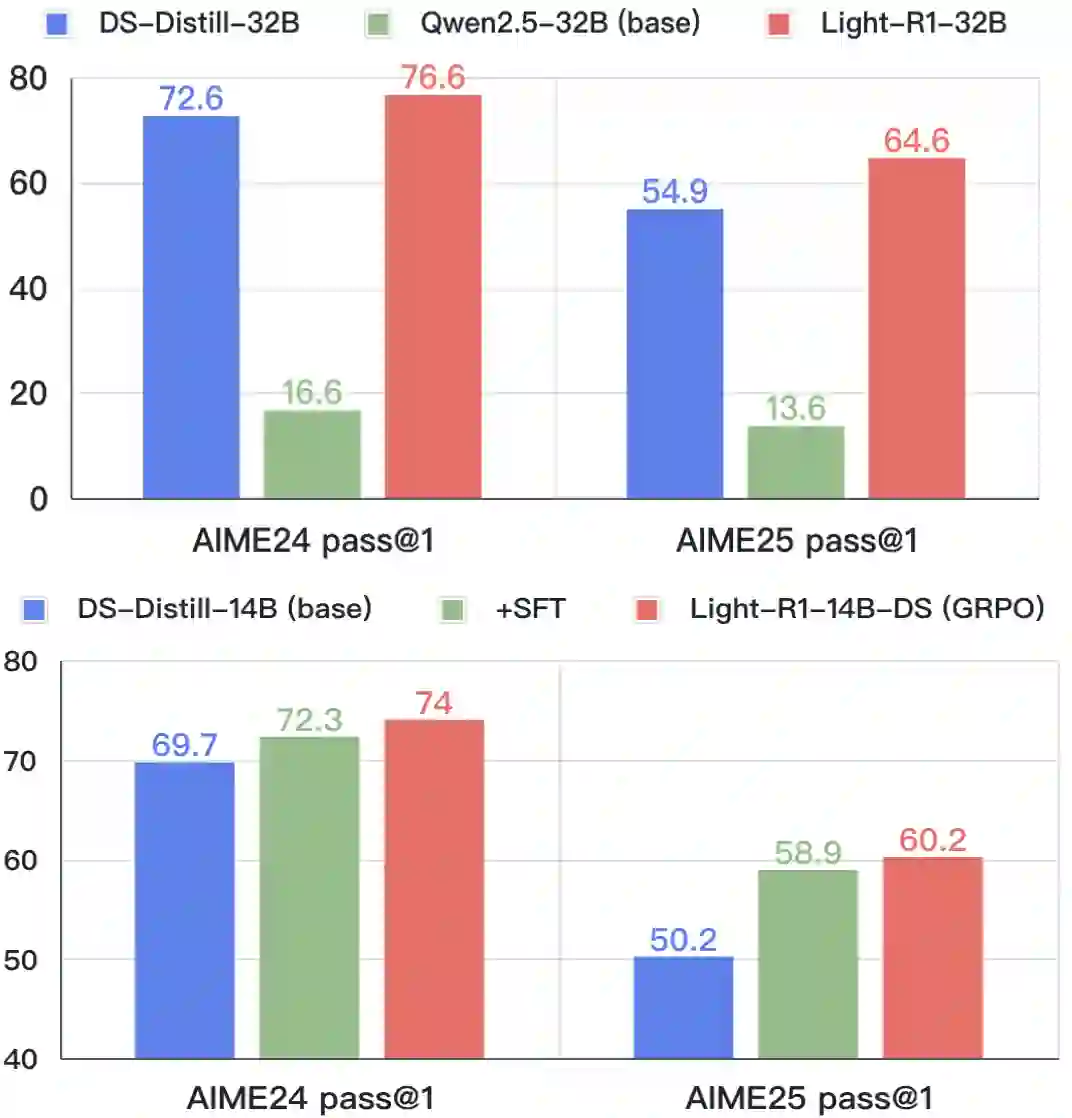
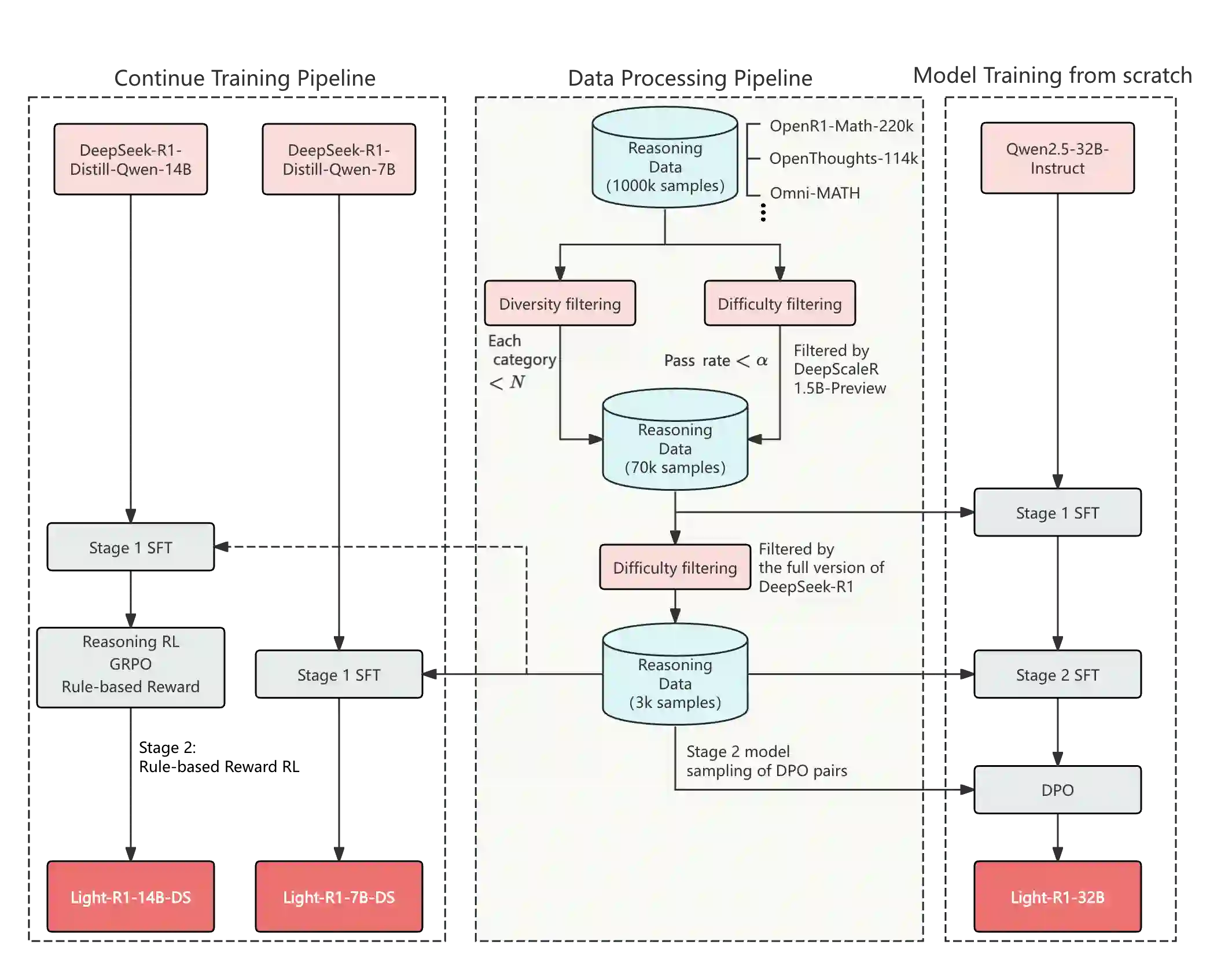
This paper introduces Light-R1, an open-source suite for training long reasoning models using reproducible and cost-effective methodology. Given the proprietary nature of data used in the DeepSeek-R1 series, we develop an alternative approach leveraging exclusively public data and models. Our curriculum training progressively increases data difficulty, combined with multi-staged post-training. Our Light-R1-32B model, trained from Qwen2.5-32B-Instruct, outperforms DeepSeek-R1-Distill-Qwen-32B in math reasoning. Experimental results show that this curriculum approach becomes more effective when distinct, diverse datasets are available for different training stages: fine-tuning DeepSeek-R1-Distilled models (pre-tuned by DeepSeek team on proprietary data) with 3,000 challenging examples from our curriculum dataset yielded state-of-the-art 7B and 14B models, while the 32B model, Light-R1-32B-DS performed comparably to QwQ-32B and DeepSeek-R1. Furthermore, we extend our work by applying GRPO on long reasoning models. Our final Light-R1-14B-DS achieves SOTA performance among 14B models in math, with AIME24 \& 25 scores of 74.0 and 60.2 respectively, surpassing many 32B models and DeepSeek-R1-Distill-Llama-70B. Despite math-focused training, Light-R1-14B-DS demonstrates strong cross-domain generalization. Light-R1 represents a significant advancement in making sophisticated reasoning models more accessible and implementable in real-world applications. Our models, training data and code have been made available at https://github.com/Qihoo360/Light-R1.
翻译:本文介绍Light-R1,一个基于可复现且经济高效方法训练长链推理模型的开源工具套件。鉴于DeepSeek-R1系列所用数据的专有性质,我们开发了一种完全依赖公开数据与模型的替代方案。我们的课程训练策略逐步提升数据难度,并与多阶段后训练相结合。基于Qwen2.5-32B-Instruct训练的Light-R1-32B模型在数学推理任务上超越了DeepSeek-R1-Distill-Qwen-32B。实验结果表明,当不同训练阶段能获得差异化的多样数据集时,这种课程学习方法更为有效:使用我们课程数据集中3000个挑战性样本对DeepSeek-R1蒸馏模型(经DeepSeek团队基于专有数据预调优)进行微调,产生了性能领先的7B与14B模型;而32B模型Light-R1-32B-DS的表现与QwQ-32B及DeepSeek-R1相当。此外,我们通过将GRPO应用于长链推理模型进一步拓展了本工作。最终获得的Light-R1-14B-DS在14B量级数学模型中达到最优性能,其AIME24与AIME25得分分别为74.0和60.2,超越了许多32B模型及DeepSeek-R1-Distill-Llama-70B。尽管训练聚焦于数学领域,Light-R1-14B-DS展现出强大的跨领域泛化能力。Light-R1标志着在使复杂推理模型更易于获取并适用于实际应用方面取得重要进展。我们的模型、训练数据与代码已发布于https://github.com/Qihoo360/Light-R1。