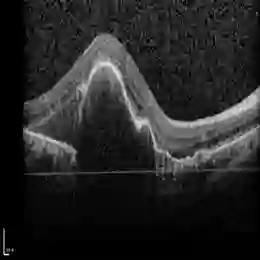
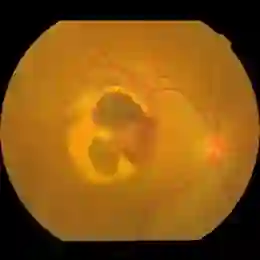
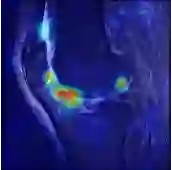
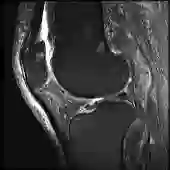
Current methods for multimodal medical imaging based disease recognition face two major challenges. First, the prevailing "fusion after unimodal image embedding" paradigm cannot fully leverage the complementary and correlated information in the multimodal data. Second, the scarcity of labeled multimodal medical images, coupled with their significant domain shift from natural images, hinders the use of cutting-edge Vision Foundation Models (VFMs) for medical image embedding. To jointly address the challenges, we propose a novel Early Intervention (EI) framework. Treating one modality as target and the rest as reference, EI harnesses high-level semantic tokens from the reference as intervention tokens to steer the target modality's embedding process at an early stage. Furthermore, we introduce Mixture of Low-varied-Ranks Adaptation (MoR), a parameter-efficient fine-tuning method that employs a set of low-rank adapters with varied ranks and a weight-relaxed router for VFM adaptation. Extensive experiments on three public datasets for retinal disease, skin lesion, and keen anomaly classification verify the effectiveness of the proposed method against a number of competitive baselines.
翻译:当前基于多模态医学成像的疾病识别方法面临两大挑战。首先,主流的“单模态图像嵌入后融合”范式无法充分利用多模态数据中的互补与关联信息。其次,标注多模态医学图像的稀缺性,加之其与自然图像存在显著的领域偏移,阻碍了前沿视觉基础模型(VFMs)在医学图像嵌入中的应用。为协同应对这些挑战,我们提出了一种新颖的早期干预(EI)框架。该框架将一种模态视作目标模态,其余作为参考模态,利用参考模态的高层语义标记作为干预标记,在早期阶段引导目标模态的嵌入过程。此外,我们引入了混合低变秩自适应(MoR),这是一种参数高效的微调方法,它采用一组具有不同秩的低秩适配器和一个权重松弛路由器来实现对VFM的自适应。在视网膜疾病、皮肤病变及膝关节异常分类三个公开数据集上进行的大量实验验证了所提方法相对于多个竞争基线的有效性。