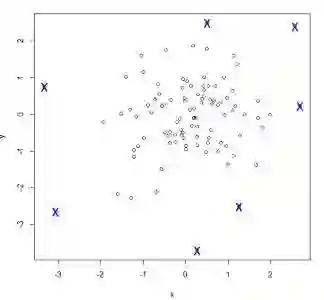
Data profiling is an essential process in modern data-driven industries. One of its critical components is the discovery and validation of complex statistics, including functional dependencies, data constraints, association rules, and others. However, most existing data profiling systems that focus on complex statistics do not provide proper integration with the tools used by contemporary data scientists. This creates a significant barrier to the adoption of these tools in the industry. Moreover, existing systems were not created with industrial-grade workloads in mind. Finally, they do not aim to provide descriptive explanations, i.e. why a given pattern is not found. It is a significant issue as it is essential to understand the underlying reasons for a specific pattern's absence to make informed decisions based on the data. Because of that, these patterns are effectively rest in thin air: their application scope is rather limited, they are rarely used by the broader public. At the same time, as we are going to demonstrate in this presentation, complex statistics can be efficiently used to solve many classic data quality problems. Desbordante is an open-source data profiler that aims to close this gap. It is built with emphasis on industrial application: it is efficient, scalable, resilient to crashes, and provides explanations. Furthermore, it provides seamless Python integration by offloading various costly operations to the C++ core, not only mining. In this demonstration, we show several scenarios that allow end users to solve different data quality problems. Namely, we showcase typo detection, data deduplication, and data anomaly detection scenarios.
翻译:数据剖析是现代数据驱动行业中不可或缺的关键过程。其核心组成部分之一是对复杂统计量(包括函数依赖、数据约束、关联规则等)的发现与验证。然而,现有专注于复杂统计量的多数数据剖析系统未能与当代数据科学家使用的工具实现良好集成,这严重阻碍了这些工具在工业领域的推广。此外,现有系统在设计时未考虑工业级工作负载的需求,并且未能提供描述性解释(即特定模式为何未被发现)。这是一个重大问题,因为理解特定模式缺失的潜在原因对于基于数据做出明智决策至关重要。因此,这些模式实质上形同虚设:其应用范围相当有限,很少被广大用户使用。与此同时,正如我们将在本次演示中展示的,复杂统计量可有效用于解决许多经典数据质量问题。Desbordante作为一款旨在弥合这一差距的开源数据剖析工具,其设计强调工业应用:高效、可扩展、具备崩溃恢复能力,并能提供解释说明。此外,它通过将各类高成本操作(不仅限于挖掘过程)卸载至C++核心引擎,实现了与Python的无缝集成。在本次演示中,我们将展示若干使用场景,使终端用户能够解决不同类型的数据质量问题,具体包括:错别字检测、数据去重以及数据异常检测。