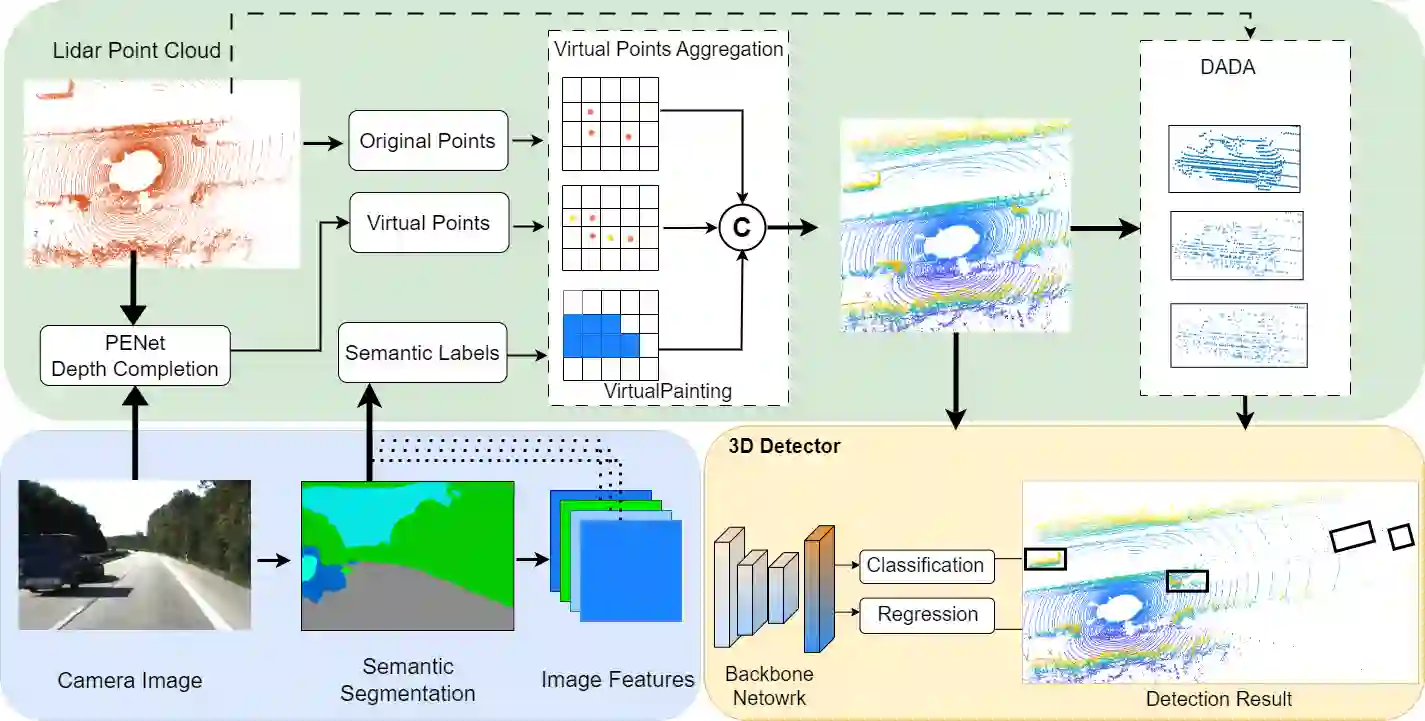
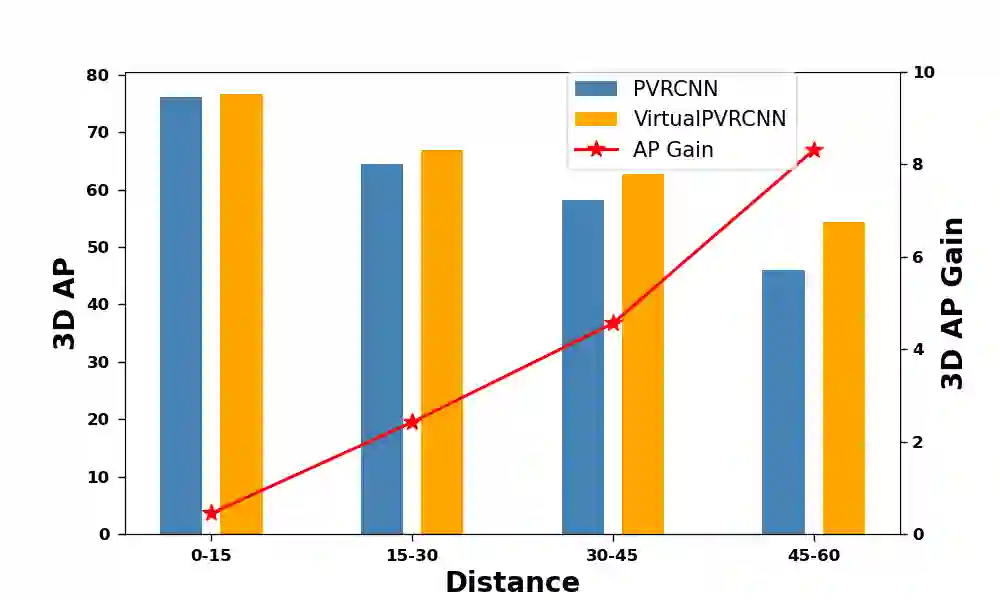
In recent times, there has been a notable surge in multimodal approaches that decorates raw LiDAR point clouds with camera-derived features to improve object detection performance. However, we found that these methods still grapple with the inherent sparsity of LiDAR point cloud data, primarily because fewer points are enriched with camera-derived features for sparsely distributed objects. We present an innovative approach that involves the generation of virtual LiDAR points using camera images and enhancing these virtual points with semantic labels obtained from image-based segmentation networks to tackle this issue and facilitate the detection of sparsely distributed objects, particularly those that are occluded or distant. Furthermore, we integrate a distance aware data augmentation (DADA) technique to enhance the models capability to recognize these sparsely distributed objects by generating specialized training samples. Our approach offers a versatile solution that can be seamlessly integrated into various 3D frameworks and 2D semantic segmentation methods, resulting in significantly improved overall detection accuracy. Evaluation on the KITTI and nuScenes datasets demonstrates substantial enhancements in both 3D and birds eye view (BEV) detection benchmarks
翻译:近年来,融合相机特征增强原始激光雷达点云的多模态方法在提升目标检测性能方面呈现出显著增长趋势。然而,我们发现这些方法仍难以解决激光雷达点云数据固有的稀疏性问题,主要原因是稀疏分布目标中能够获得相机特征的采样点数量不足。本文提出一种创新方法:通过相机图像生成虚拟激光雷达点,并利用基于图像分割网络获得的语义标签增强这些虚拟点,从而解决该问题并促进稀疏分布目标(尤其是遮挡或远距离目标)的检测。此外,我们集成距离感知数据增强技术,通过生成专门训练样本增强模型对稀疏分布目标的识别能力。该方法具有高通用性,可无缝集成至多种三维框架与二维语义分割方法中,显著提升整体检测精度。在KITTI和nuScenes数据集上的评估表明,该方法在三维检测及鸟瞰图(BEV)检测基准测试中均实现了大幅性能提升。