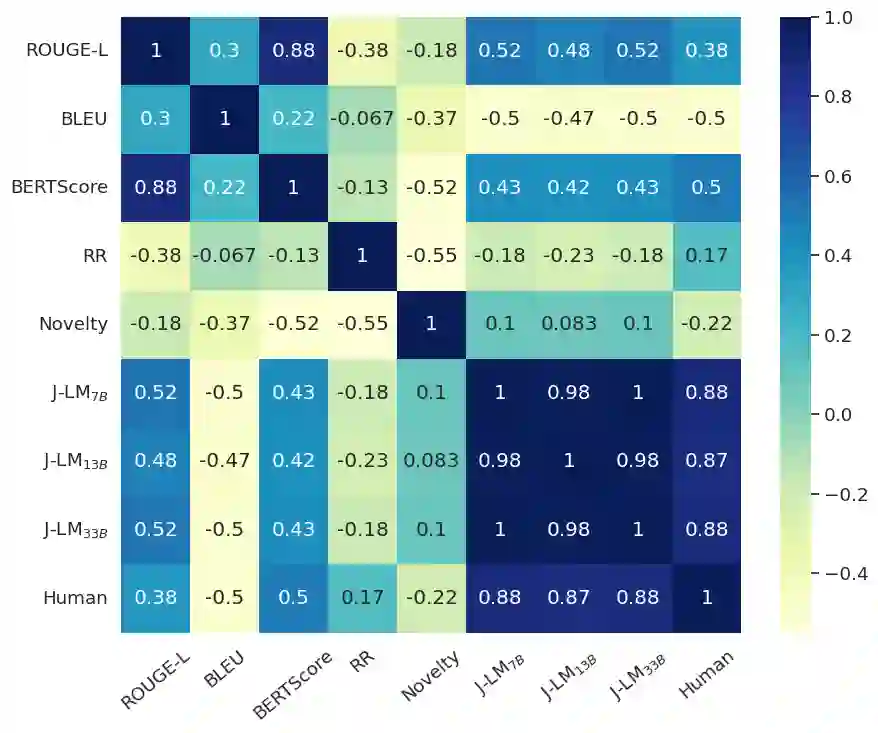
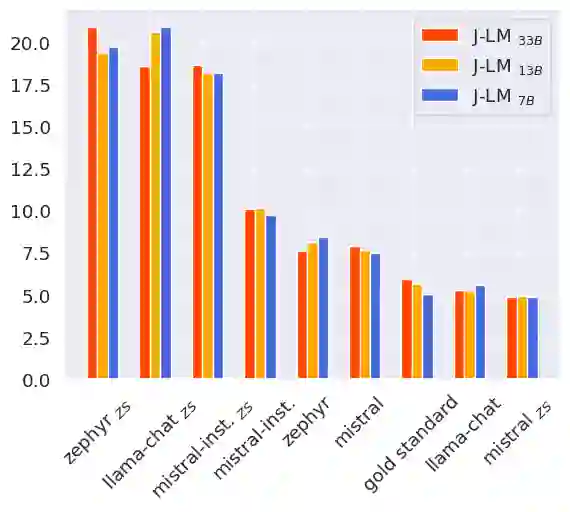
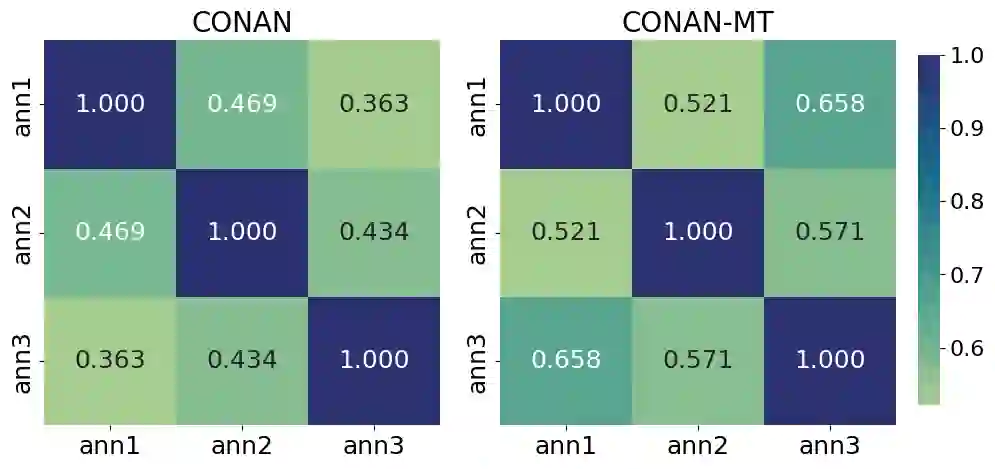
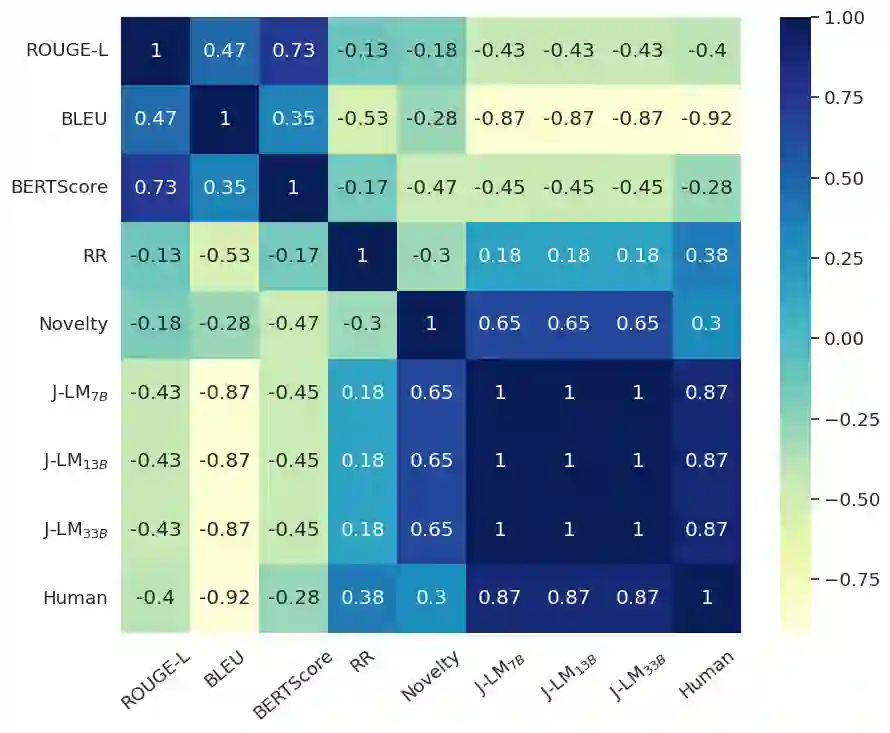
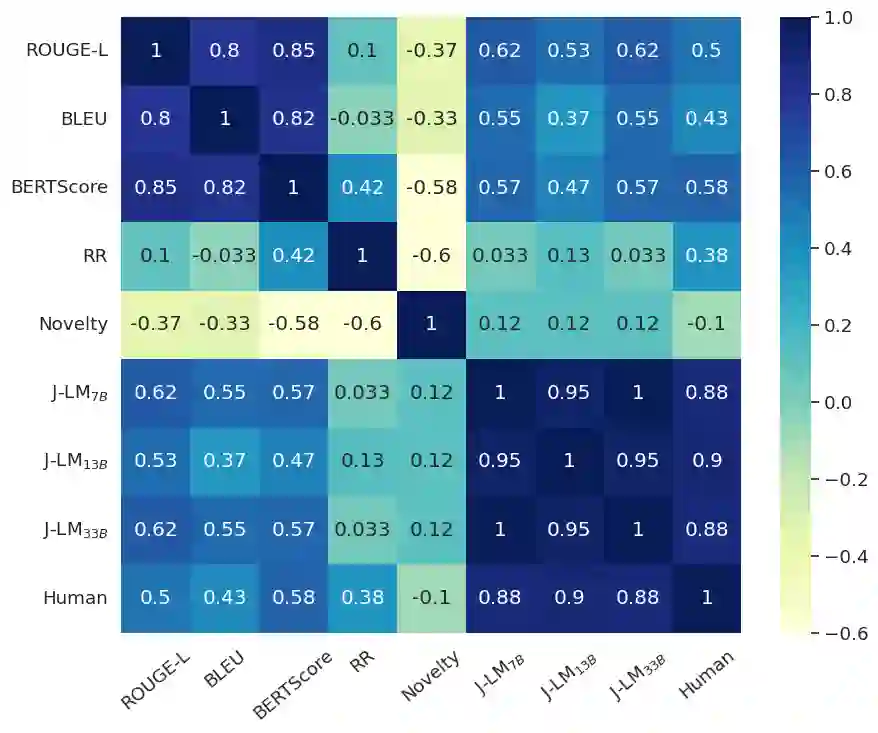
The proliferation of misinformation and harmful narratives in online discourse has underscored the critical need for effective Counter Narrative (CN) generation techniques. However, existing automatic evaluation methods often lack interpretability and fail to capture the nuanced relationship between generated CNs and human perception. Aiming to achieve a higher correlation with human judgments, this paper proposes a novel approach to asses generated CNs that consists on the use of a Large Language Model (LLM) as a evaluator. By comparing generated CNs pairwise in a tournament-style format, we establish a model ranking pipeline that achieves a correlation of $0.88$ with human preference. As an additional contribution, we leverage LLMs as zero-shot (ZS) CN generators and conduct a comparative analysis of chat, instruct, and base models, exploring their respective strengths and limitations. Through meticulous evaluation, including fine-tuning experiments, we elucidate the differences in performance and responsiveness to domain-specific data. We conclude that chat-aligned models in ZS are the best option for carrying out the task, provided they do not refuse to generate an answer due to security concerns.
翻译:在线话语中错误信息和有害叙事的扩散凸显了对有效反叙事(CN)生成技术的迫切需求。然而,现有的自动评估方法往往缺乏可解释性,且未能捕捉生成的反叙事与人类感知之间的微妙关系。为了获得与人类判断更高的相关性,本文提出了一种评估生成反叙事的新方法,该方法利用大语言模型(LLM)作为评估器。通过以锦标赛形式对生成的反叙事进行成对比较,我们建立了一个模型排序流程,其与人类偏好的相关性达到 $0.88$。作为另一项贡献,我们利用大语言模型作为零样本(ZS)反叙事生成器,并对聊天模型、指令微调模型和基础模型进行了比较分析,探讨了它们各自的优势与局限。通过包括微调实验在内的细致评估,我们阐明了它们在性能及对领域特定数据的响应性方面的差异。我们得出结论:在零样本设置下,经过聊天对齐的模型是执行此任务的最佳选择,前提是它们不会因安全顾虑而拒绝生成答案。