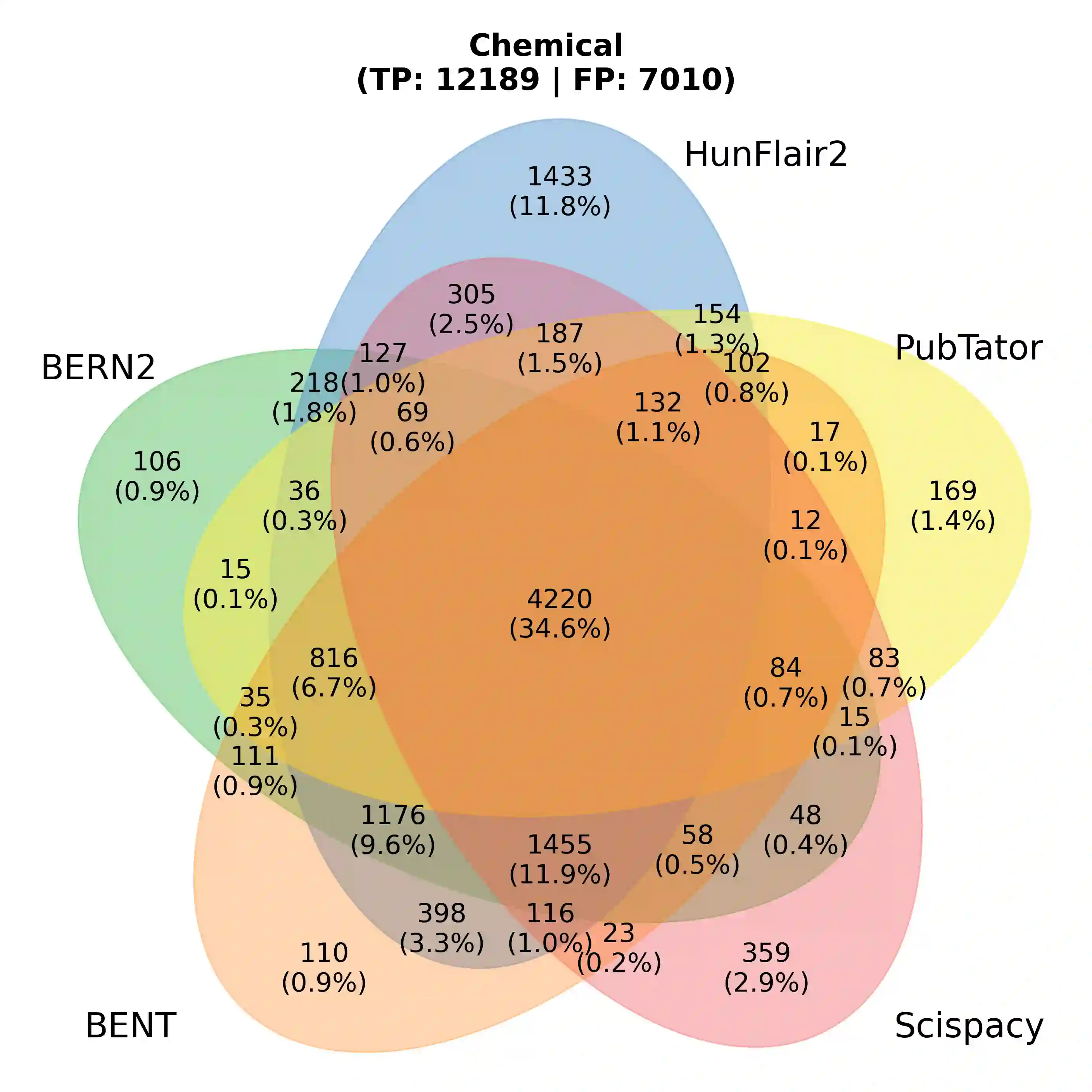
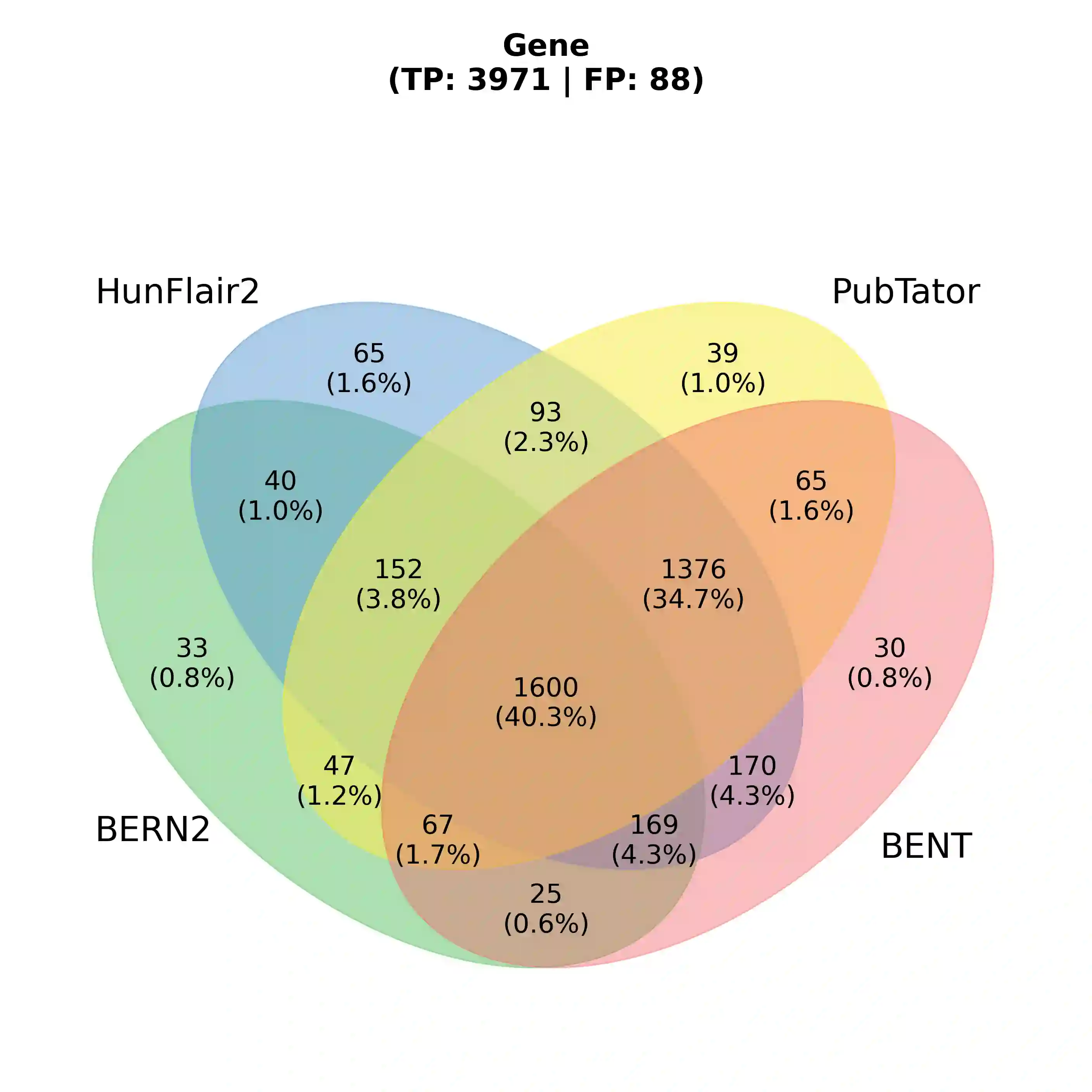
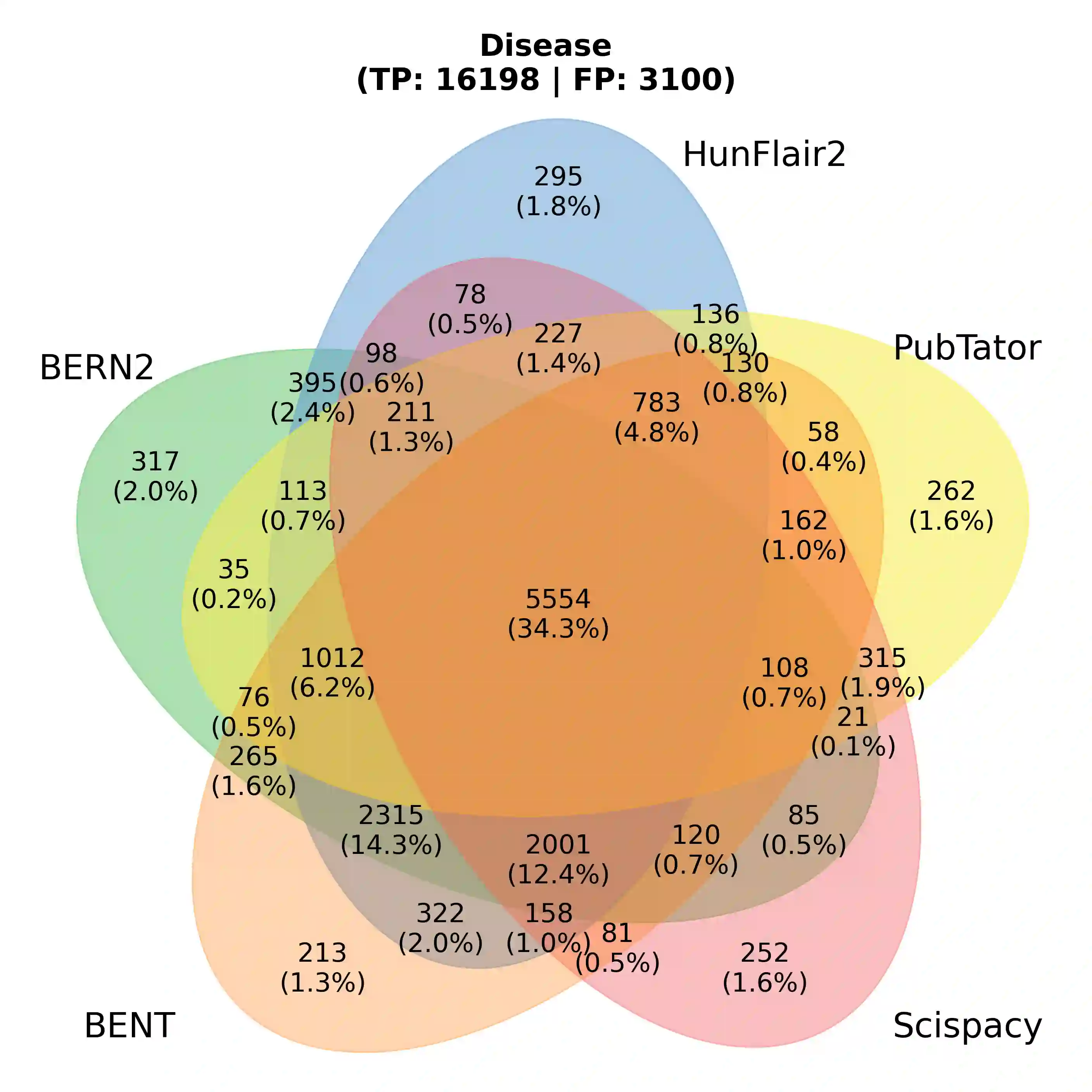
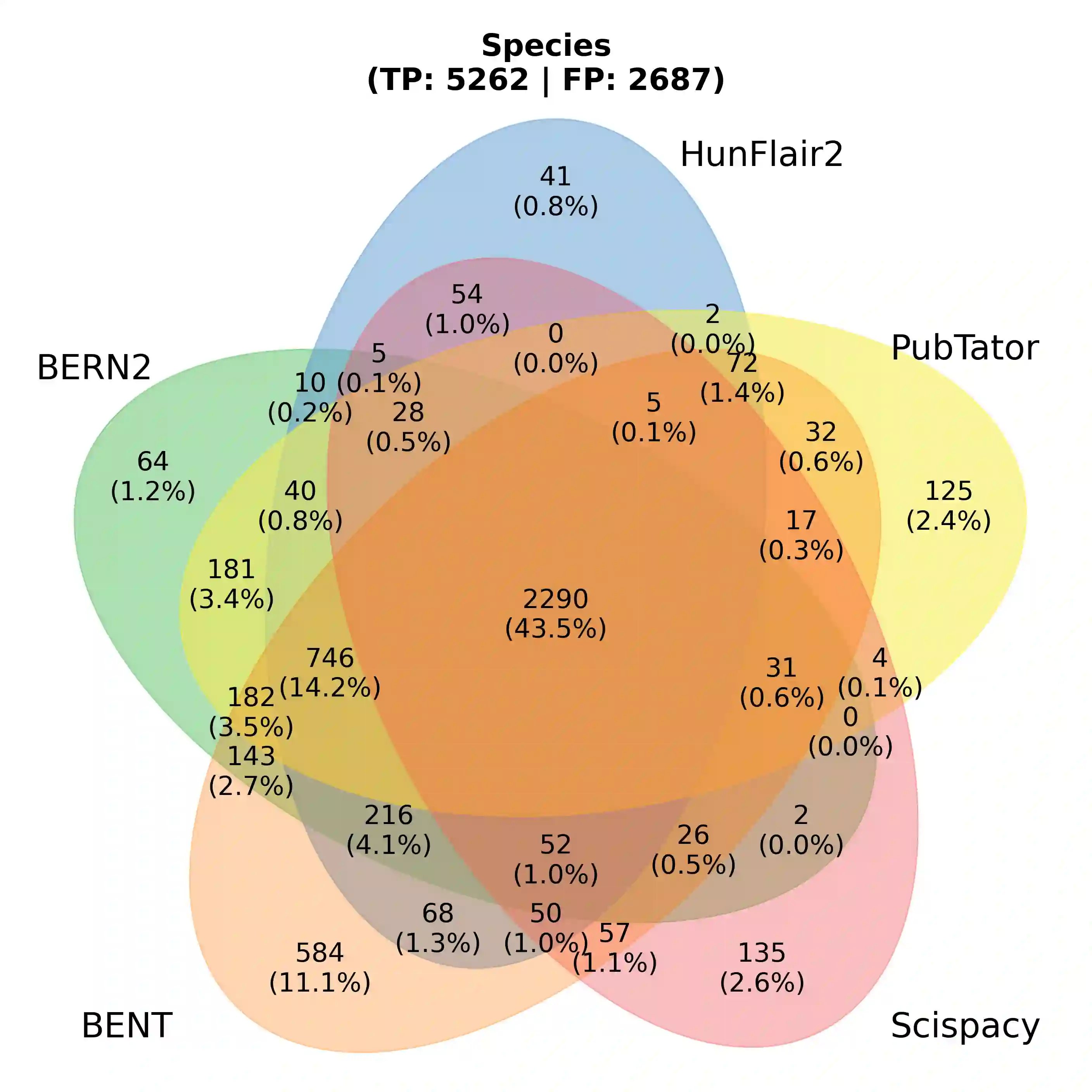
With the exponential growth of the life science literature, biomedical text mining (BTM) has become an essential technology for accelerating the extraction of insights from publications. Identifying named entities (e.g., diseases, drugs, or genes) in texts and their linkage to reference knowledge bases are crucial steps in BTM pipelines to enable information aggregation from different documents. However, tools for these two steps are rarely applied in the same context in which they were developed. Instead, they are applied in the wild, i.e., on application-dependent text collections different from those used for the tools' training, varying, e.g., in focus, genre, style, and text type. This raises the question of whether the reported performance of BTM tools can be trusted for downstream applications. Here, we report on the results of a carefully designed cross-corpus benchmark for named entity extraction, where tools were applied systematically to corpora not used during their training. Based on a survey of 28 published systems, we selected five for an in-depth analysis on three publicly available corpora encompassing four different entity types. Comparison between tools results in a mixed picture and shows that, in a cross-corpus setting, the performance is significantly lower than the one reported in an in-corpus setting. HunFlair2 showed the best performance on average, being closely followed by PubTator. Our results indicate that users of BTM tools should expect diminishing performances when applying them in the wild compared to original publications and show that further research is necessary to make BTM tools more robust.
翻译:随着生命科学文献的指数级增长,生物医学文本挖掘已成为加速从出版物中提取见解的关键技术。识别文本中的命名实体(如疾病、药物或基因)并将其关联到参考知识库,是生物医学文本挖掘流程中实现跨文档信息聚合的重要步骤。然而,用于这两个步骤的工具很少在与其开发环境相同的场景中应用,而是被应用于实际开放环境——即与工具训练所用语料库不同的应用相关文本集合,这些语料在主题侧重、体裁、风格和文本类型等方面存在差异。这引发了关键问题:报告中的生物医学文本挖掘工具性能是否值得下游应用信赖?本文报告了一项精心设计的命名实体提取跨语料库基准测试结果,其中工具被系统性地应用于非训练语料。通过调查28个已发表系统,我们筛选出五个工具,在涵盖四种实体类型的三个公开语料库上进行深入分析。工具间的对比呈现出复杂图景:在跨语料库场景下,其性能显著低于语料内场景报告的结果。HunFlair2平均表现最优,PubTator紧随其后。研究结果表明,生物医学文本挖掘工具用户应预期其在实际开放环境中的性能相比原始出版物会有所衰减,并揭示需进一步研究以增强生物医学文本挖掘工具的鲁棒性。