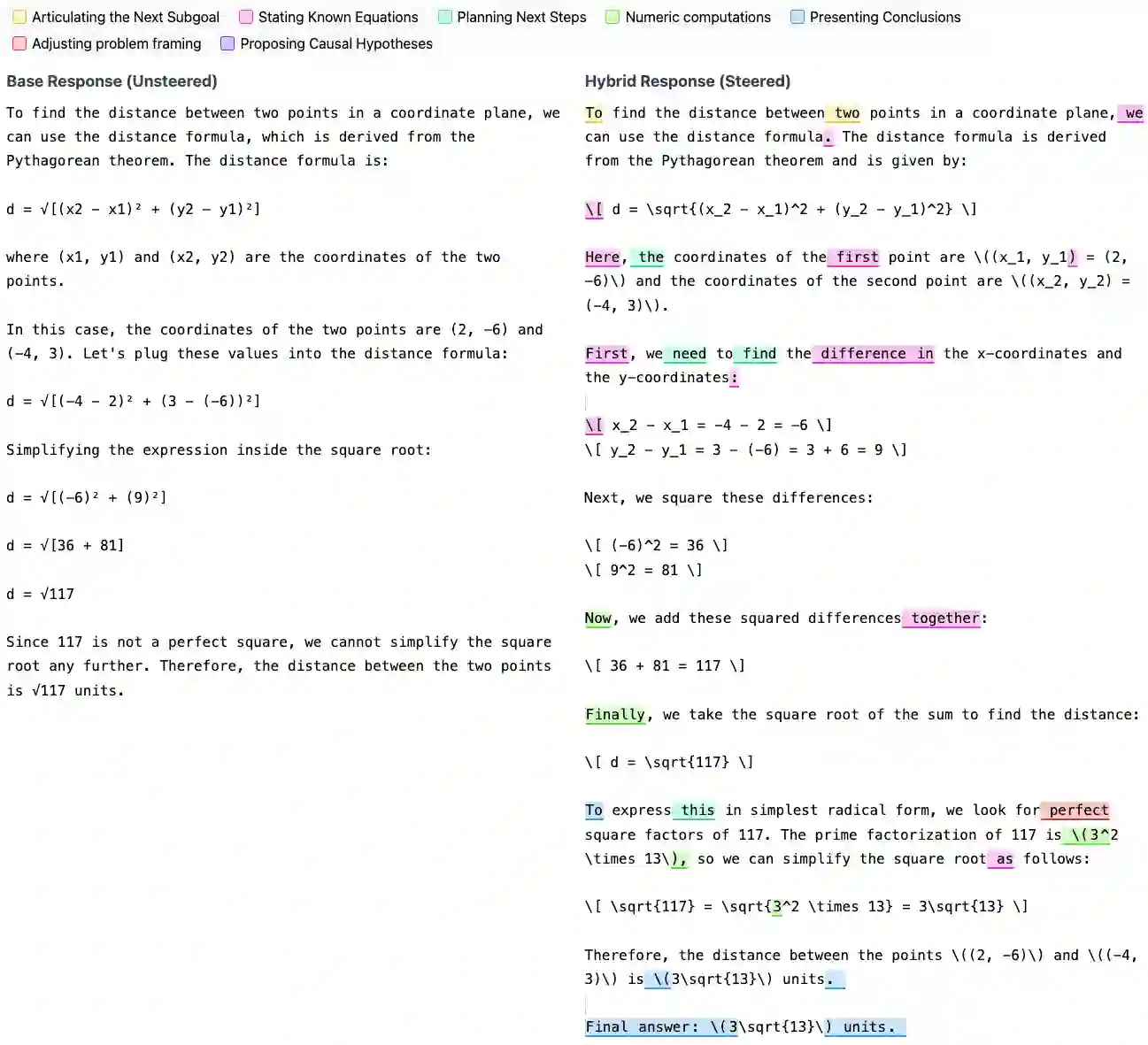
Why do thinking language models like DeepSeek R1 outperform their base counterparts? Despite consistent performance gains, it remains unclear to what extent thinking models learn entirely new reasoning capabilities or repurpose pre-existing base model ones. In this work, we propose a hybrid model where we activate reasoning mechanisms in base models at the right time to elicit thinking-model-level reasoning chains, implying that thinking models exploit already existing capabilities. To ground our analysis, we introduce an unsupervised, bottom-up approach for uncovering human-interpretable reasoning behaviors in thinking models. This approach provides an unbiased method to discover reasoning behaviors without imposing manual or LLM-derived assumptions. Across three base and four thinking models, using GSM8K and MATH500, our hybrid model recovers up to 91% of the performance gap to thinking models without any weight updates while steering only 12% of tokens. Concretely, our empirical setup provides a simple, causal way to test the effectiveness of existing reasoning mechanisms in base models by invoking them directly and measuring the resulting task performance. More broadly, these results reframe our understanding of how thinking models are trained: pre-training is when models acquire most of their reasoning mechanisms, and post-training teaches efficient deployment of these mechanisms at the right time, enabling efficient use of their inference-time compute.
翻译:为何像DeepSeek R1这样的思维语言模型能超越其基础版本?尽管性能提升稳定,但思维模型究竟在多大程度上学习了全新的推理能力,还是重新利用了基础模型已有的能力,这一问题仍不明确。在本研究中,我们提出一种混合模型,通过在适当时机激活基础模型中的推理机制,即可激发出达到思维模型水平的推理链,这表明思维模型实际上利用了已存在的能力。为支撑分析,我们引入一种无监督、自底向上的方法,用于揭示思维模型中人类可解释的推理行为。该方法提供了一种无偏的发现推理行为的途径,无需依赖人工或大语言模型衍生的假设。在三个基础模型和四个思维模型上,基于GSM8K和MATH500数据集,我们的混合模型在仅引导12%的token且不更新任何权重的情况下,恢复了高达91%的与思维模型之间的性能差距。具体而言,我们的实证框架提供了一种简单、因果性的方法来测试基础模型中现有推理机制的有效性:直接调用这些机制并测量由此产生的任务性能。更广泛地看,这些结果重塑了我们对思维模型训练方式的理解:预训练阶段是模型获取大部分推理机制的时期,而后训练则教会模型在适当时机高效部署这些机制,从而实现推理计算资源的高效利用。