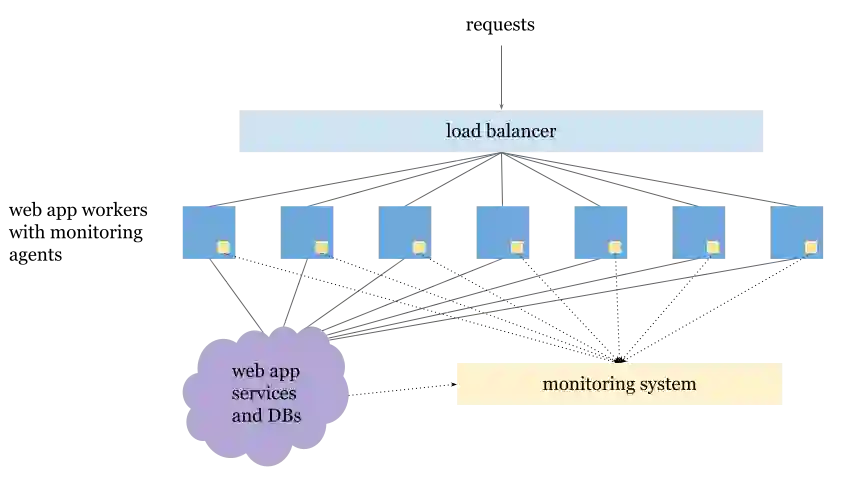
Large, distributed data streams are now ubiquitous. High-accuracy sketches with low memory overhead have become the de facto method for analyzing this data. For instance, if we wish to group data by some label and report the largest counts using fixed memory, we need to turn to mergeable heavy hitter sketches that can provide highly accurate approximate counts. Similarly, if we wish to keep track of the number of distinct items in a single set spread across several streams using fixed memory, we can turn to mergeable count distinct sketches that can provide highly accurate set cardinalities. If we were to try to keep track of the cardinality of multiple sets and report only on the largest ones, maintaining individual count distinct sketches for each set can grow unwieldy, especially if the number of sets is not known in advance. We consider the natural combination of the heavy hitters problem with the count distinct problem, the heavy distinct hitters problem: given a stream of $(\ell, x)$ pairs, find all the labels $\ell$ that are paired with a large number of distinct items $x$ using only constant memory. No previous work on heavy distinct hitters has managed to be of practical use in the large, distributed data stream setting. We propose a new algorithm, the Sampling Space-Saving Set Sketch, which combines sketching and sampling techniques and has all the desired properties for size, speed, accuracy, mergeability, and invertibility. We compare our algorithm to several existing solutions to the heavy distinct hitters problem, and provide experimental results across several data sets showing the superiority of the new sketch.
翻译:大规模分布式数据流如今已无处不在。具有低内存开销的高精度草图已成为分析这类数据的事实标准方法。例如,若需按某标签对数据进行分组,并在固定内存下报告最大计数值,就需要借助可合并的重击者草图(mergeable heavy hitter sketches)来提供高精度的近似计数。类似地,若需在固定内存下追踪分散于多个数据流中单一集合的不同元素数量,则可利用可合并的计数不同草图(mergeable count distinct sketches)来提供高精度的集合基数。如果尝试追踪多个集合的基数并仅报告最大的几个集合,则为每个集合维护独立的计数不同草图将变得难以操作,尤其是当集合数量未知时。本文研究了重击者问题与计数不同问题的自然组合——重不同击者问题(heavy distinct hitters problem):给定一个由$(\ell, x)$对构成的数据流,要求仅使用常数级内存找出所有与大量不同元素$x$配对的标签$\ell$。此前关于重不同击者的研究均无法在大规模分布式数据流场景中实际应用。我们提出了一种新算法——采样空间节省集合草图(Sampling Space-Saving Set Sketch),该算法融合了草图与采样技术,在规模、速度、精度、可合并性与可逆性方面均具备理想特性。我们将本算法与现有若干重不同击者问题解决方案进行对比,并在多个数据集上给出实验结果,证明新草图的优越性能。