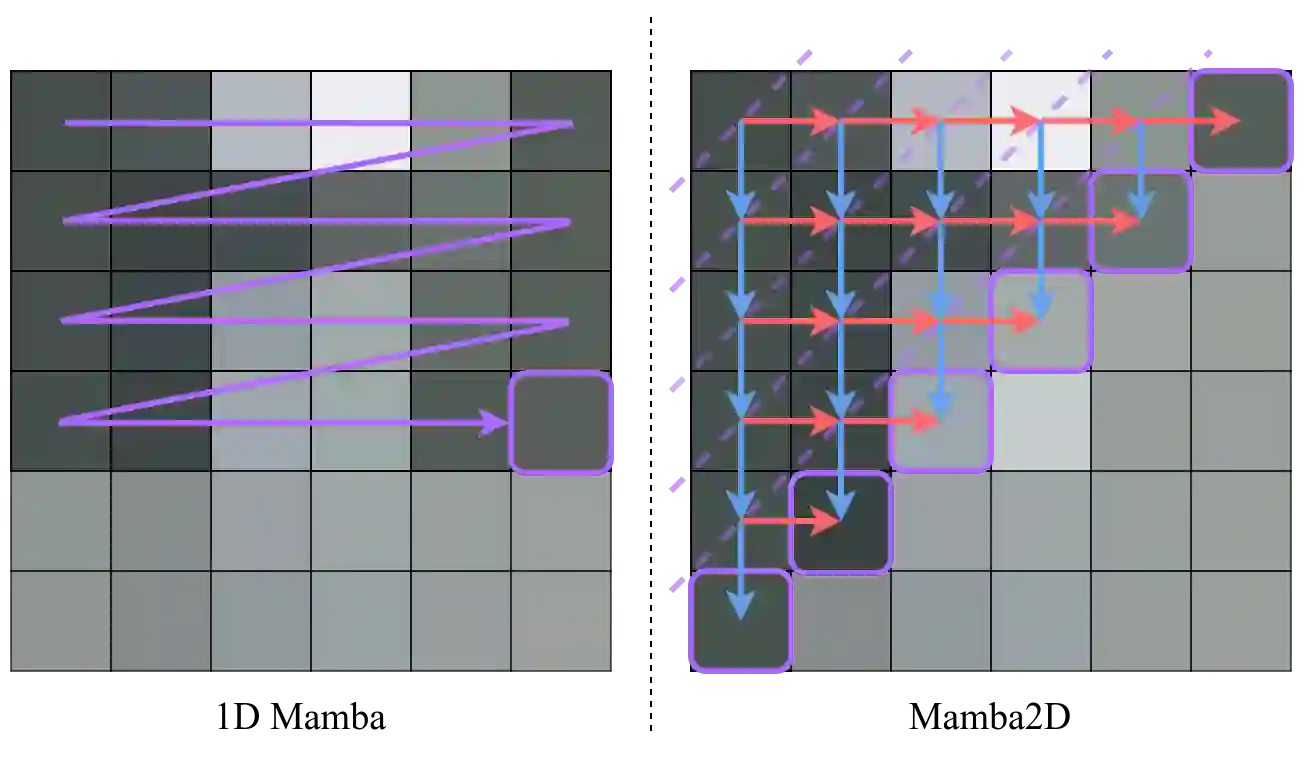
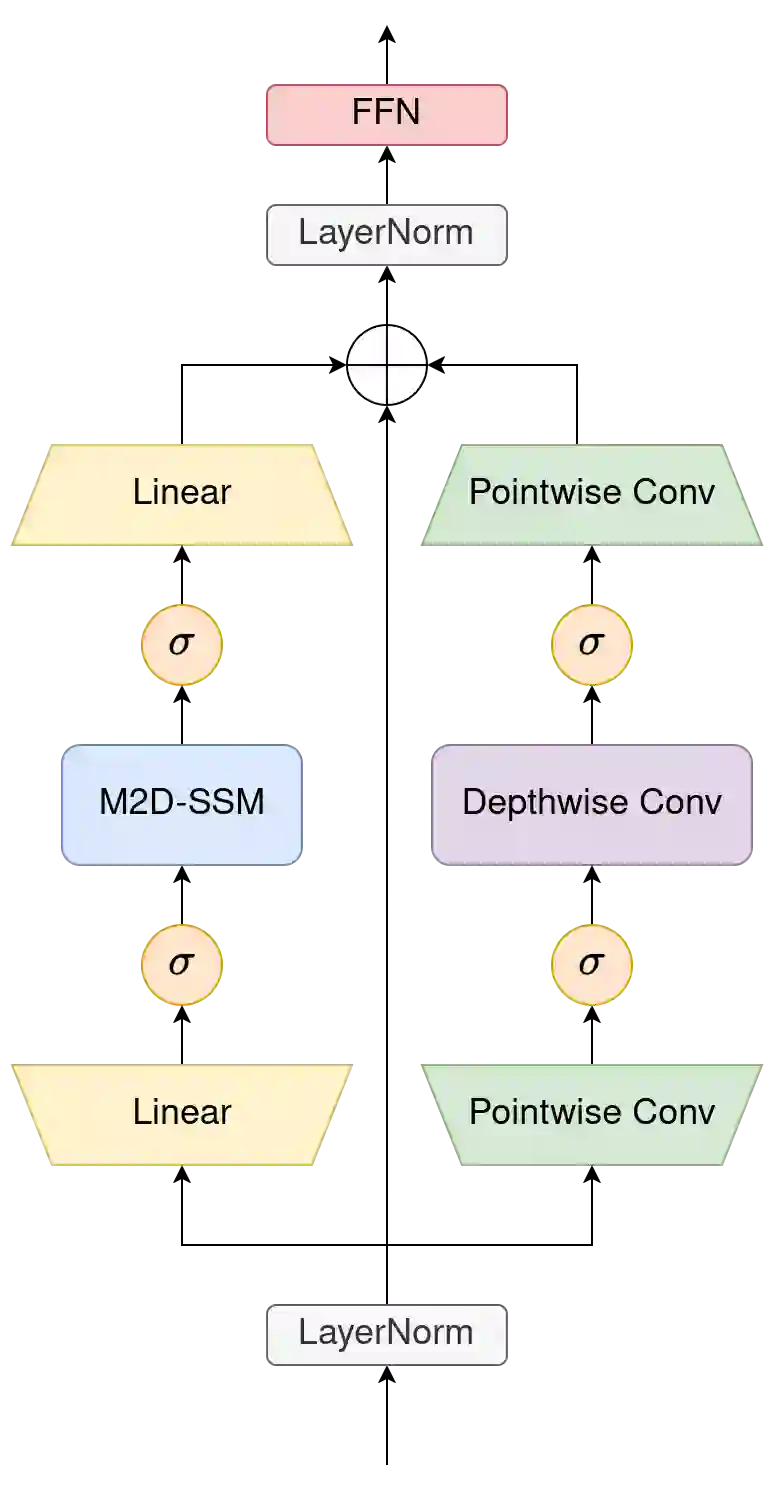
State-Space Models (SSMs) have recently emerged as a powerful and efficient alternative to the long-standing transformer architecture. However, existing SSM conceptualizations retain deeply rooted biases from their roots in natural language processing. This constrains their ability to appropriately model the spatially-dependent characteristics of visual inputs. In this paper, we address these limitations by re-deriving modern selective state-space techniques, starting from a natively multidimensional formulation. Currently, prior works attempt to apply natively 1D SSMs to 2D data (i.e. images) by relying on arbitrary combinations of 1D scan directions to capture spatial dependencies. In contrast, Mamba2D improves upon this with a single 2D scan direction that factors in both dimensions of the input natively, effectively modelling spatial dependencies when constructing hidden states. Mamba2D shows comparable performance to prior adaptations of SSMs for vision tasks, on standard image classification evaluations with the ImageNet-1K dataset.
翻译:状态空间模型(SSMs)近年来已成为长期占据主导地位的Transformer架构的一种强大且高效的替代方案。然而,现有的SSM概念化方法仍保留着其源于自然语言处理领域的根深蒂固的偏见。这限制了它们对视觉输入的空间依赖性特征进行恰当建模的能力。在本文中,我们通过从原生多维公式出发,重新推导现代选择性状态空间技术,以解决这些局限性。目前,先前的工作试图通过依赖一维扫描方向的任意组合来捕获空间依赖性,从而将原生一维SSMs应用于二维数据(即图像)。相比之下,Mamba2D对此进行了改进,它采用单一二维扫描方向,原生地同时考虑输入的两个维度,从而在构建隐藏状态时有效地建模空间依赖性。在ImageNet-1K数据集的标准图像分类评估中,Mamba2D在视觉任务上的表现与先前SSMs的适配方案相当。