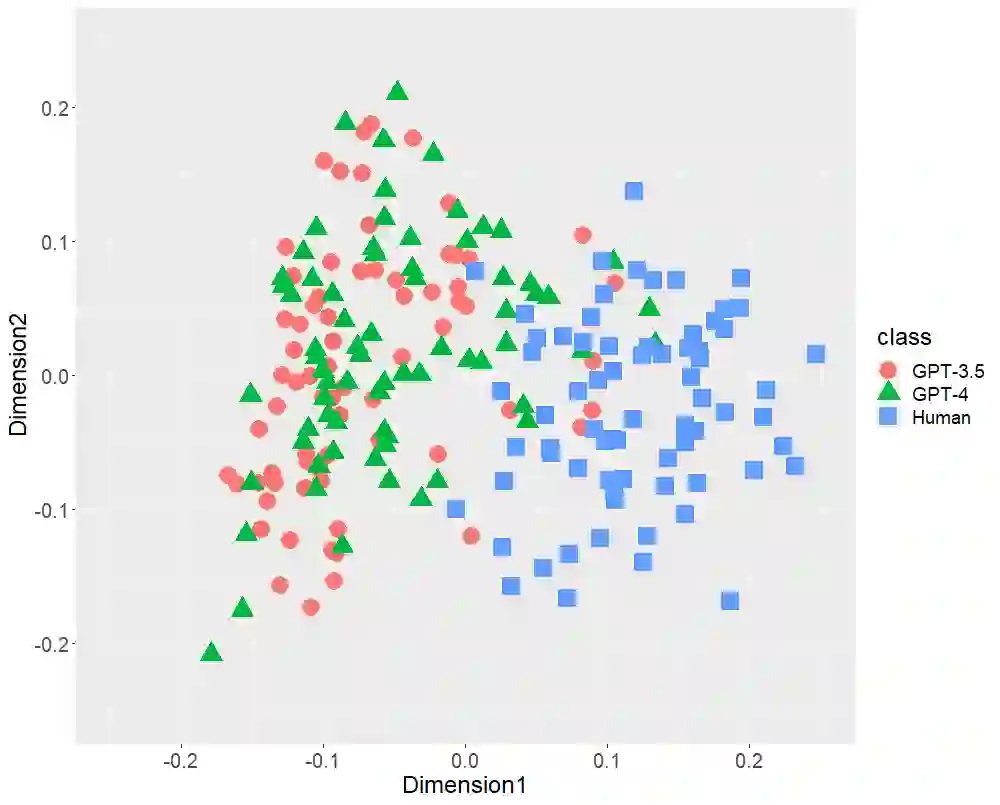
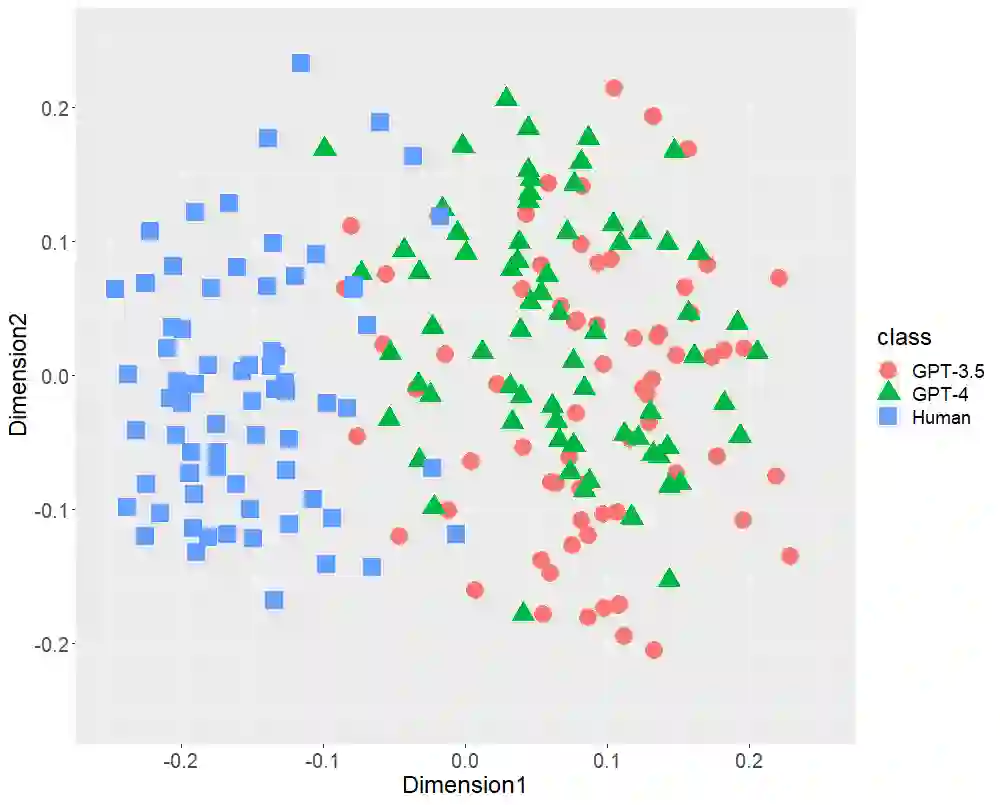
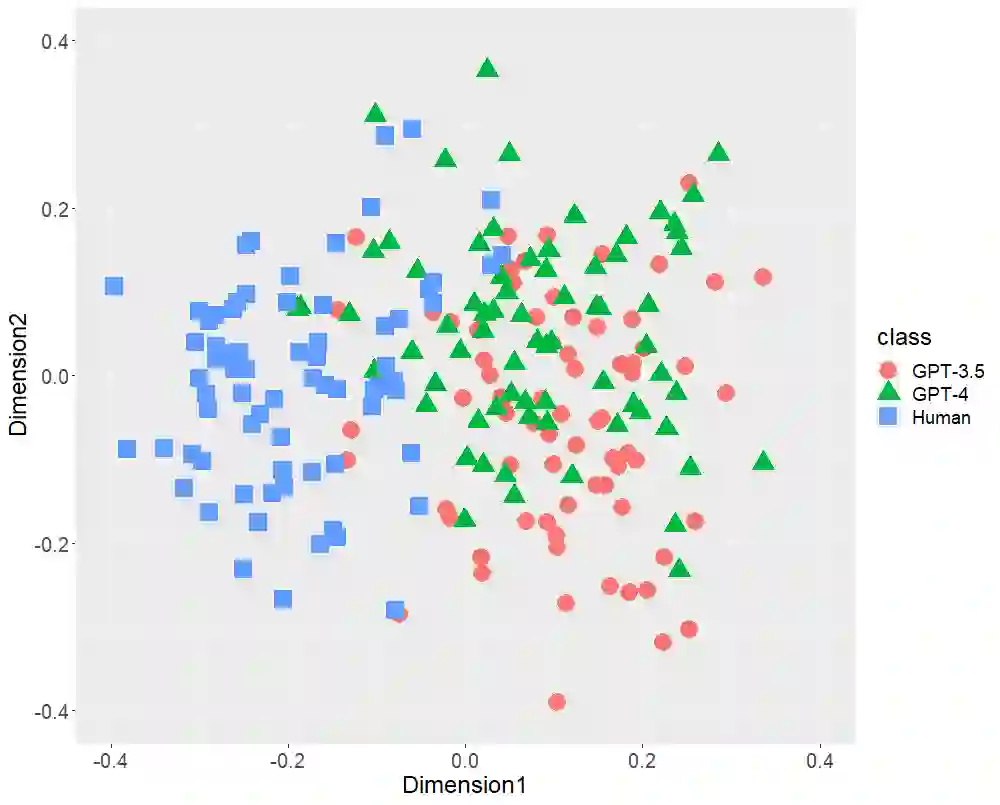
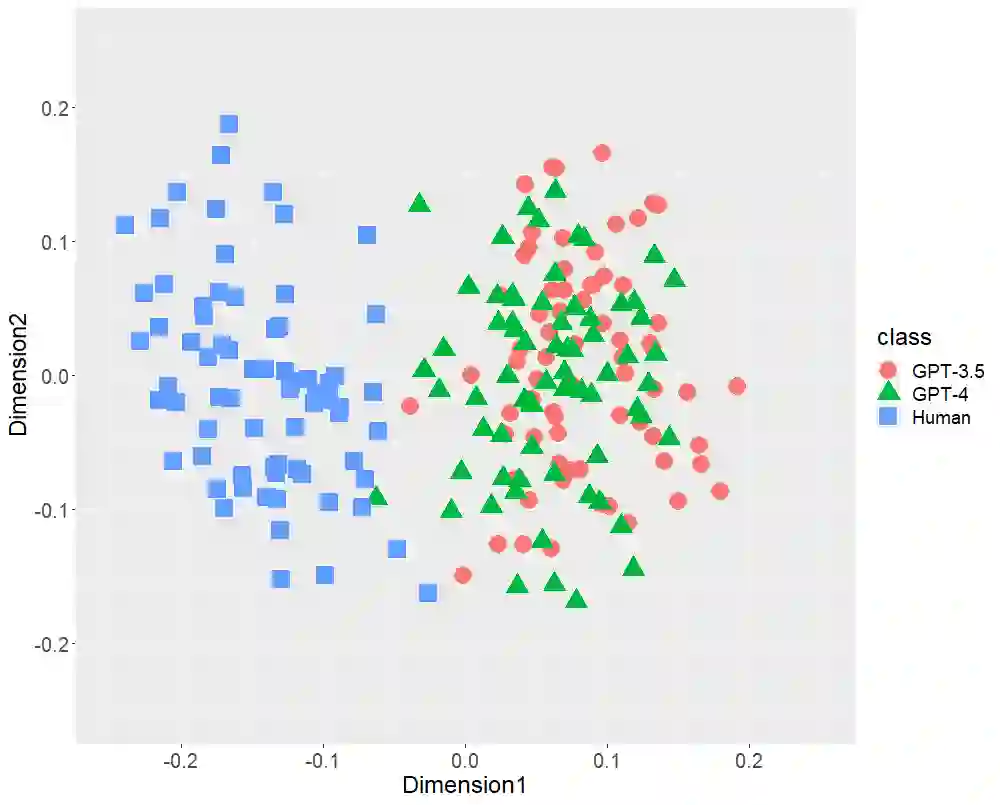
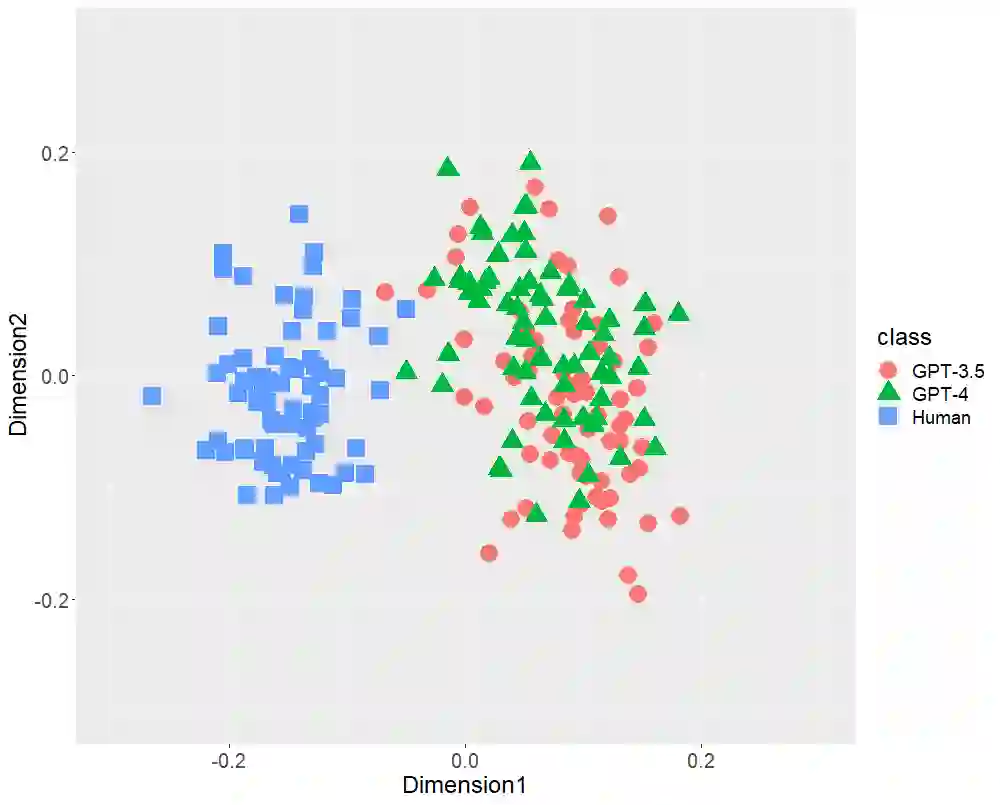
Text-generative artificial intelligence (AI), including ChatGPT, equipped with GPT-3.5 and GPT-4, from OpenAI, has attracted considerable attention worldwide. In this study, first, we compared Japanese stylometric features generated by GPT (-3.5 and -4) and those written by humans. In this work, we performed multi-dimensional scaling (MDS) to confirm the distributions of 216 texts of three classes (72 academic papers written by 36 single authors, 72 texts generated by GPT-3.5, and 72 texts generated by GPT-4 on the basis of the titles of the aforementioned papers) focusing on the following stylometric features: (1) bigrams of parts-of-speech, (2) bigram of postpositional particle words, (3) positioning of commas, and (4) rate of function words. MDS revealed distinct distributions at each stylometric feature of GPT (-3.5 and -4) and human. Although GPT-4 is more powerful than GPT-3.5 because it has more parameters, both GPT (-3.5 and -4) distributions are likely to overlap. These results indicate that although the number of parameters may increase in the future, AI-generated texts may not be close to that written by humans in terms of stylometric features. Second, we verified the classification performance of random forest (RF) for two classes (GPT and human) focusing on Japanese stylometric features. This study revealed the high performance of RF in each stylometric feature. Furthermore, the RF classifier focusing on the rate of function words achieved 98.1% accuracy. The RF classifier focusing on all stylometric features reached 100% in terms of all performance indexes (accuracy, recall, precision, and F1 score). This study concluded that at this stage we human discriminate ChatGPT from human limited to Japanese language.
翻译:文本生成人工智能(AI),包括配备OpenAI GPT-3.5和GPT-4的ChatGPT,已在全球范围内引起广泛关注。本研究首先比较了GPT(-3.5和-4)生成的日语文体特征与人类撰写的特征。我们采用多维尺度分析(MDS)技术,聚焦以下文体特征,对三类共216篇文本(36位独立作者撰写的72篇学术论文、基于上述论文标题由GPT-3.5生成的72篇文本及GPT-4生成的72篇文本)的分布进行确认:(1)词性二元组、(2)助词二元组、(3)逗号位置、(4)功能词占比。MDS分析显示GPT(-3.5和-4)与人类在每个文体特征上均呈现显著差异分布。尽管GPT-4因参数规模更大而性能强于GPT-3.5,但两者生成文本的分布存在重叠趋势。这些结果表明,尽管未来参数规模可能持续增长,但AI生成文本在文体特征上仍难以接近人类写作。其次,我们验证了随机森林(RF)在区分两类文本(GPT与人类)时针对日语文体特征的分类性能。研究发现RF在每个文体特征上均表现优异,其中基于功能词占比的RF分类器准确率达到98.1%,而整合所有文体特征的RF分类器在所有性能指标(准确率、召回率、精确率及F1分数)上均达到100%。本研究认为,当前阶段在日语限定条件下,人类仍能区分ChatGPT生成文本与人类撰写文本。