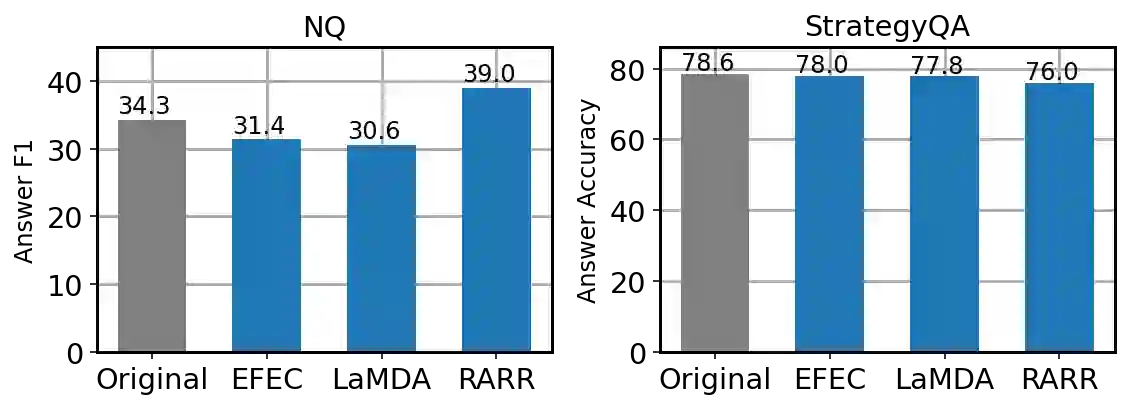
Language models (LMs) now excel at many tasks such as few-shot learning, question answering, reasoning, and dialog. However, they sometimes generate unsupported or misleading content. A user cannot easily determine whether their outputs are trustworthy or not, because most LMs do not have any built-in mechanism for attribution to external evidence. To enable attribution while still preserving all the powerful advantages of recent generation models, we propose RARR (Retrofit Attribution using Research and Revision), a system that 1) automatically finds attribution for the output of any text generation model and 2) post-edits the output to fix unsupported content while preserving the original output as much as possible. When applied to the output of several state-of-the-art LMs on a diverse set of generation tasks, we find that RARR significantly improves attribution while otherwise preserving the original input to a much greater degree than previously explored edit models. Furthermore, the implementation of RARR requires only a handful of training examples, a large language model, and standard web search.
翻译:摘要:语言模型(LMs)如今在少样本学习、问答、推理和对话等任务中表现优异。然而,它们有时会生成缺乏依据或具有误导性的内容。由于大多数语言模型不具备内置的外部证据归因机制,用户难以判断其输出是否可信。为了在保留当前生成模型强大优势的同时实现归因能力,我们提出RARR(利用研究与修订的后验归因)系统,该系统能够:1)自动为任意文本生成模型的输出寻找归因;2)对输出进行后期编辑,在最大限度保留原始输出的同时修正缺乏依据的内容。将RARR应用于多个最先进语言模型在多样化生成任务上的输出时,我们发现:与先前探索的编辑模型相比,RARR显著提升了归因能力,同时更大程度地保留了原始输入内容。此外,RARR的实现仅需少量训练样本、一个大型语言模型以及标准网络搜索。