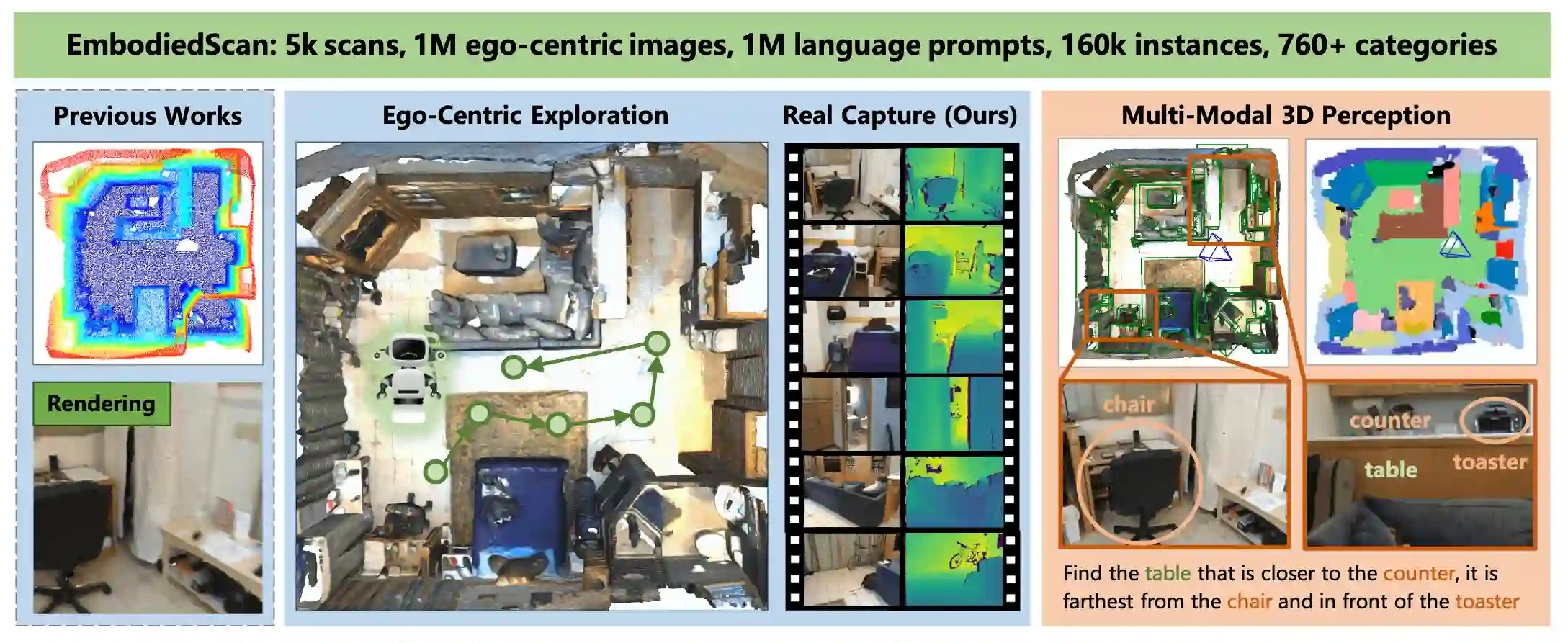
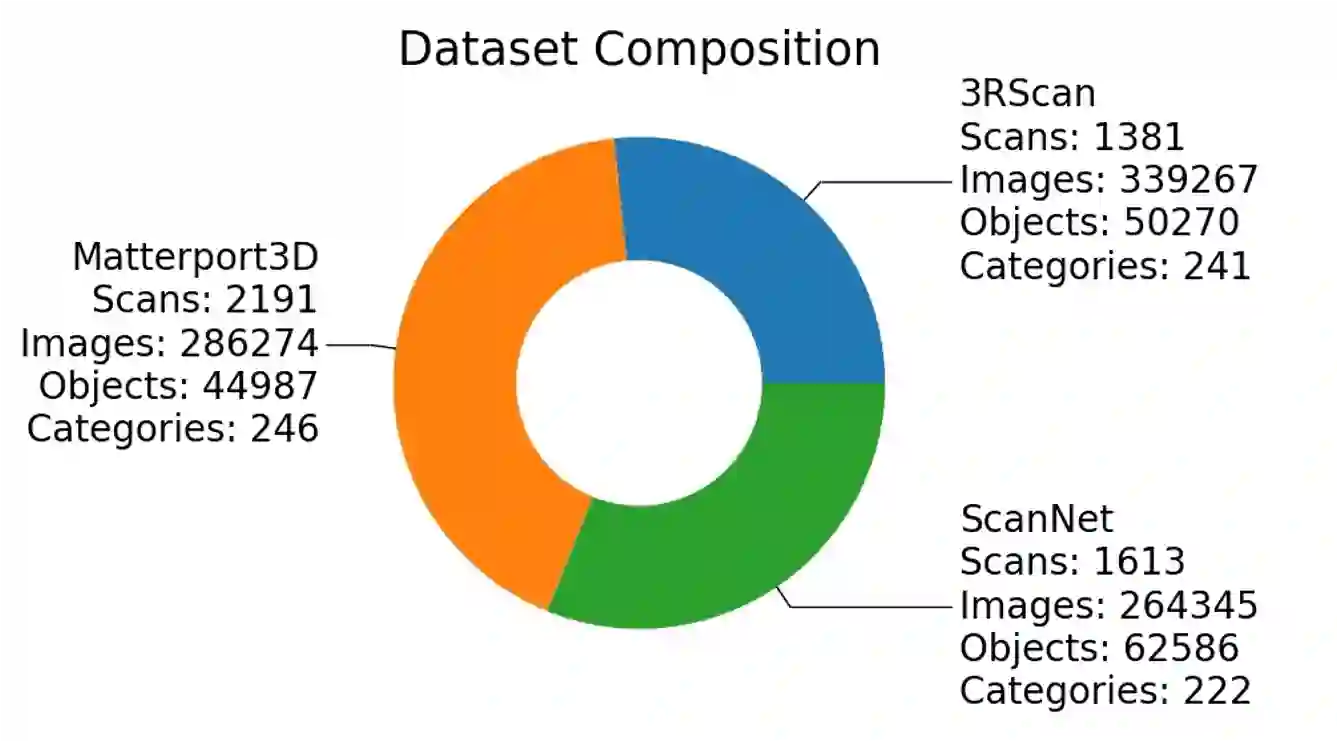
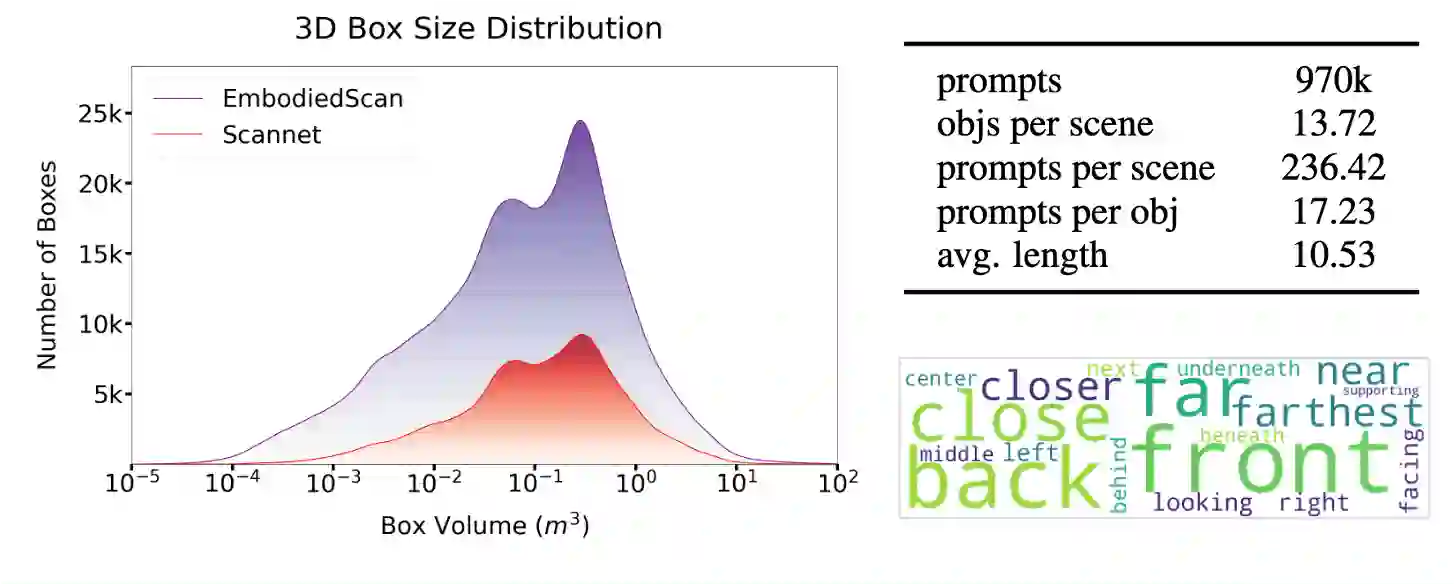
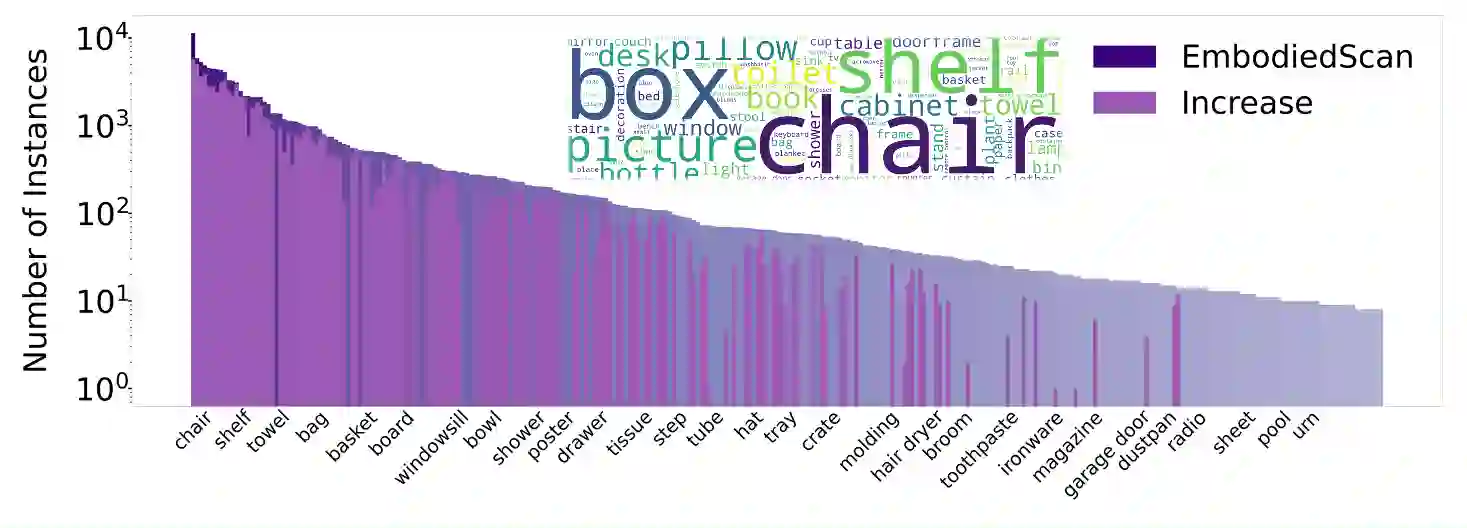
In the realm of computer vision and robotics, embodied agents are expected to explore their environment and carry out human instructions. This necessitates the ability to fully understand 3D scenes given their first-person observations and contextualize them into language for interaction. However, traditional research focuses more on scene-level input and output setups from a global view. To address the gap, we introduce EmbodiedScan, a multi-modal, ego-centric 3D perception dataset and benchmark for holistic 3D scene understanding. It encompasses over 5k scans encapsulating 1M ego-centric RGB-D views, 1M language prompts, 160k 3D-oriented boxes spanning over 760 categories, some of which partially align with LVIS, and dense semantic occupancy with 80 common categories. Building upon this database, we introduce a baseline framework named Embodied Perceptron. It is capable of processing an arbitrary number of multi-modal inputs and demonstrates remarkable 3D perception capabilities, both within the two series of benchmarks we set up, i.e., fundamental 3D perception tasks and language-grounded tasks, and in the wild. Codes, datasets, and benchmarks will be available at https://github.com/OpenRobotLab/EmbodiedScan.
翻译:在计算机视觉与机器人学领域,具身智能体需探索环境并执行人类指令。这要求智能体在获取第一人称观测后,能够全面理解三维场景,并将其转化为可交互的语言描述。然而,传统研究更侧重于全局视角下的场景级输入与输出设置。为弥合这一差距,我们提出EmbodiedScan——一个面向整体三维场景理解的多模态、第一人称三维感知数据集与基准平台。该数据集包含超过5000次扫描,涵盖100万张第一人称RGB-D视图、100万条语言提示、覆盖760个类别的16万个三维定向边界框(部分与LVIS类别对齐),以及80个常见类别的密集语义占据信息。基于此数据库,我们提出基准框架Embodied Perceptron,可处理任意数量的多模态输入,并在两大基准系列(基础三维感知任务与语言锚定任务)及真实场景中展现出卓越的三维感知能力。代码、数据集与基准平台将发布于https://github.com/OpenRobotLab/EmbodiedScan。