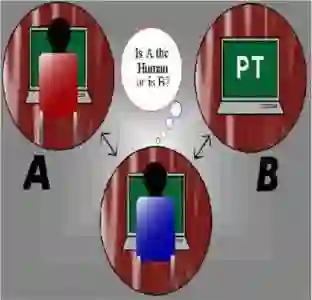
We introduce the Visual Personalization Turing Test (VPTT), a new paradigm for evaluating contextual visual personalization based on perceptual indistinguishability, rather than identity replication. A model passes the VPTT if its output (image, video, 3D asset, etc.) is indistinguishable to a human or calibrated VLM judge from content a given person might plausibly create or share. To operationalize VPTT, we present the VPTT Framework, integrating a 10k-persona benchmark (VPTT-Bench), a visual retrieval-augmented generator (VPRAG), and the VPTT Score, a text-only metric calibrated against human and VLM judgments. We show high correlation across human, VLM, and VPTT evaluations, validating the VPTT Score as a reliable perceptual proxy. Experiments demonstrate that VPRAG achieves the best alignment-originality balance, offering a scalable and privacy-safe foundation for personalized generative AI.
翻译:我们提出了视觉个性化图灵测试(VPTT),这是一种基于感知不可区分性而非身份复制的、用于评估上下文视觉个性化的新范式。如果一个模型的输出(图像、视频、3D资产等)对于人类或经过校准的视觉语言模型评判者而言,与给定个体可能合理创建或分享的内容无法区分,则该模型通过VPTT。为了实施VPTT,我们提出了VPTT框架,该框架集成了一个包含10,000个人物角色的基准测试(VPTT-Bench)、一个视觉检索增强生成器(VPRAG)以及VPTT分数——一种仅基于文本、并针对人类和视觉语言模型评判进行校准的度量标准。我们展示了人类评判、视觉语言模型评判和VPTT评估之间的高度相关性,从而验证了VPTT分数作为一种可靠的感知代理的有效性。实验表明,VPRAG在一致性与原创性之间取得了最佳平衡,为个性化生成式人工智能提供了一个可扩展且保护隐私的基础。