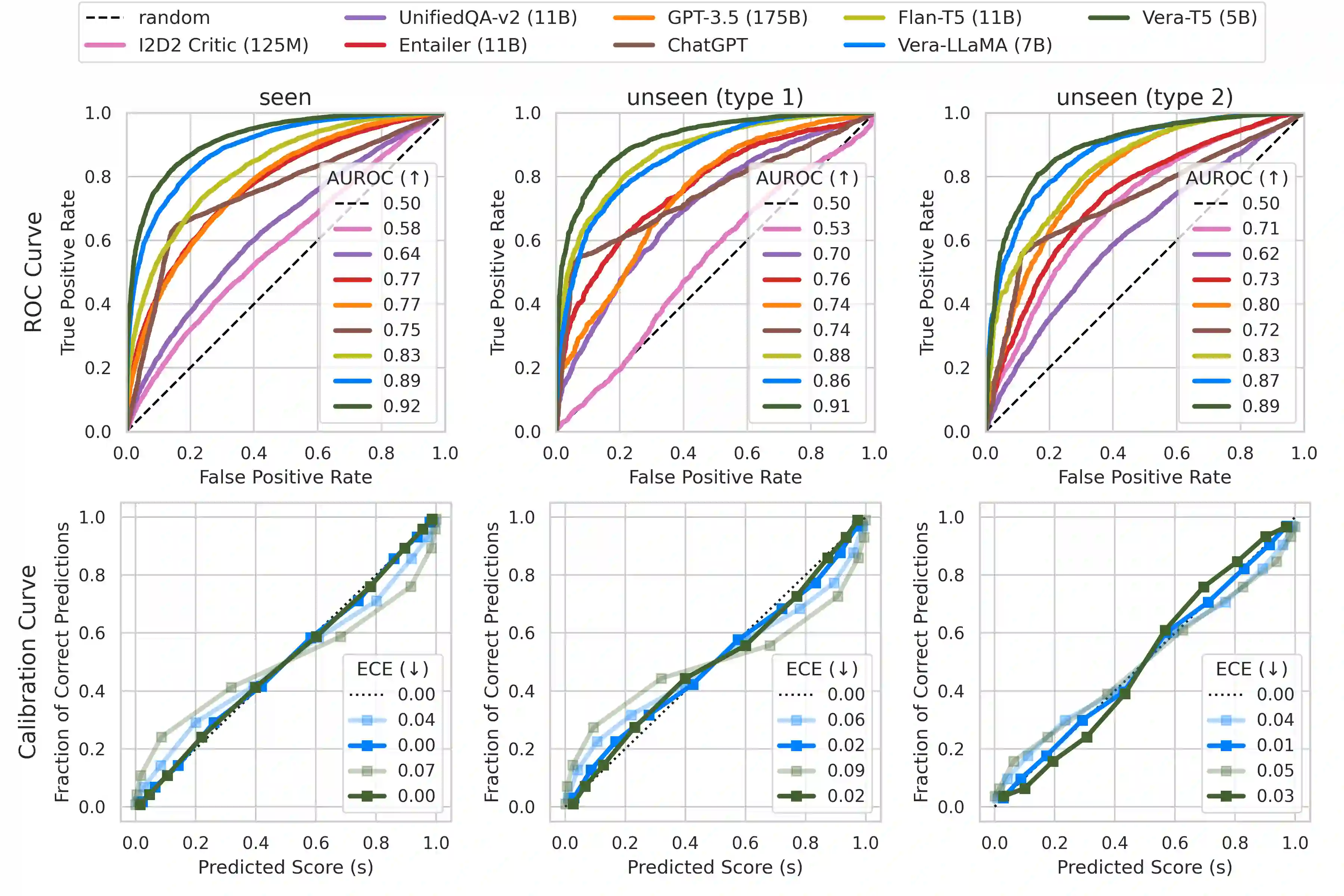
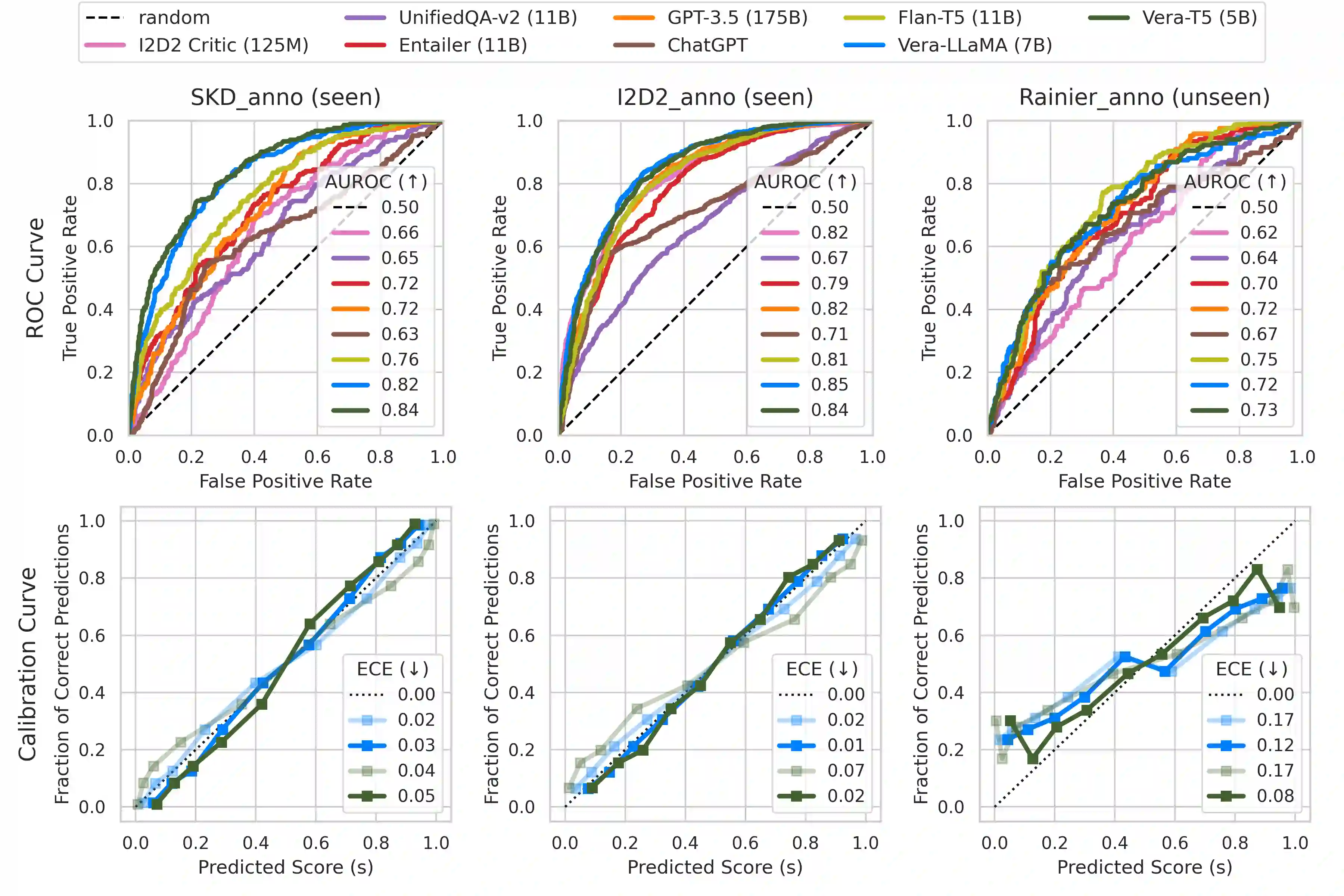
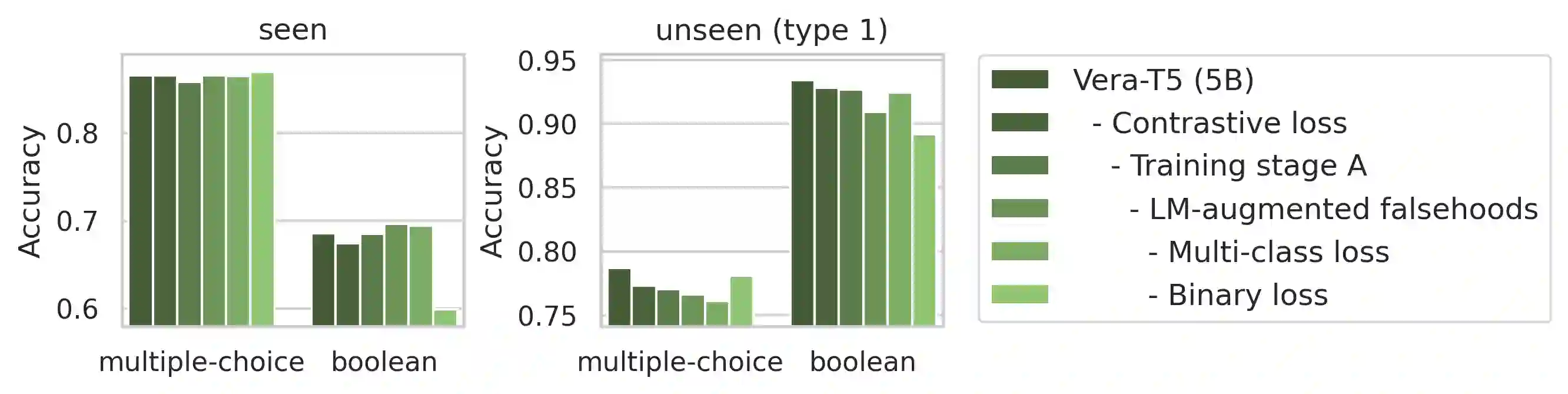
Despite the much discussed capabilities of today's language models, they are still prone to silly and unexpected commonsense failures. We consider a retrospective verification approach that reflects on the correctness of LM outputs, and introduce Vera, a general-purpose model that estimates the plausibility of declarative statements based on commonsense knowledge. Trained on ~7M commonsense statements created from 19 QA datasets and two large-scale knowledge bases, and with a combination of three training objectives, Vera is a versatile model that effectively separates correct from incorrect statements across diverse commonsense domains. When applied to solving commonsense problems in the verification format, Vera substantially outperforms existing models that can be repurposed for commonsense verification, and it further exhibits generalization capabilities to unseen tasks and provides well-calibrated outputs. We find that Vera excels at filtering LM-generated commonsense knowledge and is useful in detecting erroneous commonsense statements generated by models like ChatGPT in real-world settings.
翻译:尽管当今语言模型的能力备受讨论,它们仍容易犯下荒谬且出乎意料的常识性错误。我们采用一种回顾性验证方法,通过反思语言模型输出的正确性,并引入Vera——一种基于常识知识评估陈述性语句可信度的通用模型。该模型利用从19个问答数据集和两个大规模知识库构建的约700万条常识性陈述进行训练,结合三种训练目标,能够有效区分不同常识领域中正确与错误的陈述。当以验证形式应用于解决常识性问题时,Vera大幅优于现有可被重新用于常识验证的模型,并进一步展现出对未见任务的泛化能力,同时输出校准良好的结果。我们发现,Vera在过滤语言模型生成的常识知识方面表现出色,并有助于检测现实场景中如ChatGPT等模型生成的错误常识性陈述。