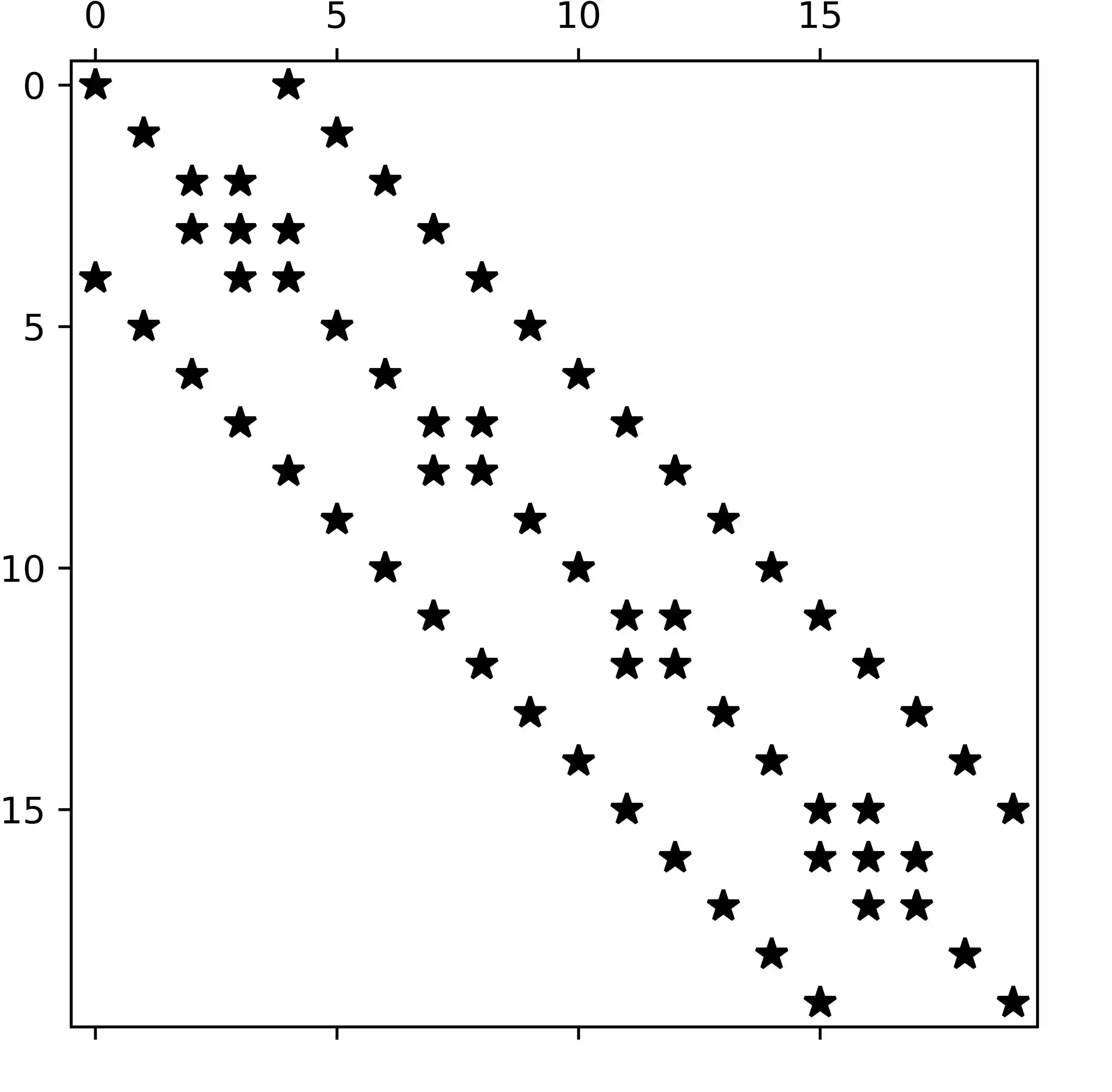
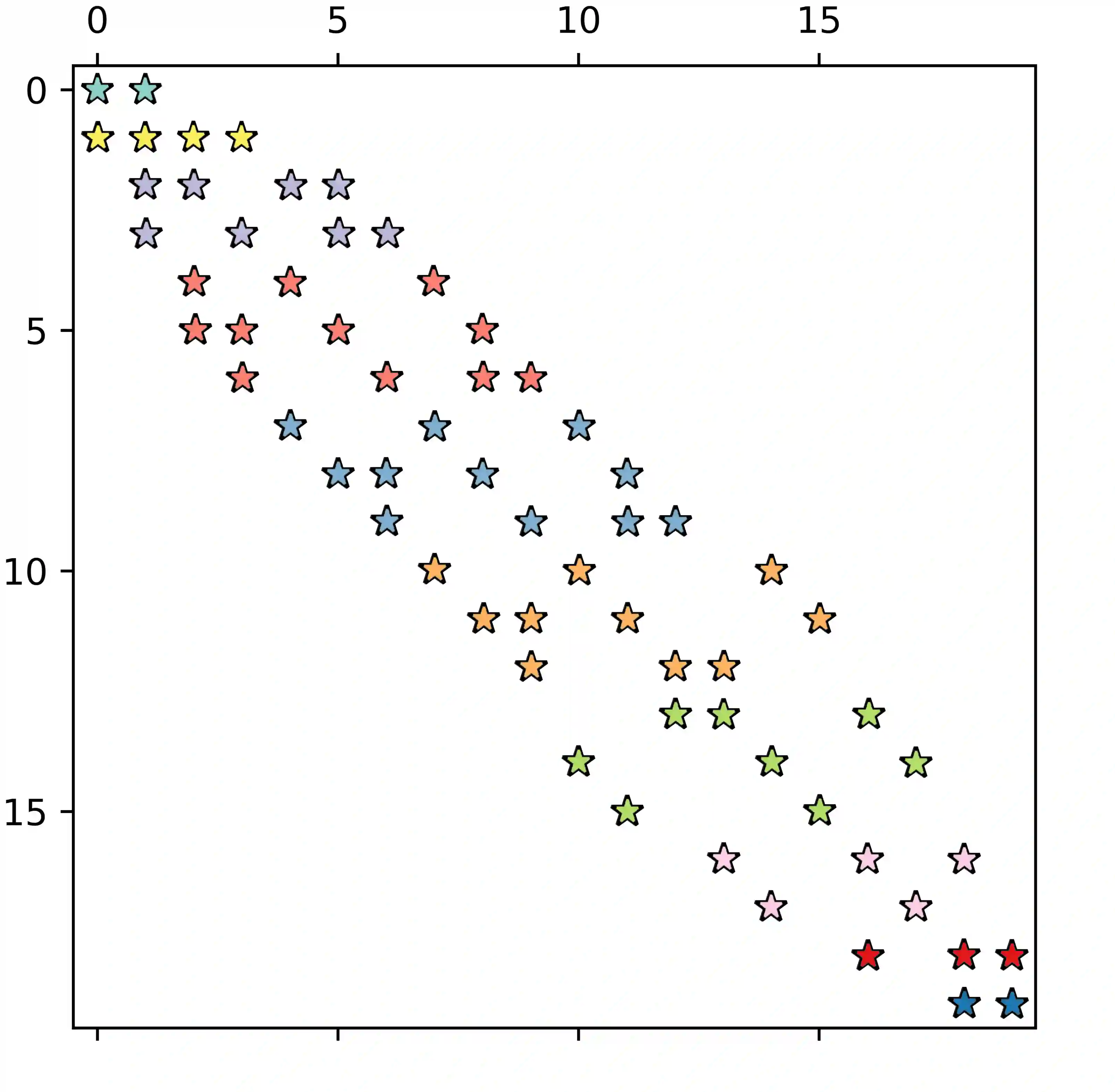
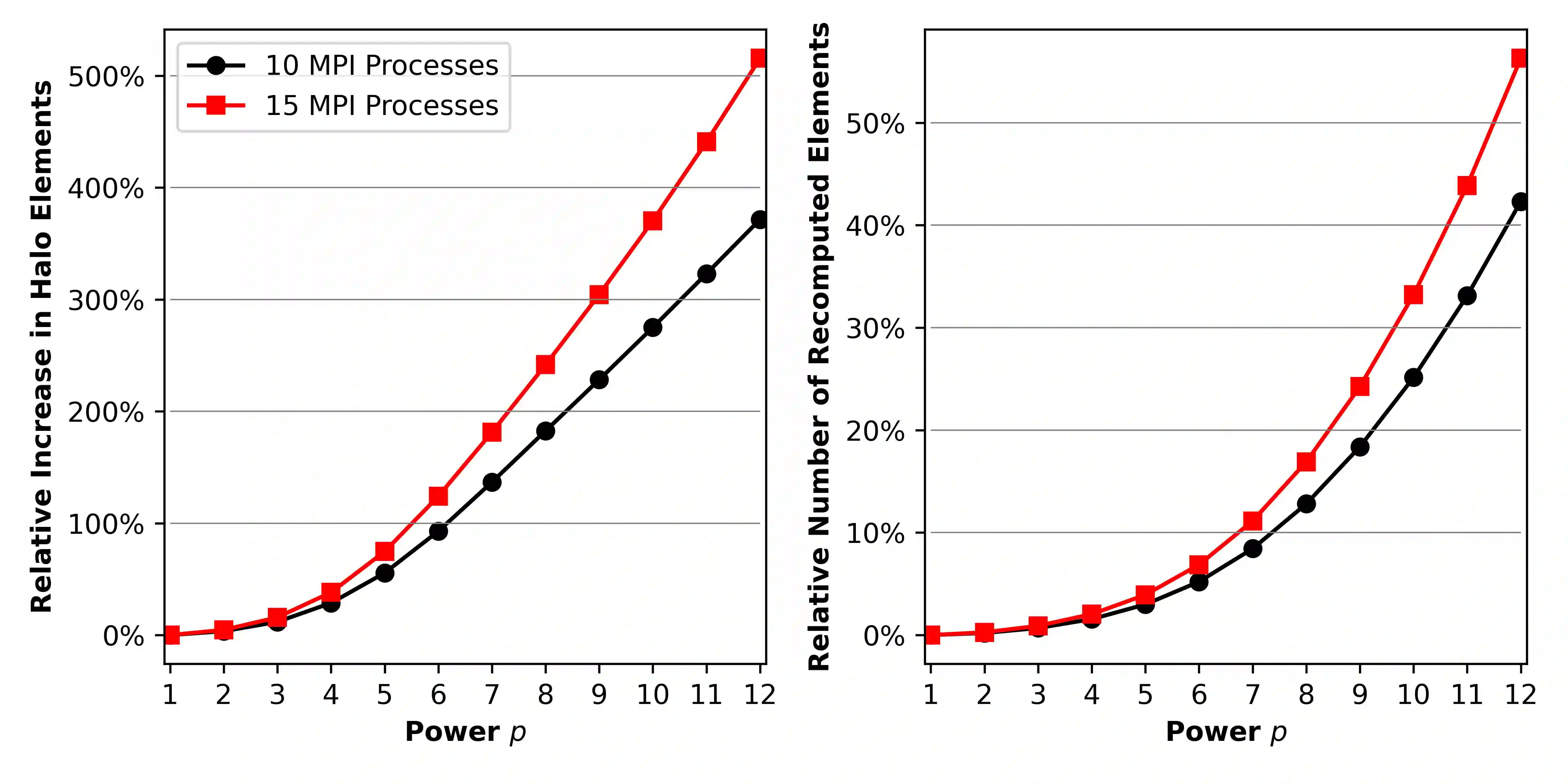
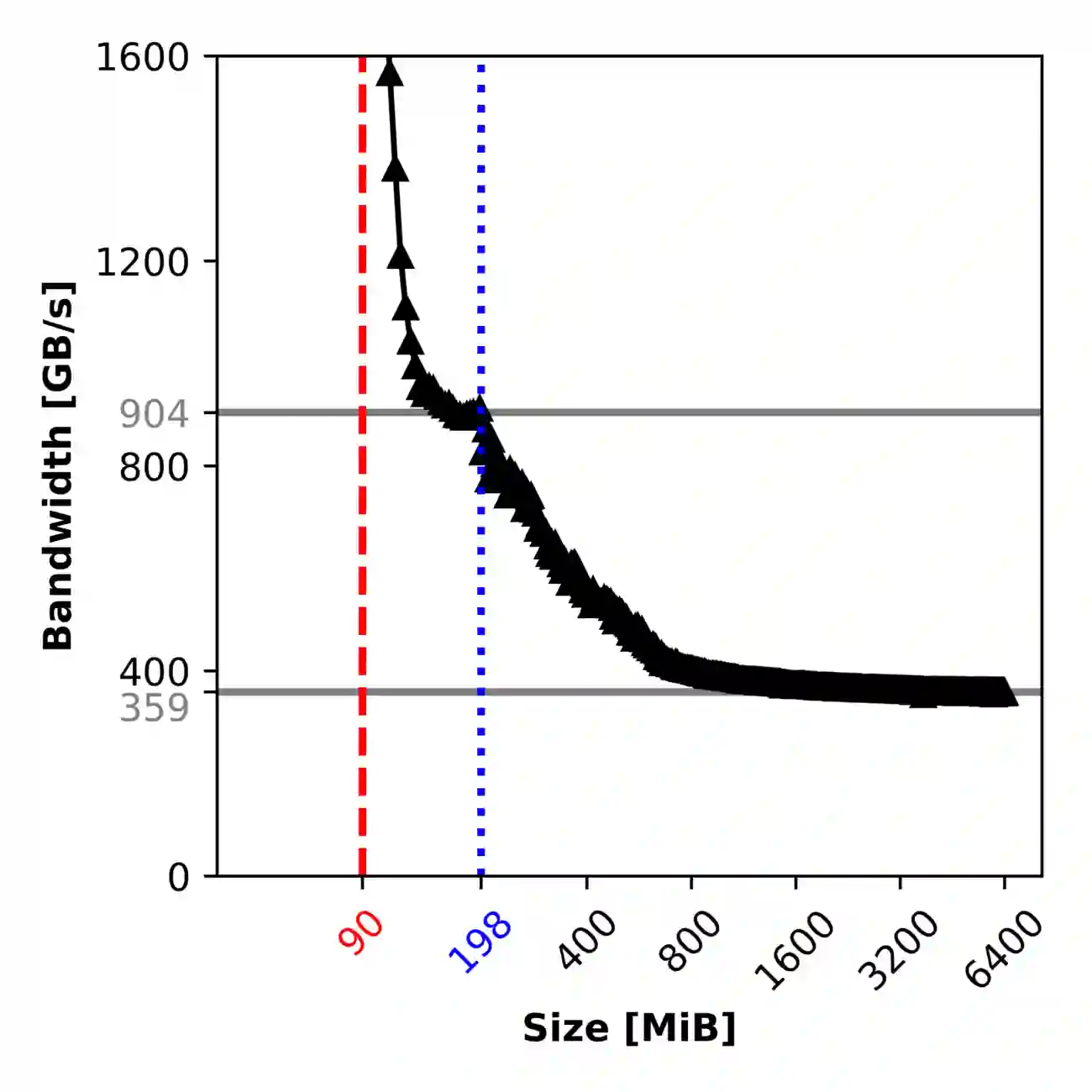
Sparse matrix-vector products (SpMVs) are a bottleneck in many scientific codes. Due to the heavy strain on the main memory interface from loading the sparse matrix and the possibly irregular memory access pattern, SpMV typically exhibits low arithmetic intensity. Repeating these products multiple times with the same matrix is required in many algorithms. This so-called matrix power kernel (MPK) provides an opportunity for data reuse since the same matrix data is loaded from main memory multiple times, an opportunity that has only recently been exploited successfully with the Recursive Algebraic Coloring Engine (RACE). Using RACE, one considers a graph based formulation of the SpMV and employs s level-based implementation of SpMV for reuse of relevant matrix data. However, the underlying data dependencies have restricted the use of this concept to shared memory parallelization and thus to single compute nodes. Enabling cache blocking for distributed-memory parallelization of MPK is challenging due to the need for explicit communication and synchronization of data in neighboring levels. In this work, we propose and implement a flexible method that interleaves the cache-blocking capabilities of RACE with an MPI communication scheme that fulfills all data dependencies among processes. Compared to a "traditional" distributed memory parallel MPK, our new Distributed Level-Blocked MPK yields substantial speed-ups on modern Intel and AMD architectures across a wide range of sparse matrices from various scientific applications. Finally, we address a modern quantum physics problem to demonstrate the applicability of our method, achieving a speed-up of up to 4x on 832 cores of an Intel Sapphire Rapids cluster.
翻译:稀疏矩阵-向量乘积(SpMV)是众多科学计算代码中的性能瓶颈。由于加载稀疏矩阵对主存接口造成的沉重压力以及可能的不规则内存访问模式,SpMV通常表现出较低的算术强度。许多算法需要重复使用同一矩阵进行多次此类乘积运算。这种被称为矩阵幂核(MPK)的操作为实现数据复用提供了契机,因为相同的矩阵数据会多次从主存加载——这一契机直到最近才通过递归代数着色引擎(RACE)得以成功利用。基于RACE的方法将SpMV转化为图论形式,并采用层级化SpMV实现以复用相关矩阵数据。然而,其底层数据依赖性限制了该技术仅能用于共享内存并行化,因而只能局限于单计算节点。为实现MPK在分布式内存并行化中的缓存分块,由于需要显式通信和同步相邻层级间的数据,该任务极具挑战性。本研究提出并实现了一种灵活方法,将RACE的缓存分块能力与满足进程间所有数据依赖性的MPI通信方案相结合。相较于"传统"分布式内存并行MPK,我们提出的分布式层级分块MPK在英特尔和AMD现代架构上,针对来自不同科学应用领域的各类稀疏矩阵均实现了显著加速。最后,我们通过求解现代量子物理问题验证了该方法的实用性,在英特尔Sapphire Rapids集群的832个核心上实现了高达4倍的加速比。