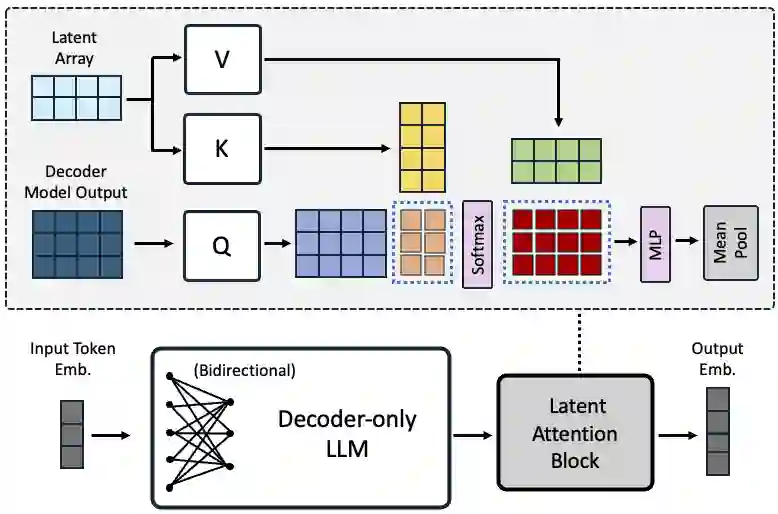
Decoder-only large language model (LLM)-based embedding models are beginning to outperform BERT or T5-based embedding models in general-purpose text embedding tasks, including dense vector-based retrieval. In this work, we introduce the NV-Embed model with a variety of architectural designs and training procedures to significantly enhance the performance of LLM as a versatile embedding model, while maintaining its simplicity and reproducibility. For model architecture, we propose a latent attention layer to obtain pooled embeddings, which consistently improves retrieval and downstream task accuracy compared to mean pooling or using the last <EOS> token embedding from LLMs. To enhance representation learning, we remove the causal attention mask of LLMs during contrastive training. For model training, we introduce a two-stage contrastive instruction-tuning method. It first applies contrastive training with instructions on retrieval datasets, utilizing in-batch negatives and curated hard negative examples. At stage-2, it blends various non-retrieval datasets into instruction tuning, which not only enhances non-retrieval task accuracy but also improves retrieval performance. Combining these techniques, our NV-Embed model, using only publicly available data, has achieved a record-high score of 69.32, ranking No. 1 on the Massive Text Embedding Benchmark (MTEB) (as of May 24, 2024), with 56 tasks, encompassing retrieval, reranking, classification, clustering, and semantic textual similarity tasks. Notably, our model also attains the highest score of 59.36 on 15 retrieval tasks in the MTEB benchmark (also known as BEIR). We will open-source the model at: https://huggingface.co/nvidia/NV-Embed-v1.
翻译:基于仅解码器大语言模型的嵌入模型,在包括基于稠密向量的检索在内的通用文本嵌入任务中,开始超越基于BERT或T5的嵌入模型。在本工作中,我们介绍了NV-Embed模型,它通过一系列架构设计和训练流程的改进,显著提升了LLM作为通用嵌入模型的性能,同时保持了其简洁性和可复现性。在模型架构方面,我们提出了一种潜在注意力层来获取池化后的嵌入表示,与对LLM输出进行均值池化或使用最后一个<EOS>标记嵌入相比,该方法持续提升了检索和下游任务的准确率。为了增强表示学习,我们在对比训练期间移除了LLM的因果注意力掩码。在模型训练方面,我们引入了一种两阶段的对比指令微调方法。第一阶段在检索数据集上应用带指令的对比训练,利用批次内负例和精心构建的难负例。第二阶段,将多种非检索数据集混合进行指令微调,这不仅提升了非检索任务的准确率,也改善了检索性能。结合这些技术,我们的NV-Embed模型仅使用公开可用的数据,就在大规模文本嵌入基准测试中取得了创纪录的69.32分(截至2024年5月24日),在包含检索、重排序、分类、聚类和语义文本相似性任务的56项任务中排名第一。值得注意的是,我们的模型在MTEB基准测试(也称为BEIR)的15项检索任务中也获得了最高分59.36。我们将在以下地址开源模型:https://huggingface.co/nvidia/NV-Embed-v1。