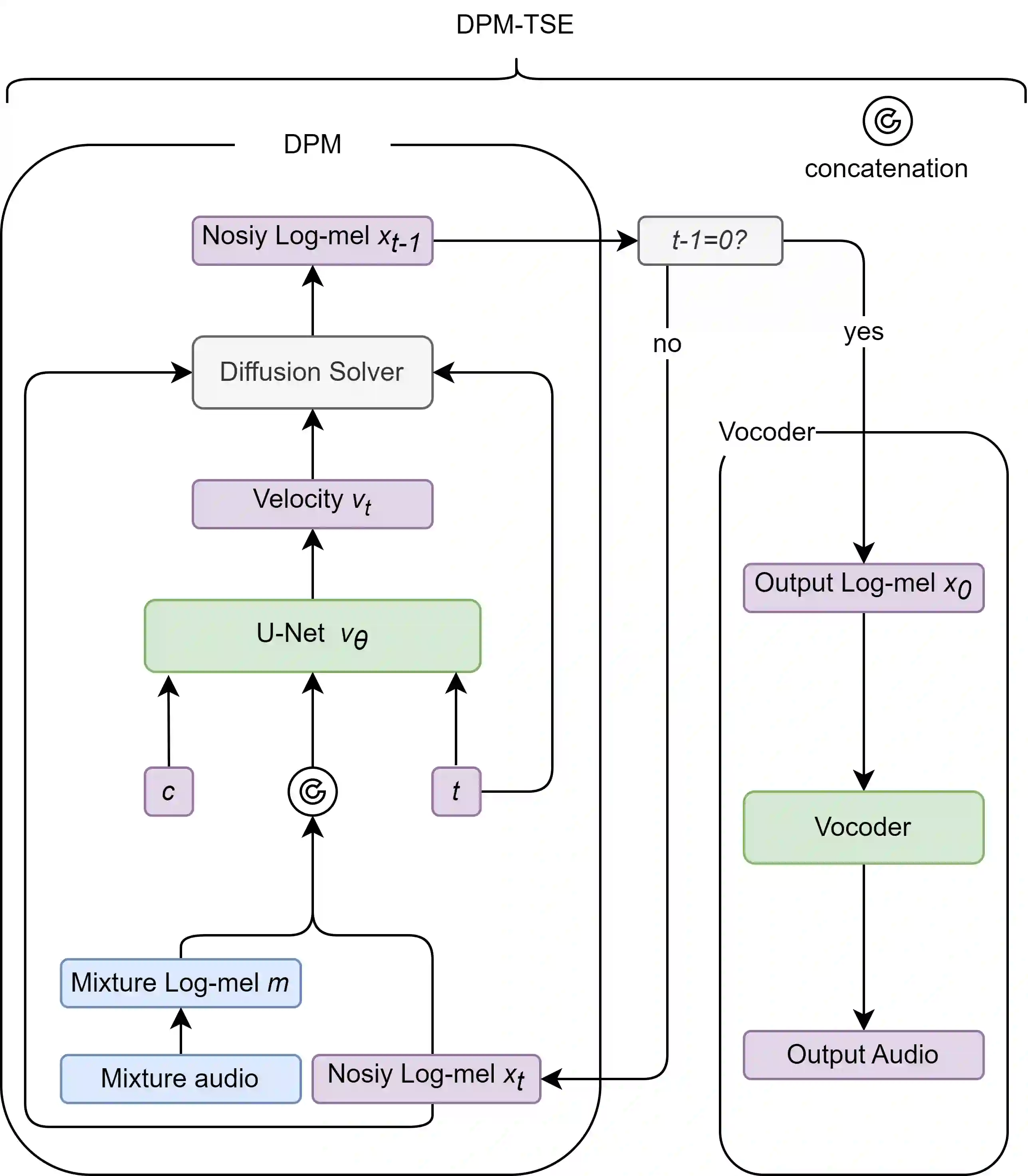
Common target sound extraction (TSE) approaches primarily relied on discriminative approaches in order to separate the target sound while minimizing interference from the unwanted sources, with varying success in separating the target from the background. This study introduces DPM-TSE, a first generative method based on diffusion probabilistic modeling (DPM) for target sound extraction, to achieve both cleaner target renderings as well as improved separability from unwanted sounds. The technique also tackles common background noise issues with DPM by introducing a correction method for noise schedules and sample steps. This approach is evaluated using both objective and subjective quality metrics on the FSD Kaggle 2018 dataset. The results show that DPM-TSE has a significant improvement in perceived quality in terms of target extraction and purity.
翻译:常见的目标声音提取方法主要依赖判别式方法,通过最小化无关声源的干扰来分离目标声音,在分离目标与背景方面取得了不同程度的成效。本研究提出DPM-TSE——一种基于扩散概率模型(DPM)的生成式目标声音提取方法,旨在实现更纯净的目标声音渲染并提升与无关声音的分离能力。该技术还通过引入噪声调度和采样步骤的校正方法,解决了DPM中常见的背景噪声问题。我们在FSD Kaggle 2018数据集上采用客观和主观质量指标对该方法进行了评估。结果表明,DPM-TSE在目标提取的感知质量和纯度方面均有显著提升。