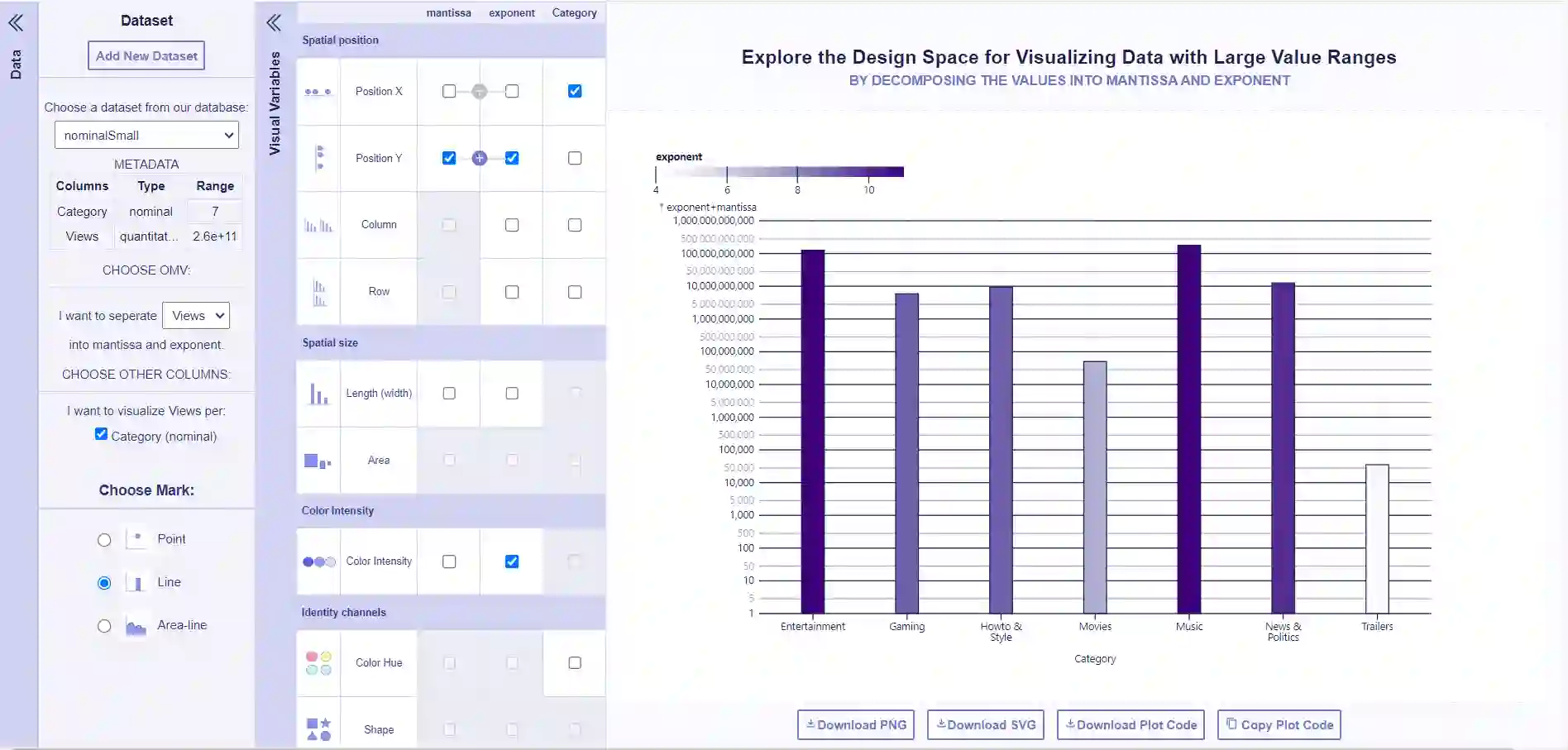
We explore the design space for the static visualization of datasets with quantitative attributes that vary over multiple orders of magnitude-we call these attributes Orders of Magnitude Values (OMVs)-and provide design guidelines and recommendations on effective visual encodings for OMVs. Current charts rely on linear or logarithmic scales to visualize values, leading to limitations in performing simple tasks for OMVs. In particular, linear scales prevent the reading of smaller magnitudes and their comparisons, while logarithmic scales are challenging for the general public to understand. Our design space leverages the approach of dividing OMVs into two different parts: mantissa and exponent, in a way similar to scientific notation. This separation allows for a visual encoding of both parts. For our exploration, we use four datasets, each with two attributes: an OMV, divided into mantissa and exponent, and a second attribute that is nominal, ordinal, time, or quantitative. We start from the original design space described by the Grammar of Graphics and systematically generate all possible visualizations for these datasets, employing different marks and visual channels. We refine this design space by enforcing integrity constraints from visualization and graphical perception literature. Through a qualitative assessment of all viable combinations, we discuss the most effective visualizations for OMVs, focusing on channel and task effectiveness. The article's main contributions are 1) the presentation of the design space of OMVs, 2) the generation of a large number of OMV visualizations, among which some are novel and effective, 3) the refined definition of a scale that we call E+M for OMVs, and 4) guidelines and recommendations for designing effective OMV visualizations. These efforts aim to enrich visualization systems to better support data with OMVs and guide future research.
翻译:本文探索了定量属性跨越多个数量级变化的数据集(我们将此类属性称为“数量级值”)的静态可视化设计空间,并针对OMV的有效视觉编码提供了设计指南与建议。当前图表主要依赖线性或对数尺度进行数值可视化,导致在OMV的简单任务执行上存在局限:线性尺度会阻碍对小数量级的读取与比较,而对数尺度则对普通公众造成理解困难。我们的设计空间借鉴了将OMV拆分为尾数和指数两部分的方法(类似科学记数法),这种分离使得对这两部分进行视觉编码成为可能。在探索过程中,我们使用了四个数据集,每个数据集包含两个属性:一个被拆分为尾数和指数的OMV,以及另一个名义型、有序型、时间型或定量型的第二属性。我们从图形语法描述的原始设计空间出发,采用不同的标记和视觉通道,系统性地生成了这些数据集的所有可能可视化方案。通过施加来自可视化与图形感知文献的完整性约束,我们对设计空间进行了精炼。在对所有可行组合进行定性评估后,我们聚焦于通道与任务有效性,讨论了最有效的OMV可视化方案。本文的主要贡献包括:1)呈现OMV的设计空间;2)生成大量OMV可视化方案(其中部分为新颖且有效的设计);3)精确定义了一种针对OMV的E+M尺度;4)提出设计有效OMV可视化的指南与建议。这些工作旨在丰富可视化系统以更好地支持OMV数据,并为未来研究提供指引。