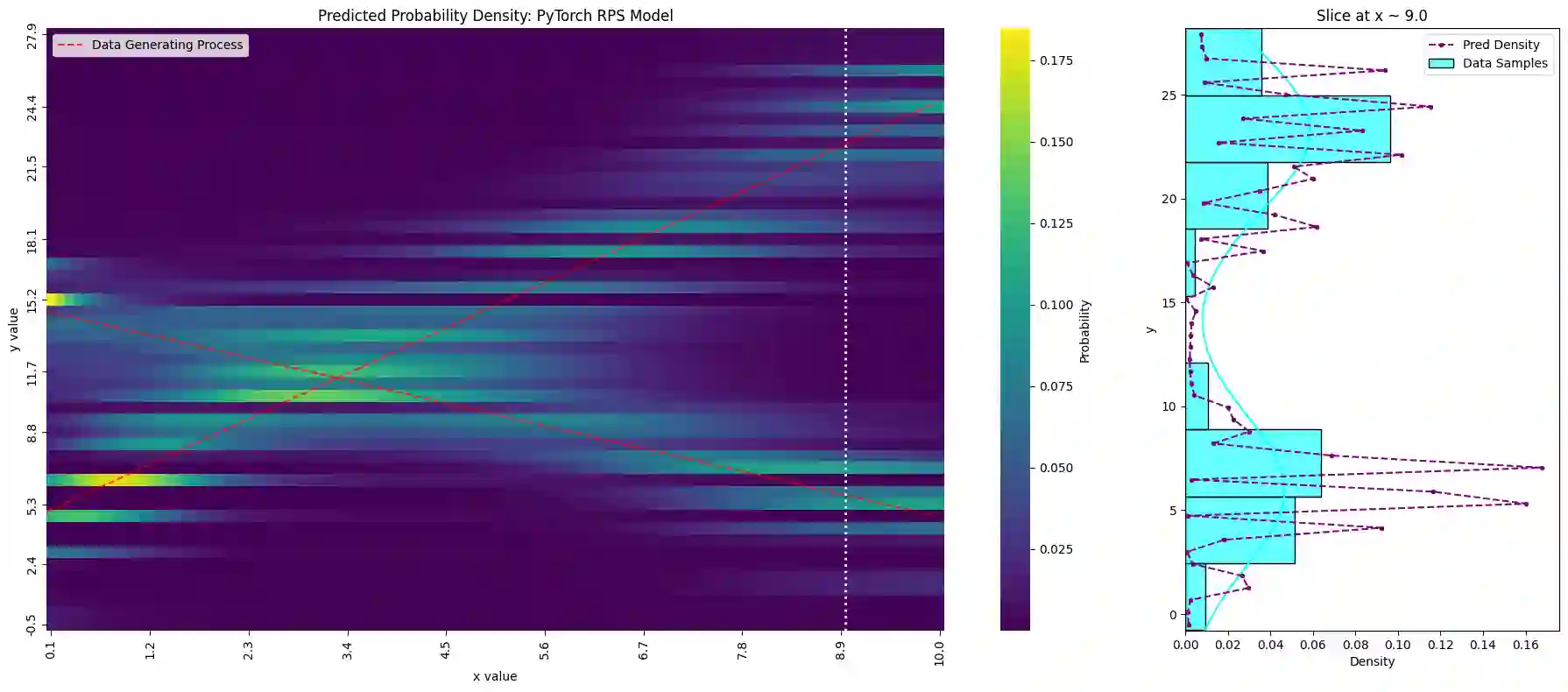
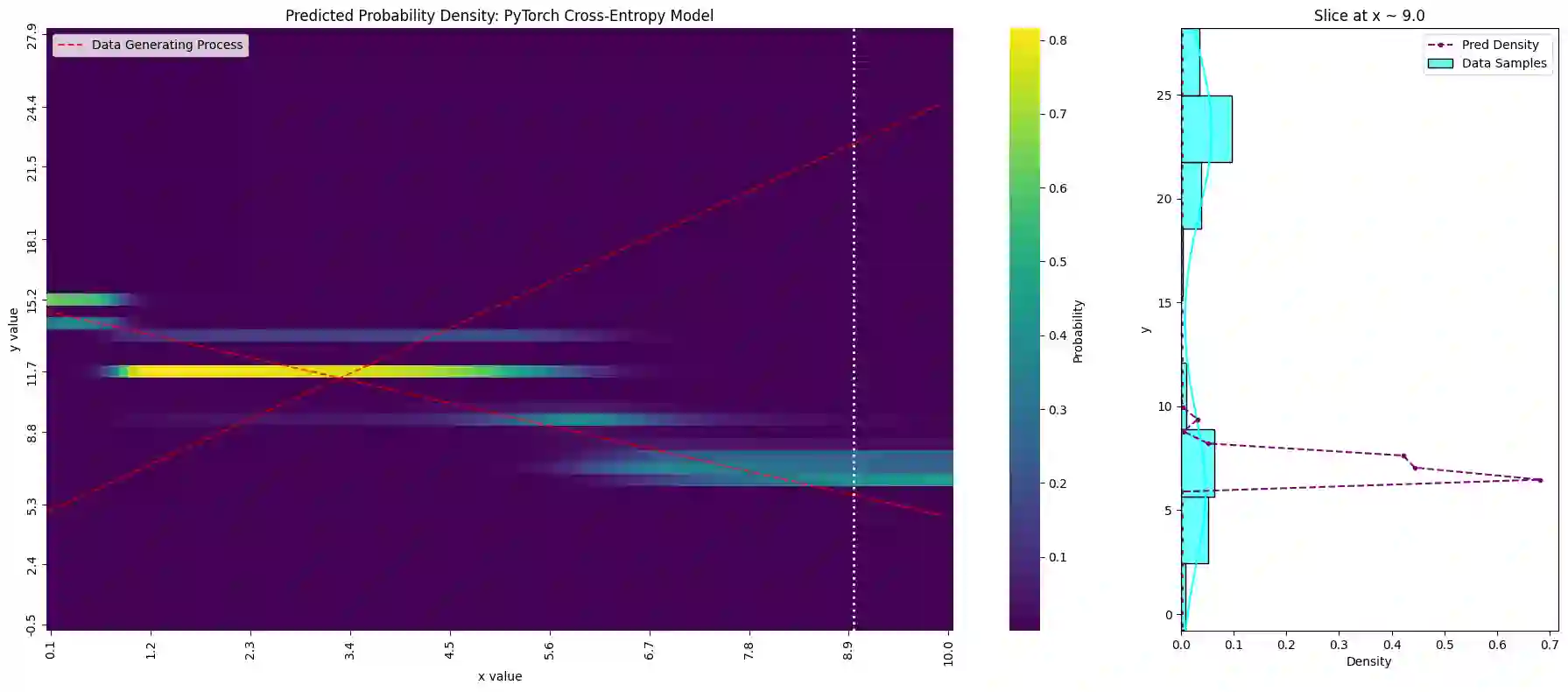
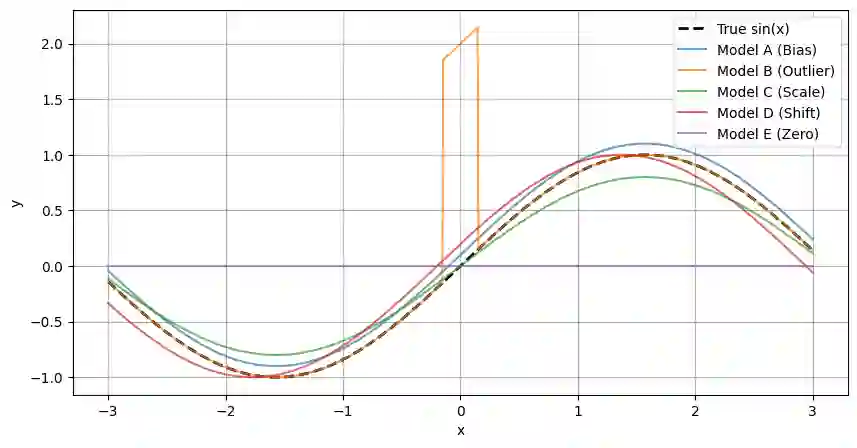
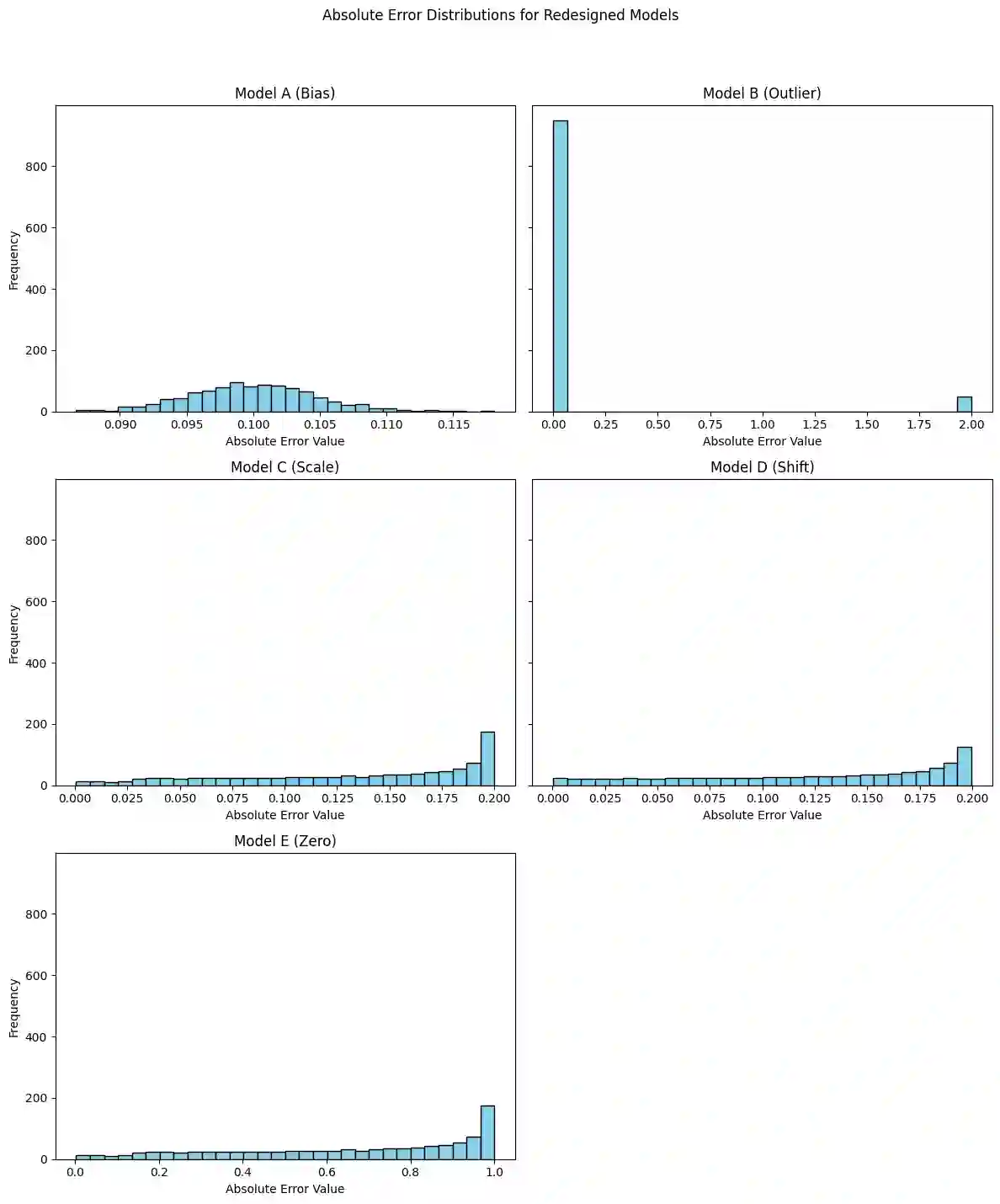
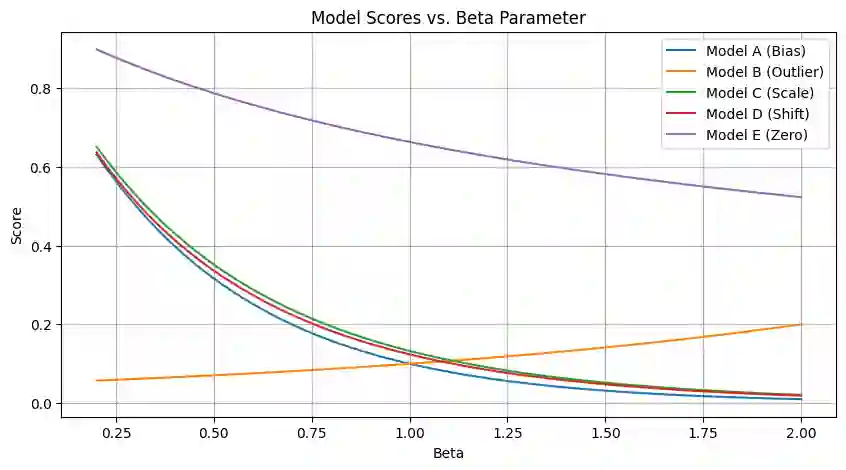
Tabular foundation models such as TabPFN and TabICL already produce full predictive distributions, yet the benchmarks used to evaluate them (TabArena, TALENT, and others) still rely almost exclusively on point-estimate metrics (RMSE, $R^2$). This mismatch implicitly rewards models that elicit a good conditional mean while ignoring the quality of the predicted distribution. We make two contributions. First, we propose supplementing standard point metrics with proper scoring rules (CRPS, CRLS, and the Interval Score) and provide a head-to-head comparison of realTabPFNv2.5 and TabICLv2 with regards to some proper scoring rules across 20 OpenML regression datasets. Second, we show analytically and empirically that different proper scoring rules induce different model rankings and different inductive biases during training, even though each rule is individually minimized by the true distribution. Fine-tuning realTabPFNv2.5 with scoring rules not seen during pretraining (CRLS, $β=1.8$ energy score) yields consistent improvements on the corresponding metrics, confirming that the training loss shapes the model beyond what propriety alone guarantees. Together, these findings argue for (i) reporting distributional metrics in tabular regression benchmarks and (ii) making the training objective of foundation models adaptable (via fine-tuning or task-token conditioning) to the scoring rule relevant to the downstream decision problem.
翻译:诸如TabPFN和TabICL等表格基础模型已能生成完整的预测分布,然而用于评估它们的基准测试(TabArena、TALENT等)仍几乎完全依赖点估计指标(RMSE、$R^2$)。这种不匹配隐式地奖励那些能产生良好条件均值但忽略预测分布质量的模型。我们做出两项贡献。首先,我们建议用恰当评分规则(CRPS、CRLS及区间评分)补充标准点估计指标,并在20个OpenML回归数据集上对realTabPFNv2.5和TabICLv2就部分恰当评分规则进行了直接比较。其次,我们从分析和实证角度证明,不同的恰当评分规则会诱导不同的模型排序和训练过程中的不同归纳偏好,尽管每个规则本身均被真实分布最小化。使用预训练期间未见的评分规则(CRLS、$β=1.8$能量评分)对realTabPFNv2.5进行微调,可在相应指标上获得一致改进,这证实训练损失对模型的塑造作用超出了恰当性本身所保证的范围。综上,这些发现主张:(i)在表格回归基准测试中报告分布度量指标;(ii)通过微调或任务令牌调节,使基础模型的训练目标能适配下游决策问题相关的评分规则。