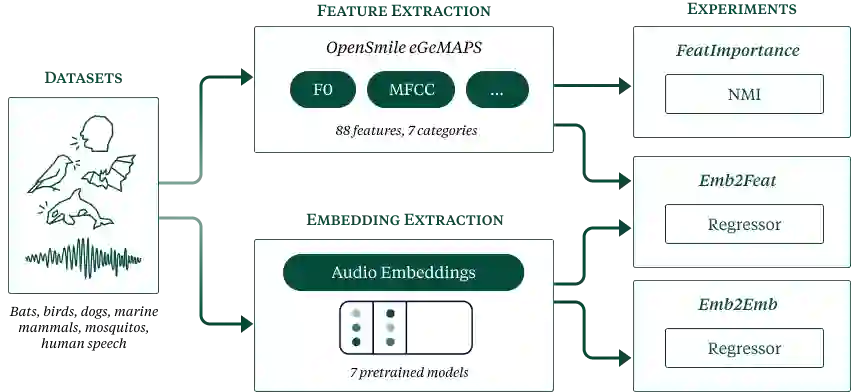
Pretrained audio embeddings are standard in bioacoustics, yet little is known about which acoustic features these models encode, nor which are useful for a given task. This hinders transparency and limits extension to rare species or data-scarce domains. Here we reveal which speech-like features are encoded in bioacoustic representations. Using the 88~eGeMAPS features across six taxonomic groups, we apply linear and nonlinear regression probes to quantify which acoustic properties each model captures. Results confirm a ``no free lunch'' pattern: no single model captures the full feature space. A concatenated embedding achieves the highest performance, suggesting complementary acoustic space coverage across models. Loudness features are best encoded ($R^2 = 0.76$) while F0 is hardest to recover ($R^2 = 0.33$). By cross-referencing recoverability with per-species feature salience (NMI), we derive data-driven model selection guidance for bioacoustics.
翻译:预训练的音频嵌入已成为生物声学领域的标准工具,然而这些模型编码了哪些声学特征以及哪些特征对特定任务有用仍鲜为人知。这阻碍了模型的可解释性,并限制了向稀有物种或数据稀缺领域的推广应用。本文揭示了生物声学表征中编码了哪些类语音特征。通过使用涵盖六个分类学类群的88个eGeMAPS特征,我们分别应用线性和非线性回归探针来量化每个模型捕获的声学属性。结果印证了"没有免费午餐"模式:没有任何单一模型能捕捉到完整的特征空间。采用拼接嵌入可获得最佳性能,表明不同模型在声学空间覆盖上具有互补性。响度特征最易被编码(R² = 0.76),而基频F0最难恢复(R² = 0.33)。通过将特征可恢复性与物种特异性特征显著性(NMI)进行交叉参照,我们为生物声学领域提供了数据驱动的模型选择指导。