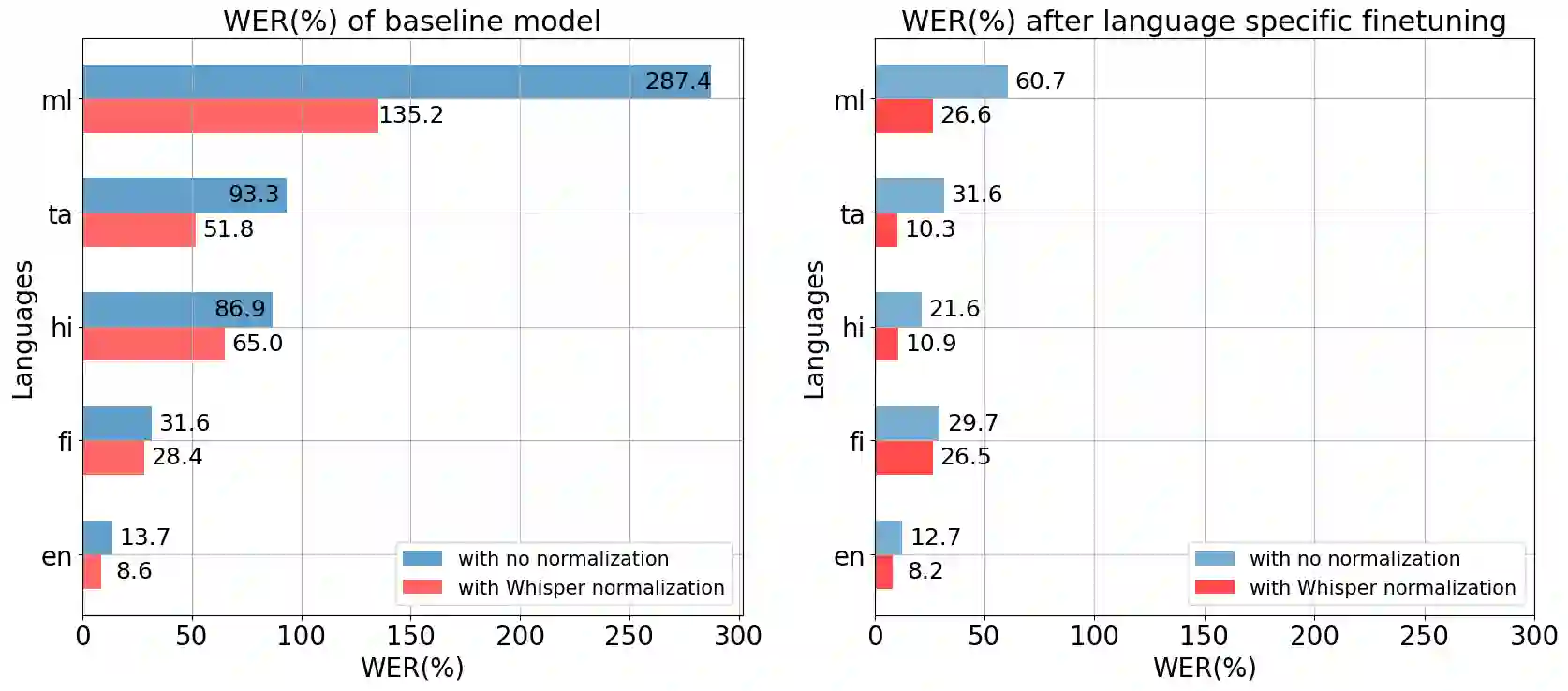
This paper explores the pitfalls in evaluating multilingual automatic speech recognition (ASR) models, with a particular focus on Indic language scripts. We investigate the text normalization routine employed by leading ASR models, including OpenAI Whisper, Meta's MMS, Seamless, and Assembly AI's Conformer, and their unintended consequences on performance metrics. Our research reveals that current text normalization practices, while aiming to standardize ASR outputs for fair comparison, by removing inconsistencies such as variations in spelling, punctuation, and special characters, are fundamentally flawed when applied to Indic scripts. Through empirical analysis using text similarity scores and in-depth linguistic examination, we demonstrate that these flaws lead to artificially improved performance metrics for Indic languages. We conclude by proposing a shift towards developing text normalization routines that leverage native linguistic expertise, ensuring more robust and accurate evaluations of multilingual ASR models.
翻译:本文探讨了评估多语言自动语音识别(ASR)模型时存在的陷阱,特别关注印度语系文字。我们研究了包括OpenAI Whisper、Meta的MMS、Seamless以及Assembly AI的Conformer在内的主流ASR模型所采用的文本归一化流程,及其对性能指标产生的意外影响。我们的研究表明,当前的文本归一化实践旨在通过消除拼写、标点和特殊字符的不一致性来标准化ASR输出以进行公平比较,但在应用于印度语系文字时存在根本性缺陷。通过使用文本相似度评分进行实证分析并结合深入的语言学检验,我们证明这些缺陷导致印度语言的性能指标被人为提升。最后,我们建议转向开发能够利用本土语言学专业知识的文本归一化流程,以确保对多语言ASR模型进行更稳健和准确的评估。