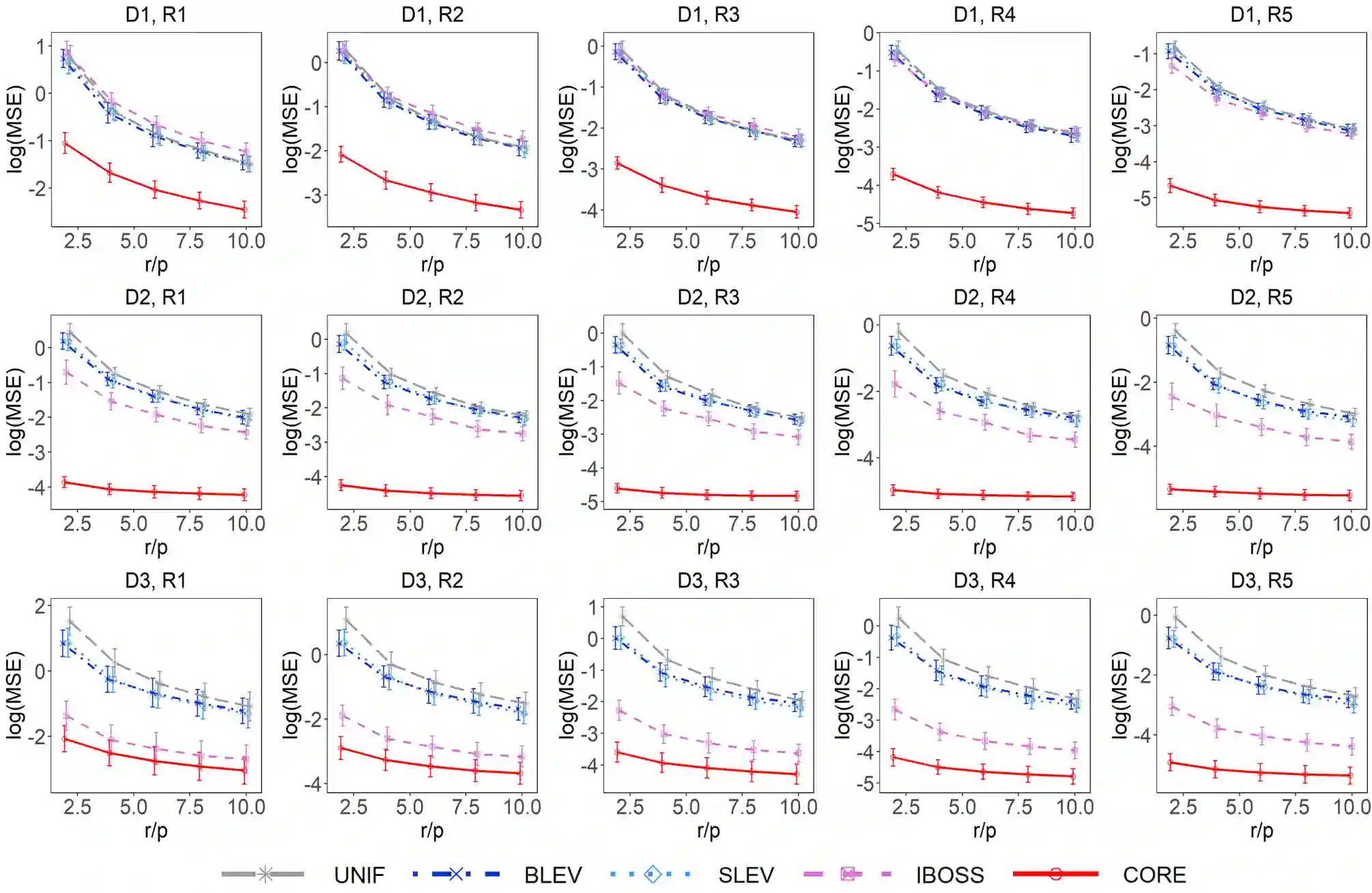
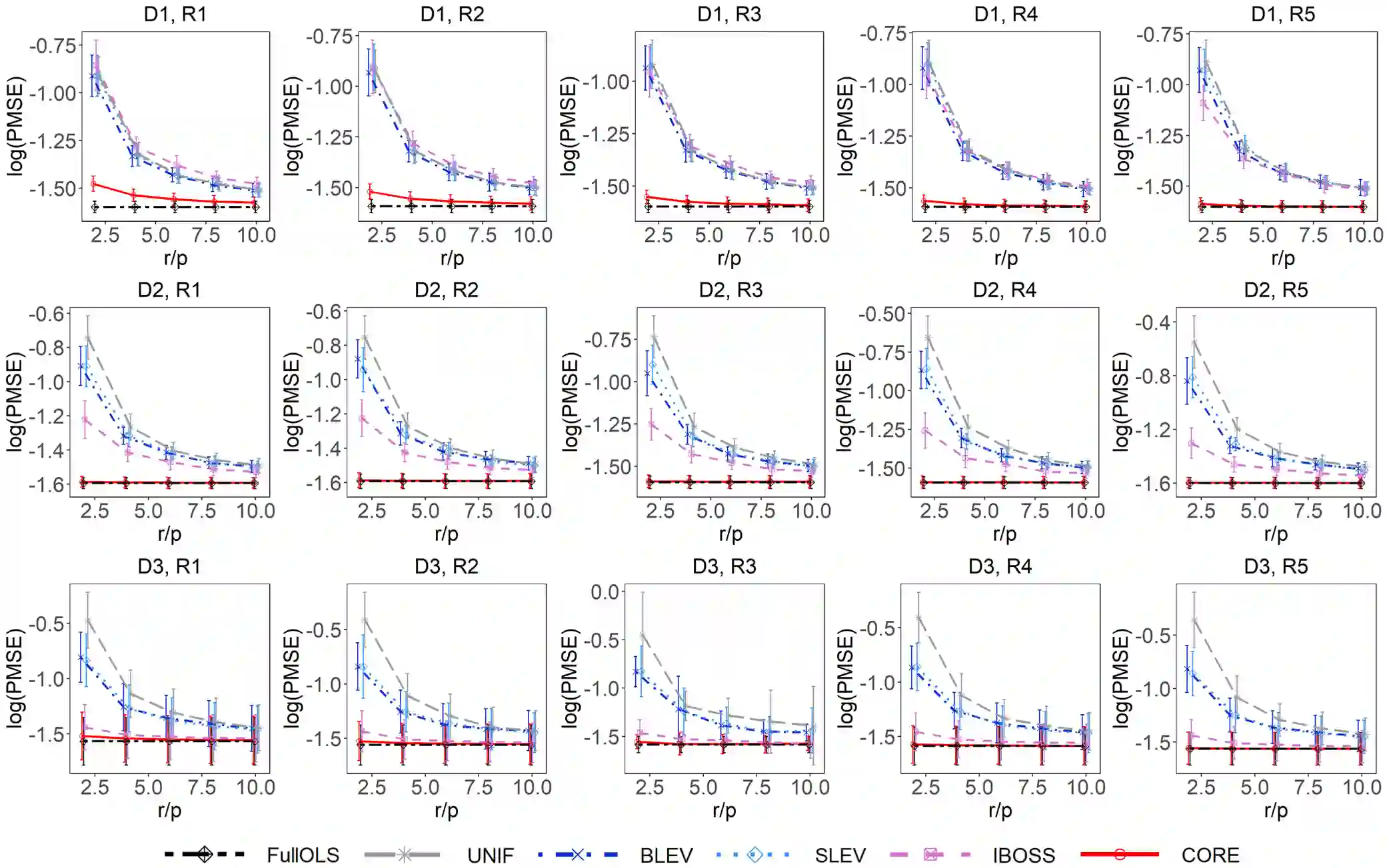
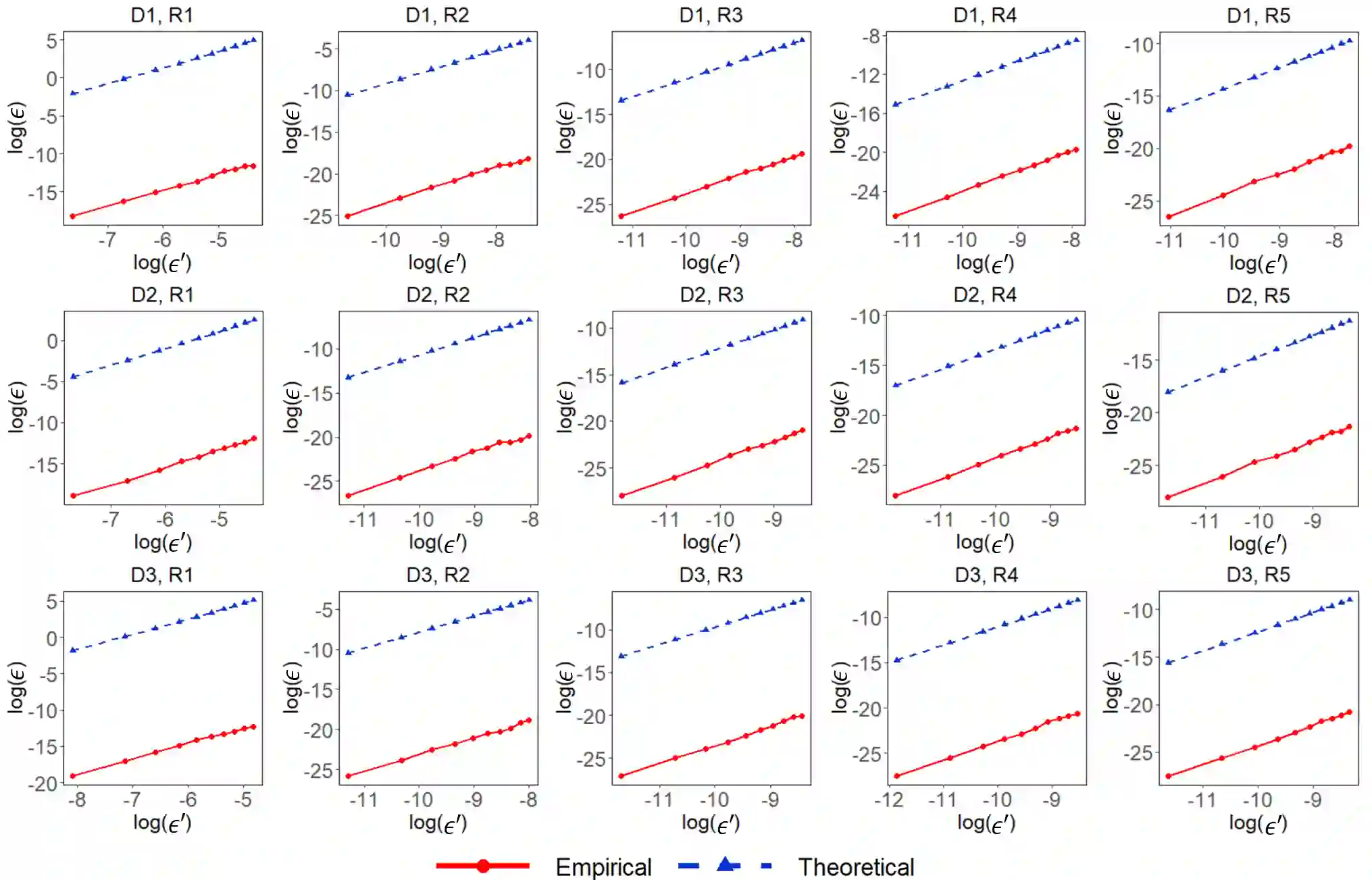
The coresets approach, also called subsampling or subset selection, aims to select a subsample as a surrogate for the observed sample. Such an approach has been used pervasively in large-scale data analysis. Existing coresets methods construct the subsample using a subset of rows from the predictor matrix. Such methods can be significantly inefficient when the predictor matrix is sparse or numerically sparse. To overcome the limitation, we develop a novel element-wise subset selection approach, called core-elements, for large-scale least squares estimation in classical linear regression. We provide a deterministic algorithm to construct the core-elements estimator, only requiring an $O(\mbox{nnz}(\mathbf{X})+rp^2)$ computational cost, where $\mathbf{X}$ is an $n\times p$ predictor matrix, $r$ is the number of elements selected from each column of $\mathbf{X}$, and $\mbox{nnz}(\cdot)$ denotes the number of non-zero elements. Theoretically, we show that the proposed estimator is unbiased and approximately minimizes an upper bound of the estimation variance. We also provide an approximation guarantee by deriving a coresets-like finite sample bound for the proposed estimator. To handle potential outliers in the data, we further combine core-elements with the median-of-means procedure, resulting in an efficient and robust estimator with theoretical consistency guarantees. Numerical studies on various synthetic and open-source datasets demonstrate the proposed method's superior performance compared to mainstream competitors.
翻译:核心集方法(又称子抽样或子集选择)旨在选取一个子样本作为观测样本的替代。该方法在大规模数据分析中得到了广泛应用。现有核心集方法通过从预测变量矩阵中抽取行子集来构建子样本,但当预测矩阵稀疏或数值稀疏时,此类方法的效率显著降低。为克服这一局限,我们提出一种新型元素级子集选择方法——核心元素法,用于经典线性回归中的大规模最小二乘估计。我们给出了一个确定性算法来构建核心元素估计量,其计算复杂度仅为$O(\mbox{nnz}(\mathbf{X})+rp^2)$,其中$\mathbf{X}$是$n\times p$的预测矩阵,$r$是从$\mathbf{X}$每列中选取的元素个数,$\mbox{nnz}(\cdot)$表示非零元素个数。理论上,我们证明该估计量无偏,且能近似最小化估计方差的上界。通过推导该估计量的核心集式有限样本界,我们进一步提供了近似保证。为处理数据中的潜在异常值,我们将核心元素法与均值中位数过程相结合,得到具有理论一致性保证的高效稳健估计量。在多种合成数据集和开源数据集上的数值实验表明,与主流对比方法相比,所提方法具有更优性能。