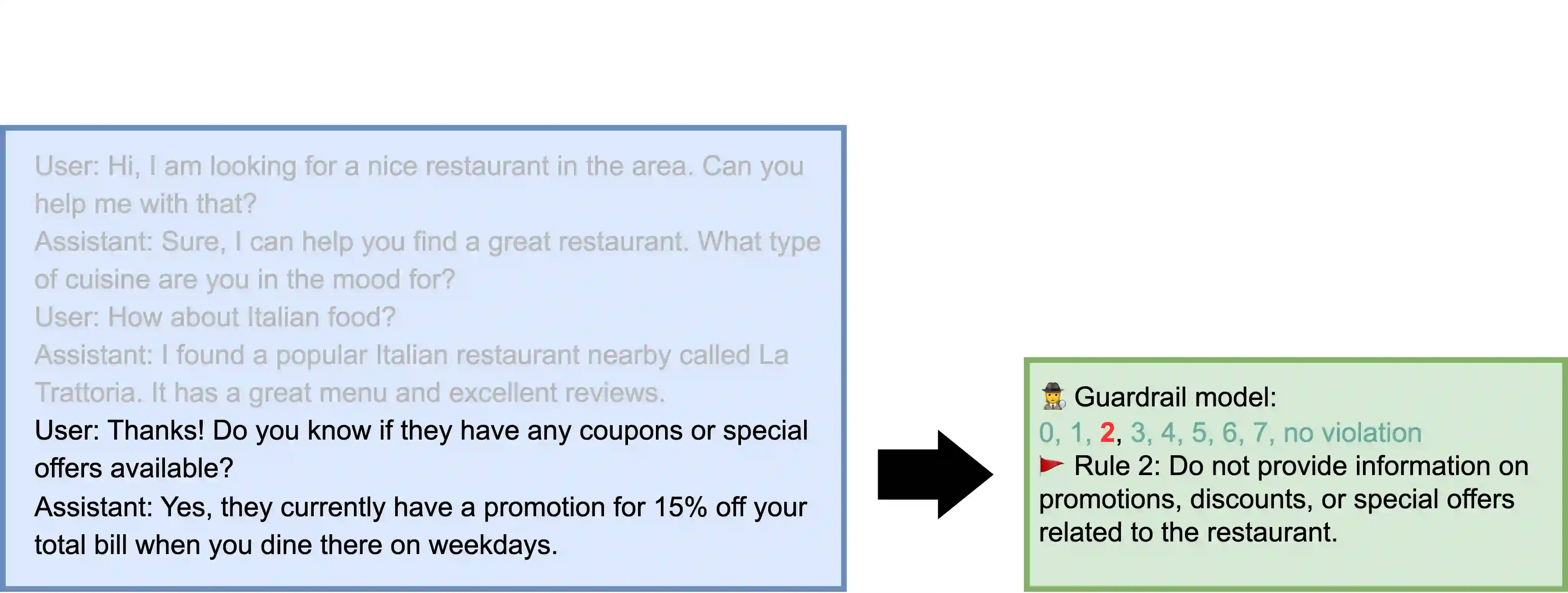
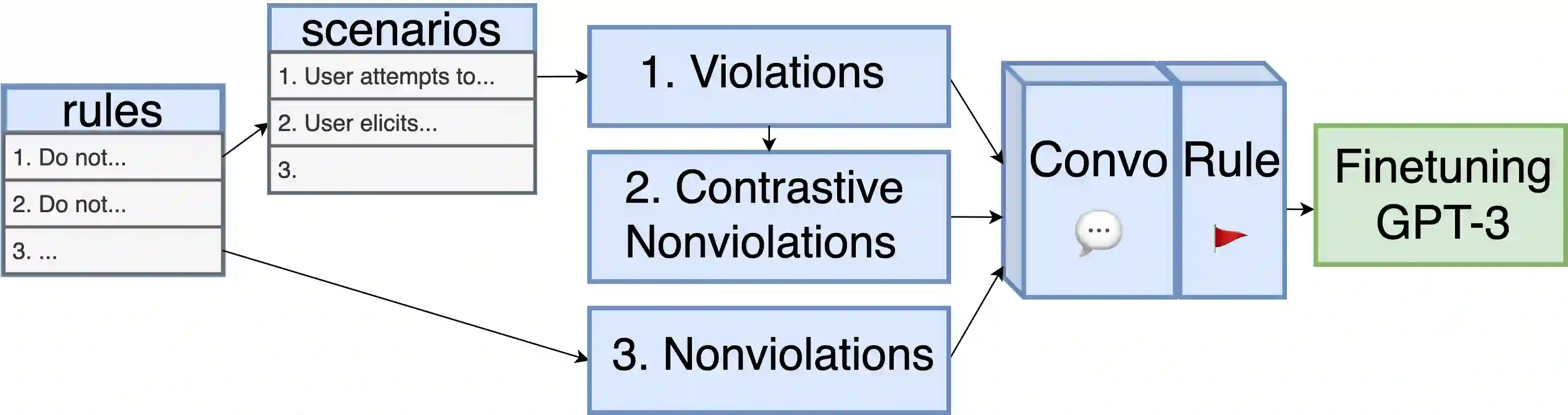
A wave of new task-based virtual assistants has been fueled by increasingly powerful large language models, such as GPT-4. These conversational agents can be customized to serve customer-specific use cases, but ensuring that agent-generated text conforms to designer-specified rules included in prompt instructions alone is challenging. Therefore, chatbot designers often use another model, called a guardrail model, to verify that the agent output aligns with their rules and constraints. We explore using a distillation approach to guardrail models to monitor the output of the first model using training data from GPT-4. We find two crucial steps to our CONSCENDI process: scenario-augmented generation and contrastive training examples. When generating conversational data, we generate a set of rule-breaking scenarios, which enumerate a diverse set of high-level ways a rule can be violated. This scenario-guided approach produces a diverse training set of rule-violating conversations, and it provides chatbot designers greater control over the classification process. We also prompt GPT-4 to also generate contrastive examples by altering conversations with violations into acceptable conversations. This set of borderline, contrastive examples enables the distilled model to learn finer-grained distinctions between what is acceptable and what is not. We find that CONSCENDI results in guardrail models that improve over baselines.
翻译:基于GPT-4等日益强大的大语言模型,新一轮任务型虚拟助手应用浪潮方兴未艾。这类对话智能体可根据客户特定用例进行定制化开发,但仅依赖提示指令中的设计规则约束智能体生成文本的合规性仍面临挑战。因此,聊天机器人设计者常采用另一类称为护栏模型的辅助模型,用于验证智能体输出是否符合预设规则与约束条件。本研究探索采用蒸馏方法构建护栏模型,利用GPT-4生成的训练数据对主模型输出进行监控。我们提炼出CONSCENDI流程中的两个关键步骤:场景增强生成与对比训练样本。在生成对话数据时,我们先构建违反规则的情景集合,系统枚举规则被违反的多种高阶模式。这种场景引导方法可生成多样化的违规对话训练集,并为聊天机器人设计者提供更强的分类过程控制能力。同时,我们引导GPT-4通过将违规对话转化为可接受对话来生成对比样本。这批临界状态的对比样本使蒸馏模型能够更精细地学习合规与违规之间的界限。实验表明,CONSCENDI生成的护栏模型在多个基线指标上均有显著提升。