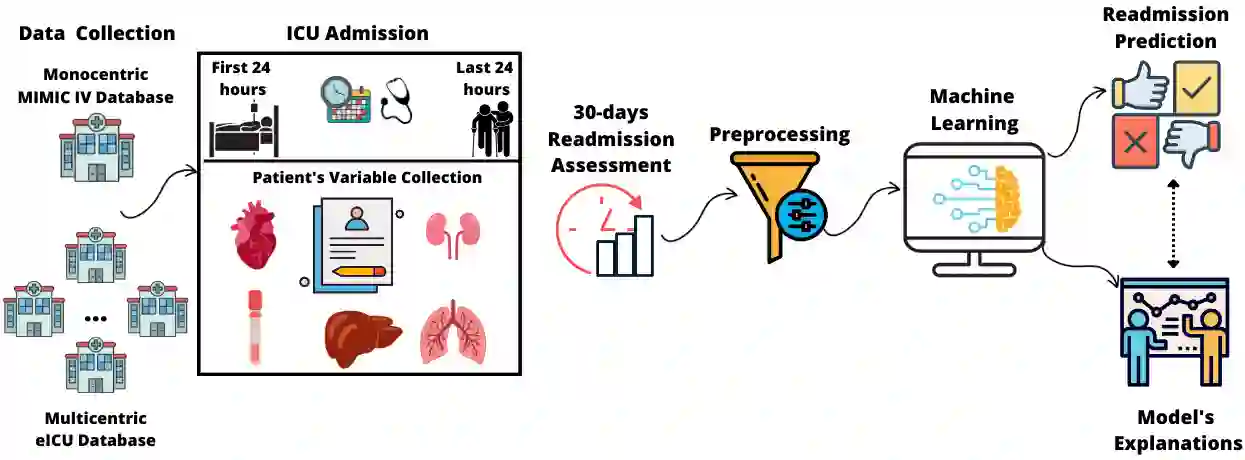
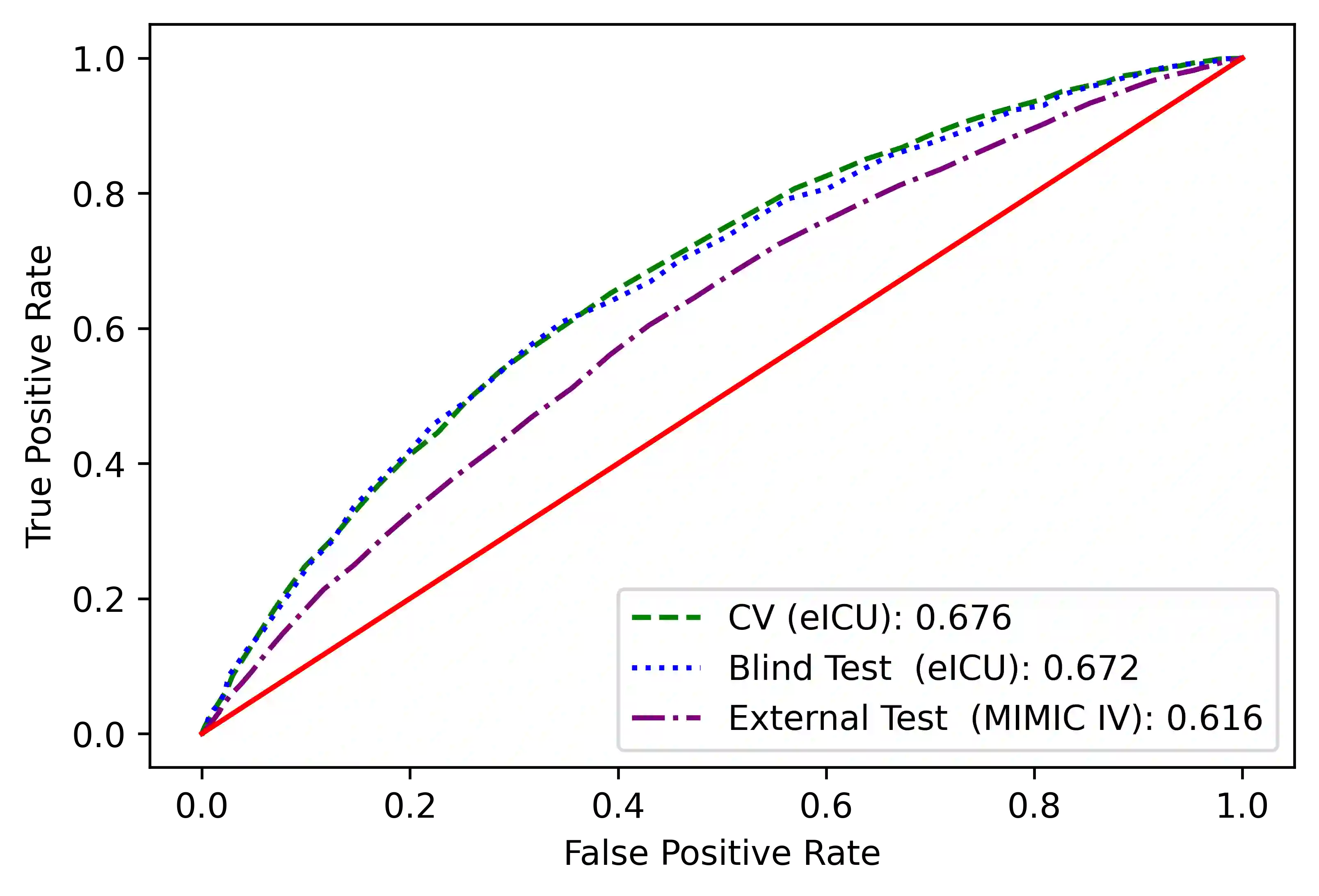
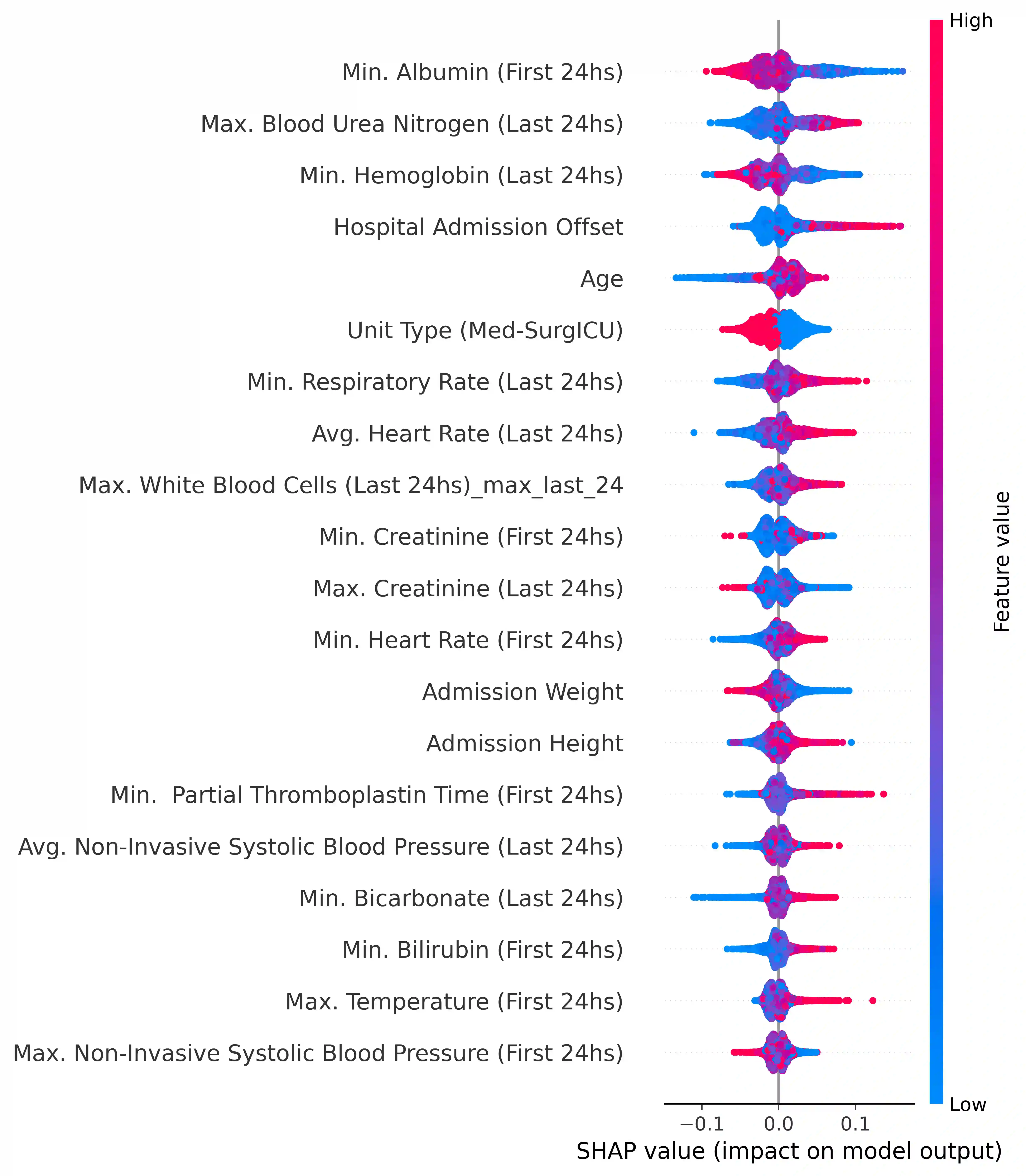
The intensive care unit (ICU) comprises a complex hospital environment, where decisions made by clinicians have a high level of risk for the patients' lives. A comprehensive care pathway must then be followed to reduce p complications. Uncertain, competing and unplanned aspects within this environment increase the difficulty in uniformly implementing the care pathway. Readmission contributes to this pathway's difficulty, occurring when patients are admitted again to the ICU in a short timeframe, resulting in high mortality rates and high resource utilisation. Several works have tried to predict readmission through patients' medical information. Although they have some level of success while predicting readmission, those works do not properly assess, characterise and understand readmission prediction. This work proposes a standardised and explainable machine learning pipeline to model patient readmission on a multicentric database (i.e., the eICU cohort with 166,355 patients, 200,859 admissions and 6,021 readmissions) while validating it on monocentric (i.e., the MIMIC IV cohort with 382,278 patients, 523,740 admissions and 5,984 readmissions) and multicentric settings. Our machine learning pipeline achieved predictive performance in terms of the area of the receiver operating characteristic curve (AUC) up to 0.7 with a Random Forest classification model, yielding an overall good calibration and consistency on validation sets. From explanations provided by the constructed models, we could also derive a set of insightful conclusions, primarily on variables related to vital signs and blood tests (e.g., albumin, blood urea nitrogen and hemoglobin levels), demographics (e.g., age, and admission height and weight), and ICU-associated variables (e.g., unit type). These insights provide an invaluable source of information during clinicians' decision-making while discharging ICU patients.
翻译:重症监护病房(ICU)构成复杂的医院环境,临床医生的决策对患者生命具有高风险性。必须遵循全面的护理路径以减少并发症。该环境中存在的不确定性、竞争性和计划外因素增加了护理路径统一实施的难度。当患者在短时间内再次入住ICU时,再入院现象会加剧护理路径的复杂性,导致高死亡率和资源消耗。已有研究尝试通过患者医疗信息预测再入院。尽管这些研究在预测再入院方面取得了一定成效,但未能充分评估、刻画和理解再入院预测机制。本研究提出标准化可解释机器学习流程,在多中心数据库(即包含166,355名患者、200,859次入院和6,021次再入院的eICU队列)上建模患者再入院,并在单中心(即包含382,278名患者、523,740次入院和5,984次再入院的MIMIC IV队列)与多中心场景中验证该流程。我们的机器学习流程采用随机森林分类模型,在受试者工作特征曲线下面积(AUC)指标上达到0.7的预测性能,在验证集上展现出良好的整体校准度和一致性。通过构建模型提供的解释,我们得出了一系列深刻结论,主要涉及生命体征与血液检测相关变量(如白蛋白、血尿素氮和血红蛋白水平)、人口学特征(如年龄、入院身高和体重)以及ICU相关变量(如病房类型)。这些洞察为临床医生决策ICU患者出院时机提供了宝贵的信息源。