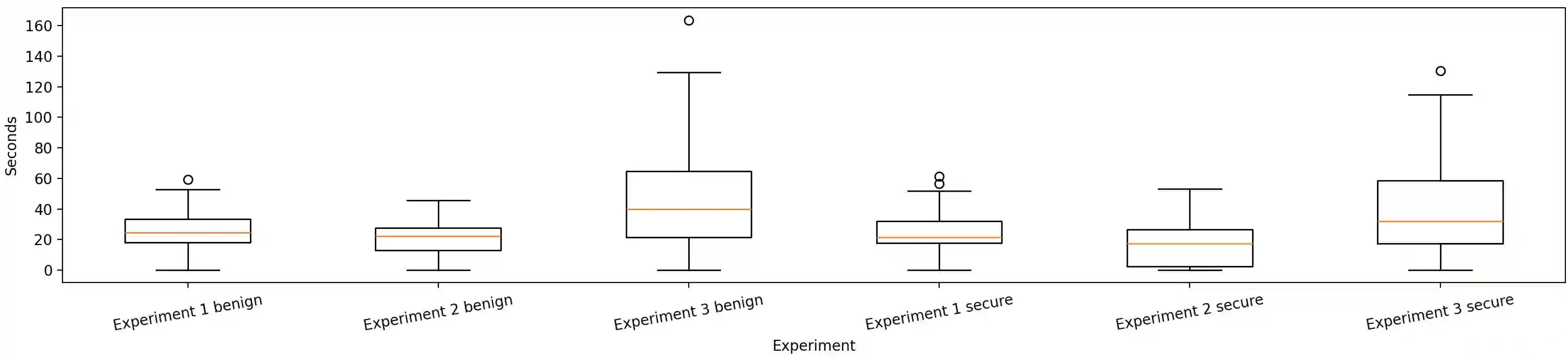
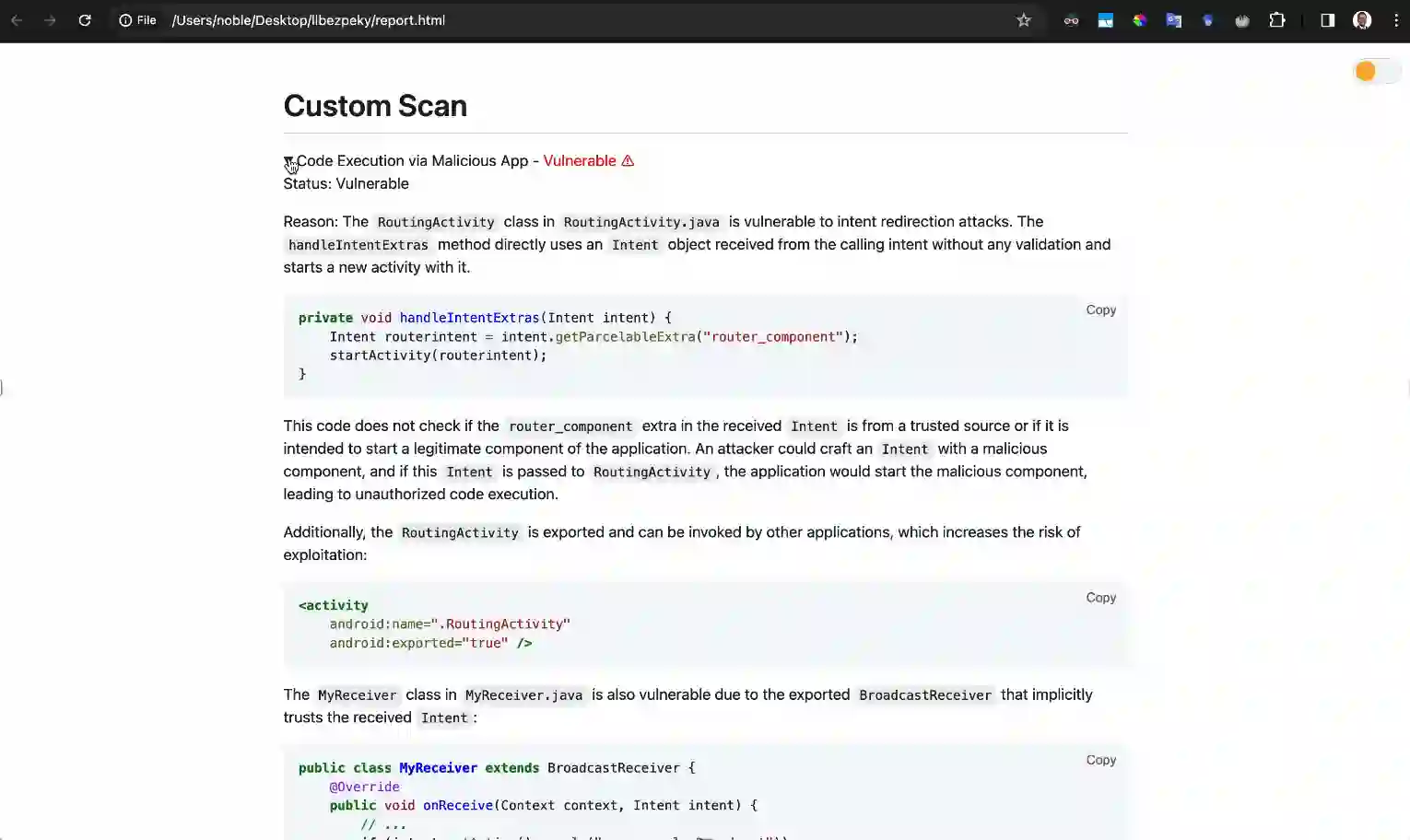
Despite the continued research and progress in building secure systems, Android applications continue to be ridden with vulnerabilities, necessitating effective detection methods. Current strategies involving static and dynamic analysis tools come with limitations like overwhelming number of false positives and limited scope of analysis which make either difficult to adopt. Over the past years, machine learning based approaches have been extensively explored for vulnerability detection, but its real-world applicability is constrained by data requirements and feature engineering challenges. Large Language Models (LLMs), with their vast parameters, have shown tremendous potential in understanding semnatics in human as well as programming languages. We dive into the efficacy of LLMs for detecting vulnerabilities in the context of Android security. We focus on building an AI-driven workflow to assist developers in identifying and rectifying vulnerabilities. Our experiments show that LLMs outperform our expectations in finding issues within applications correctly flagging insecure apps in 91.67% of cases in the Ghera benchmark. We use inferences from our experiments towards building a robust and actionable vulnerability detection system and demonstrate its effectiveness. Our experiments also shed light on how different various simple configurations can affect the True Positive (TP) and False Positive (FP) rates.
翻译:尽管在构建安全系统方面持续研究并取得进展,Android应用程序仍普遍存在漏洞,亟需有效的检测方法。当前涉及静态和动态分析工具的策略存在局限性,例如误报数量过多以及分析范围有限,这导致这些方法难以被广泛采用。过去几年,基于机器学习的方法在漏洞检测领域得到了广泛探索,但其实际应用性受到数据需求和特征工程挑战的制约。大型语言模型(LLMs)凭借其庞大的参数规模,在理解人类语言和编程语言语义方面展现出巨大潜力。我们深入探究了LLMs在Android安全背景下检测漏洞的有效性。我们专注于构建一个AI驱动的工作流程,以协助开发者识别和修复漏洞。实验结果表明,LLMs在发现应用程序中的问题方面表现超出预期,在Ghera基准测试中正确标记不安全应用程序的比例达到91.67%。我们利用实验中的推断,构建了一个稳健且可操作的漏洞检测系统,并验证了其有效性。我们的实验还揭示了不同简单配置如何影响真阳性(TP)率和假阳性(FP)率。